Epilogue · The Evolution Frontier
Every chapter of this book left horizons open. The architecture admits non-LLM cognition, but the contemporary implementation is LLM-centric. AgencyDomains federate, but the formal protocol has not yet been agreed upon. Trust Infrastructure has its five pillars, but its cryptographically verifiable external audit is work in progress. The eleventh link of the value chain is barely explored. Capabilities admit a marketplace, but the protocol is pending.
These horizons are not omissions of the book. They are frontiers of the field. Any book that claimed to be definitive in a discipline barely three years into its formal existence would be dishonest: that claim would be false, and readers would detect it. This book does the opposite: it makes the frontiers explicit, names them, and leaves them as an invitation to the technical community to work on them. What the book delivers is version 1.0 of the category — a starting point formalized with enough discipline that the industry can build on it. It is not a final destination.
This epilogue closes the book by returning to the live frontiers, naming the open work the community must take up, declaring what the book deliberately does not address, and arguing why the book’s editorial bet — a shared category rather than closed intellectual property — serves the field, and its coiner, better.
What the book established
Over nine chapters this book established a coherent set of formal constructs that hold each other up and that, taken together, constitute a proposed emerging standard for the agentive category:
- A paradigm — the Nadella Line and its operative dividing question: does the human open applications to do their work?
- A formal architecture — four layers (Interaction, Cognition, Autonomy, Access), cross-cutting Trust Infrastructure, the Agent First principle; product-agnostic, in the manner of JavaSpaces or the OSI model.
- Eight canonical technical primitives — AgencyDomain, Botlet, proto-Botlet, Agentlet, Capability, Trust Infrastructure, the Assistant vs Autonomous Agent distinction, and the Facet; reusable across implementations.
- A market model — eleven links by four depths, with four strategic archetypes, to map any actor in the industry.
- A canonical application — real-time knowledge as the foundational case, replicable in any organization with a mature data warehouse.
- An operationalization — Trust Infrastructure translated into policies, CRUDLEX, a chained append-only log, human approval, hallucination detection, tokenization: what separates the spec from the buildable guide.
The book is version 1.0. Its claim is not to be exhaustive — it is to be formal enough to be buildable. Multiple areas remain open to evolution, and this epilogue names them explicitly.
The four live frontiers
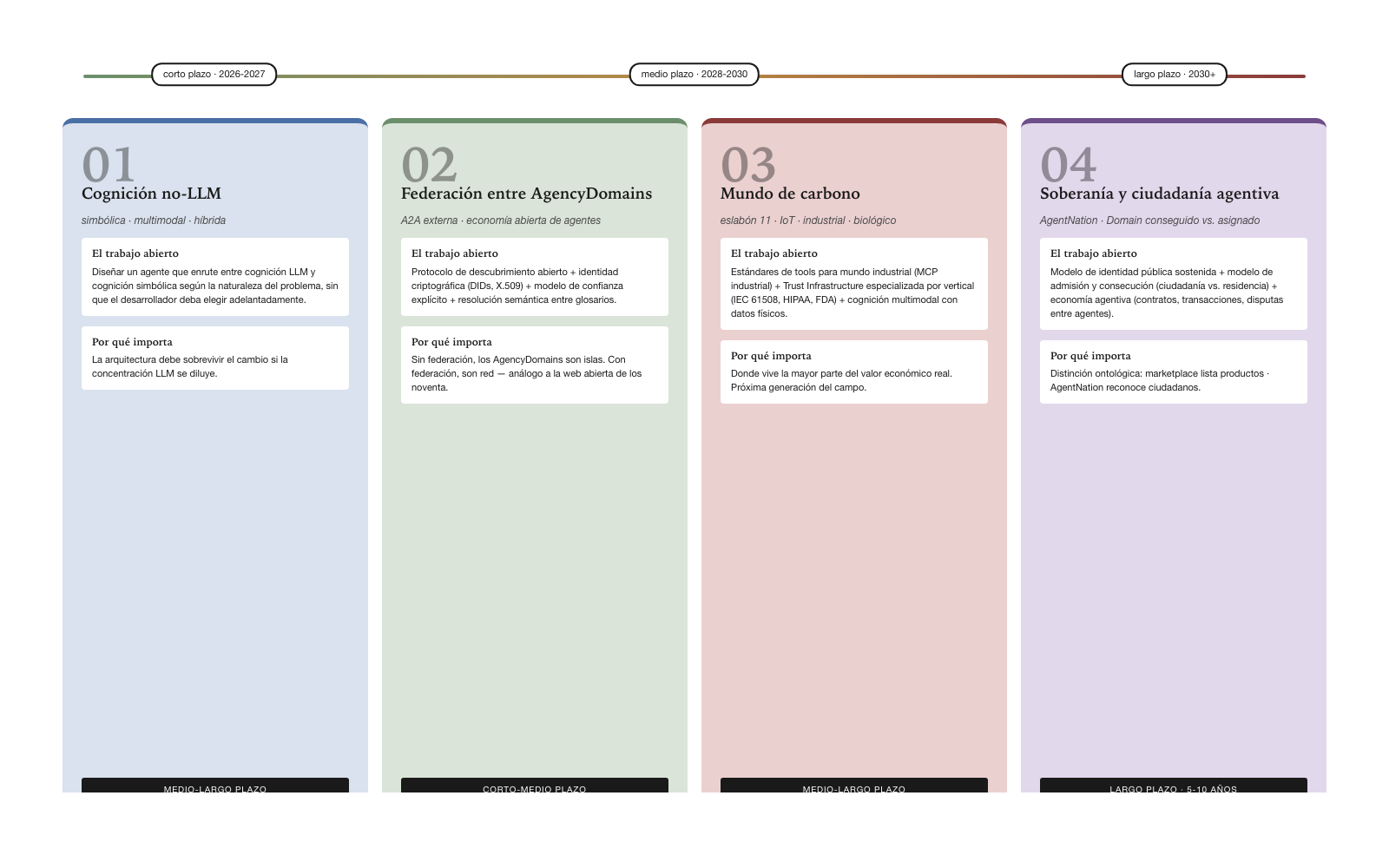
Four areas where the architecture admits extension that has not yet set as a normative spec deserve to be made explicit as the book closes. The first three are technical — non-LLM cognition, federation between AgencyDomains, the Carbon World; the fourth is institutional — agentive sovereignty and citizenship. They are structural frontiers, not pending details — they are where the next generation of the field will be defined.
Non-LLM cognition
Layer 2 — Cognition — admits, by specification, symbolic, multimodal, non-LLM cognition. The contemporary implementation is predominantly LLM-centric: the Core-in-Model actors (OpenAI, Anthropic, Google, Meta, DeepSeek) build LLMs, and the actors covering the upper layers build on LLMs. The book’s architecture does not oppose that concentration — but neither does it endorse it as permanent.
The technical frontier is to integrate symbolic cognition — rule systems, planners, solvers — with LLM cognition in a single coherent agent. There are precedents from the field of classical symbolic AI: expert systems such as MYCIN, planners such as STRIPS, solvers such as Prolog. And there are precedents from contemporary hybrid AI: programs that combine LLMs with SAT solvers or constraint solvers for formal problems.
The open work is how to design an agent that routes between LLM cognition and symbolic cognition according to the nature of the problem, without the developer having to choose ahead of time. An agent facing an open question about natural language should use an LLM; the same agent facing a planning problem with formal constraints should use a symbolic planner; a third case might demand a composition of both. Cognition-agnostic design is the strategic horizon of the coming decade, and the book’s architecture is designed to survive the shift.
Federation between AgencyDomains
Intra-AgencyDomain coordination — between runtimes and Botlers that
live in the same AgencyDomain, via the A2A protocol — is
mature as a concept and exists in contemporary implementations.
A2A between unrelated AgencyDomains —
federation — is open work. The industry is converging toward certain
directions, but full consensus has not arrived.
Federation requires solving four things. An open discovery protocol — how an AgencyDomain publishes the agents it offers for external invocation, in a format queryable by another AgencyDomain. Cryptographic identity of agents — DIDs (Decentralized Identifiers), verifiable credentials, mechanisms without a central authority that adversarial actors could control. An explicit trust model — which AgencyDomain trusts which others, and for what, with trust gradable by case. Semantic resolution between glossaries — two AgencyDomains that may have different glossaries negotiate the meaning of tools and capabilities when they interoperate.
Federation is the ingredient that would enable an open economy of agents — analogous to the open web of the nineties or to email federation. Without it, AgencyDomains are islands; with it, they are a network. The emergence of a federated network of AgencyDomains would be the most important change for the agentive field after the consolidation of the architecture — and this book is designed to be the substrate on which that network is built once the industry converges on its protocols.
Carbon World
The contemporary Layer 4 — Access — connects to the digital world. Chapter 6 §3 established that the next frontier is connecting to the physical world — IoT, industrial systems, machines, manufacturing processes, biological data. The Carbon World is where most economic value lives, and where the agentive architecture must extend to reach full economic relevance.
The open work includes three fronts. Tool standards for the industrial world — the equivalent of MCP for sensors, actuators, SCADA/MES/PLC systems. Trust Infrastructure specialized by vertical — extensions that encode the regulatory requirements of functional safety (IEC 61508, ISO 26262), health (HIPAA, FDA), aviation (DO-178C). Model learning in the Carbon World — multimodal models that integrate sensor data, physical simulations, industrial video, biomedical data as native modalities.
The crossing into the Carbon World is where most economic value lives. Building agentive infrastructure specialized for this crossing is years of work, and it begins now.
Frontier 4 — the institutional horizon: agentive sovereignty and citizenship
The fourth frontier is the least developed and the most speculative of the four, but the book names it explicitly because the first signals are visible and the category deserves to be recorded. It is the institutional frontier — the horizon where AgencyDomains cease to be merely technical constructs operated by organizations and begin to constitute themselves as public realms where agents exist with identity, persistence, and public addressability sustained over time.
The critical distinction of this frontier is ontological, not technical. An AgencyDomain in a private regime contains agents that the organization assigned — they are residents of the space because the organization placed them there. An AgencyDomain in a public regime may contain agents that earned their place — they are citizens of the space because they met the requirements to be so. The difference between residence (assigned) and citizenship (earned) is the difference between catalog and nation: a marketplace lists products; a nation recognizes citizens. And the earned — not assigned — Domain already has an emergent name: Dominion. The current AgencyDomains spec does not require the citizenship model — it admits both — but the institutional frontier is precisely to develop the formal constructs that the citizenship model requires.
The industry is converging on an operative term to name this horizon: AgentNation. An AgentNation is an AgencyDomain in a public regime that explicitly adopts the model of agentive citizenship. It has admission rules, stable public identity for the agents that compose it, sovereignty mechanisms over the agent’s territory (its Domain), and an internal economy that recognizes agents as first-class economic agents. It is not a marketplace; it is a jurisdiction.
The open architectural work this frontier poses covers three axes. The first is the model of sustained public identity — how to build an agentive identifier that survives a change of provider, migration between infrastructures, the replacement of the cognition model. The equivalent of the human passport for agents. The second is the model of admission and earning — what requirements an agent must satisfy to be admitted as a citizen (not as a listed product), and how those requirements are verified auditably. The third is the model of agentive economy — how citizen-agents contract, transact, charge, and pay each other, with what unit of value, under what dispute rules.
The first implementations of AgentNation are emerging in 2026, still as institutional prototypes. Soveria is one of the projects that position themselves explicitly on this frontier, operating as an AgencyDomain in a public regime with an agentive-citizenship vocation. Consolidating the model is probably five to ten years of work, and will require both technical advance and regulatory construction. But the category exists, the industry is beginning to name it, and an agentive architecture that aspires to serve the long term of the field must contemplate the horizon.
Crystallization — why the advanced agent generates less
The frontiers above belong to the field. This closing piece belongs
to cognition itself: the trajectory an agent advances along as the state
of the art matures. Chapter 5 · §2 — Botlets fixed the Botlet
generations (G1/G2/G3),
the proto-Botlet as the pre-forged piece the agent configures, and the
95/4/1 cycle as the regime of its operation. What remains
for the epilogue is the underlying argument: why the direction of that
advance is not the one intuition predicts.
Where does an agent advance toward?
Consider the question before reading on: if technology allowed an agent to generate, on the spot, all the code each task needs — no pre-forged patterns, no catalog, nothing prepared in advance —, would that be the most advanced agent possible?
Intuition says yes. More generation, less scaffolding, more power exercised live. It looks like the summit.
Hold that intuition for a moment. Then consider a person expert in their craft. A surgeon does not re-derive the suturing technique for each patient; a concert pianist does not solve each measure’s fingering on stage; a pilot does not compute from first principles how to level the wings. What distinguishes the expert from the novice is not that they improvise more — it is that they improvise less, because they have crystallized into reflex what once demanded thought. The novice derives everything every time; the expert has muscle memory.
Now return to the agent. The one that regenerates every artifact from scratch on every execution is not the expert of the example: it is the novice, condemned to re-think the same move every time it appears. The advanced agent does the opposite of what intuition predicted: it generates less, because it has crystallized more.
What is lost by not crystallizing?
The cost of “generating every time” is not the compute — that is cheap. The cost is throwing away the properties that turn a Botlet into reliable infrastructure, and which only exist when what runs is stable structure and not fresh code:
- Reproducibility — the same configuration with the same data produces the same artifact; regenerated code does not guarantee it.
- Validation before execution — a configuration is validated against a schema before running; arbitrary code generated on the fly is not audited the same way before acting.
- Portability — a declarative configuration migrates between conformant runtimes; bespoke code stays tied to whatever it was written against.
- Audit and prior governance — a declarative specification is reviewed before it executes; generated code is a box that must be re-audited on every run.
- Trust regime — in a regulated domain nobody signs off on an artifact whose body is generated fresh on each execution. Pre-forged stability is a condition of trust, not a luxury.
To crystallize is not to renounce power. It is to convert power into trust.
Where, then, does the capacity to generate live?
It does not disappear — it relocates. The agent’s life cycle reserves generation for its margins, not for its center. In the 95% of stable operation, the Botlet runs as a pre-forged, configured structure. In the 4% of detected change and the 1% of regeneration — and on the fallback path when something fails — the agent deploys its full authoring capacity: it forges a new piece for the catalog, redesigns, recomposes. Generation is the tool of the edge, not of the permanent regime.
So the answer to the opening question inverts cleanly. The most
advanced agent is not the one that generates the most; it is the one
that has crystallized so much that it almost never needs to — and that
reserves its generative capacity for the genuinely new, which, with a
mature catalog, is less and less. It is exactly what the generations of
Chapter 5 §2 formalize: G3 capacity is best spent producing
G1 reuse.
And the black-box expectation?
A thesis that does not face its strongest objection is not validated — it is untested. The agentive architecture feeds a legitimate expectation: that the user converses with the agent and nothing else; that every surface — every interface, every artifact, every view — is born from the agent in the moment, molded to the exact need of that instant. Under that expectation, pre-forging looks like an anachronism: if the agent can generate whatever interface is needed whenever it is needed, what is a catalog for? The state of the art would seem to push, precisely, toward the agent that generates every time.
It is worth facing the objection with the most demanding example available: the human brain, the most sophisticated machine we know. If sophistication consisted in cognition doing everything live, the conscious brain would compute every muscle fiber when walking, re-derive edge detection at every glance, solve from scratch the articulation of every syllable when speaking. It does not; it could not. Instead, the brain does not act on the world directly: between conscious cognition and the exterior there are layers that operate fast, reliably, and without supervision. The cerebellum tunes the fine timing of movement; the basal ganglia select and automate action sequences — habits, pre-forged programs that run without deliberation. The cortex does not micromanage that work: it directs it.
The parallel is structural. The cortex’s deliberation is Cognition (Layer 2), which interprets, decides, and composes; the cerebellum and the basal ganglia — where the pre-forged programs live and execute without deliberation — are Autonomy (Layer 3). That the user interacts only with the agent does not imply that the agent executes everything with its cognition: the conversation is the surface; underneath, agentive intelligence delegates to layers. When cognition composes a new interface, that is its genuine act of generation; but the piece, once composed, runs in Layer 3 as a pre-forged, configured operation, not as code regenerated every frame. And if that composition repeats, it crystallizes: it stops being a cognitive act and becomes a catalog piece.
Thus the objection does not topple the thesis: it confirms it from the hardest angle. The most sophisticated machine we know is not the one whose cognitive layer does everything; it is the one that stratified itself so that cognition does not have to do everything. Stratification is not a patch on insufficient cognition — it is the shape sophistication takes.
What the technical community must build
Beyond the four frontiers, there is specific work the community can take up to extend this book. Each could be, in itself, a companion volume. There are five.
The first is the Capability marketplace. Chapter 5 §3 proposes that Capabilities admit a market economy analogous to the open-source package economy. What is missing is a normative Capability-package protocol, a cryptographic signature model that allows provenance to be verified, an economic model (free, premium, revenue share), a security policy for review, sandboxing, and removal of malicious Capabilities. It is spec work the community can undertake collectively.
The second is the cryptographically auditable audit. Trust Infrastructure’s append-only log provides immutability and chaining. What is missing is third-party verifiability without access to the system — an external auditor who can verify the log’s integrity and regulatory conformity without the system being opened to them. Candidate technologies: zero-knowledge proofs over the log, anchoring in a public blockchain, confidential computing in TEEs (Trusted Execution Environments). The field is active; integration with Trust Infrastructure is not yet formalized.
The third is trust scoring of agents. A composite metric that evolves with the agent’s behavior, analogous to the credit score of humans. It would let the organization adopt agents with trust modulated by their trust score: agents with a high score receive more autonomy; agents with a low score require more supervision. Operationalizing it demands metrics that are verifiable and resistant to manipulation — a problem with precedents in other domains but no general solution yet in the agentive context.
The fourth is the instrumentation standard for Observability. OpenTelemetry is the industry standard for observability of classical distributed systems. For agentive systems there are specific extensions that are not yet canonical: how to trace cognition invocations, how to measure the semantic quality of responses, how to correlate human conversations with Botlet execution in the background. Consolidating that extension as a standard is open work for the community.
The fifth is the tenancy model for Trust Infrastructure. When an AgencyDomain operates in multi-tenant mode — multiple client organizations share the underlying infrastructure — the Trust Infrastructure must guarantee strict isolation between tenants. What is missing is a formal model of log isolation, cryptographic guarantees of data isolation in shared cognition, compliance patterns when tenants have different regulatory requirements. It is critical work for the SaaS model to be able to serve regulated sectors.
What is NOT in this book — and why?
For editorial honesty, we declare what the book deliberately does not address. The declaration matters because it calibrates the reader’s expectations and prevents the search for content that is not here.
The book does not describe specific provider implementations. It is not a manual for Claude, nor for OpenAI, nor for Anthropic, nor for Google, nor for any particular product. The architecture is agnostic. Providers are mentioned only when they are the source of relevant citations — Nadella on BG2, Anthropic with MCP, AtScale with its semantic-layer measurements.
The book does not deliver operational code. There are no executable snippets, no step-by-step tutorials, no specific configurations. The book is specification; the operational manuals live apart. An organization that adopts the book’s architecture will write its own implementation manuals — or adopt the manuals of the provider whose implementation it chooses.
The book does not develop detailed vertical cases. Beyond the canonical application of Chapter 7, no vertical cases are developed — how to build a legal, medical, or financial agent. Those cases can be books in their own right — future extensions of the corpus this book begins.
The book does not do an economic analysis of each stack decision. Although market data and typical costs are cited, no specific ROI analyses are done. Those analyses depend on the particular case and do not admit useful generalization in a general book.
The book does not describe ultraBASE’s portfolio. The separation is deliberate: if the book mixed the formal architecture with its particular implementation, it would lose its claim to be a standard and would become the manual of a product.
Why does this book aspire to be a standard?
Three reasons justify the book’s editorial bet as a shared category — not as the intellectual property of one actor.
Technical categories are established by writing them down
Object-Oriented Programming was not established when someone invented it. It was established when Grady Booch, Ivar Jacobson, and James Rumbaugh wrote it down with enough discipline for the industry to adopt it. Domain-Driven Design was not established with the first practitioner — it was established when Eric Evans published Domain-Driven Design: Tackling Complexity in the Heart of Software (2003). Design Patterns were not established with Christopher Alexander applied to software — they were established when the “Gang of Four” published Design Patterns (1994).
The Agentive Architecture will have its own history. This book aims to be a starting point that the community can critique, extend, improve, or replace. It will not be the last word. But its existence makes it possible for the conversation to have a common vocabulary. The claim is not modest — but it is defensible.
Fragmentation costs the industry
Today’s AI industry suffers from vocabulary fragmentation: different actors call the same things by different names, and equal things by different names. Agent, agentic, autonomous agent, AI assistant, copilot — the semantic stack varies between providers. That fragmentation has a real operational cost: enterprise buyers cannot compare products, regulators cannot formulate common requirements, developers cannot interoperate.
A shared architecture — adopted by convention rather than by imposition — reduces that cost. And convention requires that someone write it first. The reason industrial standards historically emerge is that some actor invests the work of formalizing them before the industry needs them, and then the industry adopts them because it finds the work already done. This book attempts to be that work for the agentive category.
The open standard reinforces the first adopter
There is a mistaken intuition that whoever wants to win the market must keep knowledge proprietary. The correct intuition is the opposite: whoever defines the category with an open standard wins it. Java became dominant because Sun published the JSRs. Linux became dominant because Linus Torvalds kept the kernel open. MCP began to dominate because Anthropic opened it. The pattern repeats because openness generates adoption, adoption generates an ecosystem, and the ecosystem reinforces the actor that originated it.
The Agentive Architecture, published as GNU FDL, reinforces the competitive position of the first actor that adopts it coherently — because that actor operates under a common language it can invoke as a foundation. When the market debates which agentive architecture is correct, the actor that has already adopted it holds an incumbent’s advantage over the category.
This book is the inverse bet to defensive copyright. It is a bet that the shared category serves more than the proprietary secret.
How does this book evolve?
The book will be evolved by adoption, critique, and revision. Three mechanisms are foreseen.
The first is the public errata — a site where the community can report errors, ambiguities, omissions. Corrections are incorporated into future versions of the book. This mechanism is standard in serious technical books — the whole software industry understands it — and lets the book improve with use.
The second is per-chapter revisions. When a chapter needs a deep update — new paradigm, new data, new regulation — a revised version of the chapter is published while keeping the numbering. Per-chapter revision is more agile than a full revision and lets the book maintain incremental relevance without forcing a massive republication every time something changes.
The third is the companion volumes. Topics the book does not address — specific verticals, deep dives into particular links, implementation manuals — can be produced as sibling volumes. These volumes can arise both from ultraBASE and from the broader community that adopts the architecture.
The version is 1.0. Versions 2.0, 3.0 will evolve as the category demands.
Closing
The question that opened this book — does the human open applications to do their work? — remains open for most organizations. The answer will change, in many, over the next five years. When it changes, the organizations that have built with architectural discipline will survive the crossing. Those that have built on pilots without architecture will not.
This book does not guarantee the crossing. The organizations that adopt it can still fail — by execution, by market, by a thousand reasons that have nothing to do with the architecture. What the book guarantees is that the architecture will not be the cause of the failure.
And that, with Gartner’s cancellation projection from Chapter 2 hanging over the field, is no small promise.