Chapter 7 · Real-time knowledge
There is a problem that almost any serious executive at a mid-sized or large company recognizes at once when it is described: the insufferable slowness of access to knowledge about their own business. The executive has an intuition about something that is happening — margins seem to be falling, churn seems to be rising, one region seems to be behaving differently from the others —, puts the question to their BI team, and the answer arrives somewhere between two and eight weeks later. By then, the decision that prompted the question has already passed. The organization ended up operating on the unverified intuition.
This chapter is about the first use case that demonstrates, with clear metrics, the value of crossing the Nadella Line. It is the case where the difference between the Agentic World and the Agentive World stops being abstraction and becomes experienceable: a question that took weeks to produce an answer takes seconds in the Agentive World. The transformation is not merely quantitative — it is qualitative: when asking is free, organizations discover that they can ask things that were never asked before, and they discover that the unasked questions held the most valuable insights.
A formal architecture remains incomplete without a canonical case that demonstrates it. For the Agentive Architecture, that case is access to analytical information — the most everyday and best understood problem of modern enterprise operation. Three reasons make the case foundational for the book.
The first reason is that it is universal. Every organization that operates with data faces the problem of turning data into decisions. Conversational BI applies to finance, operations, sales, marketing, human resources — without distinction. The sector does not matter, the size does not matter, the geography does not matter: the problem exists everywhere and takes a similar shape.
The second reason is that it has a clear metric. The value is measured in time: how long a business question takes to become an actionable answer. The difference between weeks and seconds requires no argument — it is directly perceptible. When an executive experiences for the first time a new question answered in seconds instead of weeks, the difference becomes an acquired preference with no need for a sales pitch.
The third reason is that it builds on existing architecture. The Kimball methodology — the canonical standard of data warehousing since 1996 — remains valid. What changes is the purpose of the model: it goes from being a container of reports to being a strategic asset that agents reason over. This property — that it does not demand discarding the existing investment but capitalizing on it — is what makes the case adoptable. An organization with a mature data warehouse does not need to rewrite its infrastructure; it needs to add the agentive layer on top.
Agentive value is not demonstrated by replacing what already works. It is demonstrated by making what already works produce results at speeds that were previously impossible.
The historical problem
Access to analytical knowledge has historically been slow because every new question requires a project. The sequence is familiar and painful, and it captures exactly the problem that conversational BI solves.
The executive puts the question to their BI team. The question can be as simple as “why did margins fall in the corporate segment last month?” or as complex as “which customers have usage patterns similar to those who canceled over the last six months?”. In both cases, the question has to be interpreted by humans on the BI team, translated into a technical specification, assigned to a developer, built as a report or dashboard, validated with the executive, adjusted according to feedback, and finally delivered.
The sequence has four typical phases: coordination (days to schedule meetings and align expectations), requirements gathering (days to understand the question and specify the data required), development (weeks to build the report), validation (days to review and adjust). The full process typically takes between four and twelve weeks. And even then, what is delivered is a specific report that answers the original question — it is not a reusable capability for the related questions the executive will ask afterward.
The real bottleneck is the one Chapter 2’s diagnosis named: humans in the middle, each adding latency and room for misinterpretation. The executive frames the question ambiguously because they are thinking it out loud; the analyst interprets the ambiguity one way; the developer implements another interpretation. When the report arrives, the executive discovers it is not exactly what they needed, and the cycle starts over.
The cost of putting the traditional model into operation is not trivial either. Building the Data Lake → Synapse → Power BI chain, or any modern equivalent, typically requires between one hundred thousand and five hundred thousand dollars of initial setup, between ten thousand and fifty thousand dollars of monthly operation, and a time-to-first-useful-dashboard of between three and six months. And all that investment delivers the capacity to answer only those questions someone foresaw when designing the system. For the unanticipated question — Monday’s fresh intuition — Chapter 2’s diagnosis holds: off the menu, into the queue, or into oblivion.
The consolidated BI industry openly acknowledges that the model has reached its ceiling — Chapter 2 quoted the voices (Tellius, Superwise, Cube, Tableau, BCG) and we will not repeat them. The substance of the acknowledgment matters more than its quotes: fifteen years of cosmetic redesigns — prettier dashboards, self-service for non-technical users, NLP over pre-modeled data — promised to democratize access to knowledge and delivered incremental improvements, because the problem was never cosmetic but structural. The bottleneck was the human in the middle, and no redesign could eliminate it without replacing it with something equivalently capable.
The agentive solution

With the Agentive Architecture implemented over the organization’s data, the executive converses directly with an agent that has access to that data. The sequence that in the traditional model took four to twelve weeks collapses into an operation of seconds. The question reaches the agent, the agent processes it, dynamically executes the query over the data, returns the answer. If the executive wants to refine — “and now show me only the corporate segment” —, the agent refines in the next answer. If they want to go deeper — “what specifically changed in September?” —, the agent goes deeper. The conversation replaces the project.
The difference is structural. The intermediate steps — coordination, requirements gathering, development, validation — disappear because the agent executes them dynamically on each question. The human who had to be the intermediary steps out of the middle. And because the agent can answer any question, not just the pre-built ones, the executive does not need to “request a new report” every time they have a fresh intuition. The analytical capability is available for any question over the available data.
The quantitative change is radical. The time-to-answer metric goes from four to twelve weeks in the traditional model, to five to sixty seconds in the agentive model. The difference is three orders of magnitude — it is not improvement, it is transformation.
When the cost of a question collapses from weeks to seconds, the nature changes of the relationship between the organization and its information. The three effects that Chapter 2 already described materialize in the case of real-time knowledge. Analytical capability becomes elastic — it adapts to the current need, not to what someone pre-defined months ago. Iteration replaces specification — the executive explores, refines, goes deeper in a continuous conversation with the information, instead of defining requirements in advance and waiting for the result. And the questions that were never asked are now asked — when asking is free, analytical curiosity stops being limited by the BI budget.
The most important change is not speed. It is the executive’s cognitive freedom, no longer forced to choose what to ask.
Real time as continuous temporality
It is worth being precise about what exactly the “real time” of this
case is — the state on the other side of the Quantum Leap that Chapter 2
coined. It is not a delivery channel nor an attribute of the question:
it is the temporality of the Botlet that sustains the
informational manifestation. Applied to BI, a report
(point-in-time snapshot) is the Botlet with discrete temporality, and a
live dashboard is the same Information Product
(PI) with continuous temporality, sustained over a
persistent Layer 3 runtime. The “real time” of the BI case is not chosen
by flagging a delivery mode: it is chosen by giving the Botlet
continuous temporality. The temporality specification — the two regimes
and the single runtime that unifies them — lives in Chapter 5 §2.
The PI that this canonical application delivers can,
moreover, be composed of multiple named views with context
navigation (drill-through). Its normed description —
multi-view, the data-anchored / no-bypass property — lives in Chapter 5
§2; here it suffices to note that this composition is orthogonal to
temporality: it applies equally to a snapshot and to a live
dashboard.
One must be precise about what changes and what does not. The Kimball model does not disappear. The agent executes it dynamically — it does not replace it. The methodology, the concepts (facts, dimensions, conformed dimensions, slowly changing dimensions), the professional practices of data warehousing remain the substrate. The data warehouses do not disappear. They remain where the data is stored, modeled, and governed. What changes is who consumes it: it is no longer only the human dashboard; it becomes the agent as well. The data analysts and CIOs do not disappear. Their work shifts: they go from building specific dashboards to designing the semantic layer over which agents reason correctly. It is more strategic work, less operational.
The underlying architecture — Varnished Kimball

The Kimball methodology, formulated by Ralph Kimball in The Data Warehouse Toolkit (1996), remains the vendor-neutral standard for dimensional modeling. Its validity does not lapse — its purpose evolves. We call this evolution Varnished Kimball: it preserves Kimball’s conceptual structure — Source, ETL, Presentation, BI Apps, plus cross-cutting Metadata — and adds a contemporary finish that reflects the change in the data model’s purpose.
The canonical components of classic Kimball are five. Source are the operational systems: ERPs, CRMs, transactional systems that generate the data in its raw form. ETL is the extract-transform-load process: cleaning, conformity, transformation of the data from its operational form to its analytical form. Presentation are the data marts: facts and dimensions, conformed dimensions that allow inter-mart consistency. BI Apps are the dashboards, reports, interactive exploration tools — the surface through which the human queries the data. Metadata runs through everything: governance, quality, lineage.
The classic architecture works for the pre-agentive era. It serves to let humans query data via dashboards. It does not serve, on its own, to let agents query data to reason autonomously. The reason is not that the Kimball model is wrong — it is that it is incomplete for the agentive case. It lacks the layer that translates the model into something the agent understands.
On top of Kimball’s classic structure a contemporary layer is mounted that serves the agents. The first component is the explicit semantic layer: a knowledge graph or equivalent semantic layer that encodes the meaning of the dimensions, the relationships, the business rules. The semantic layer is what the agent consults before generating SQL queries — without it, the agent hallucinates. The second component is the Trust Score per datum: a reliability metric for each datum based on lineage, quality, governance, and observability. A component of the data model as a strategic asset. The third component is AI Certification: an automated process for verifying the maturity and readiness of analytical models to be consumed by agents. It addresses requirements of NIST AI RMF, ISO/IEC 42001, EU AI Act. The fourth component is the observability of agentive queries: monitoring of the queries the agents execute: which ones, how often, with what success. It allows identifying gaps in the semantic layer.
The complete structure of Varnished Kimball is the one synthesized in the figure above.
The most important change in the architecture: the data model goes from being a container of reports to being a strategic asset. This means that the quality of the datum stops being measured by its cleanliness and comes to be measured by its actionability by agents — a well-cleaned datum without semantic context is useless to an agent, whereas a somewhat dirty datum but rich in context can be extremely useful. It means that governance goes from ad hoc to certified. It means that the modeling is driven by the questions the agents will ask, not by the expected reports.
The AtScale measurement Chapter 2 quoted — more than eighty percent failure without a semantic layer; accuracy close to one hundred percent with it — is the quantitative backing of this first component. And the terms the industry coined for the layer — ThoughtSpot’s Agentic Semantic Layer, Salesforce’s Enterprise Knowledge Graph, Databricks’ Agentic BI — are angles on the same diagnosis: the agent needs much more than data; it needs meaning associated with the data.
Mapping to the hyperscalers
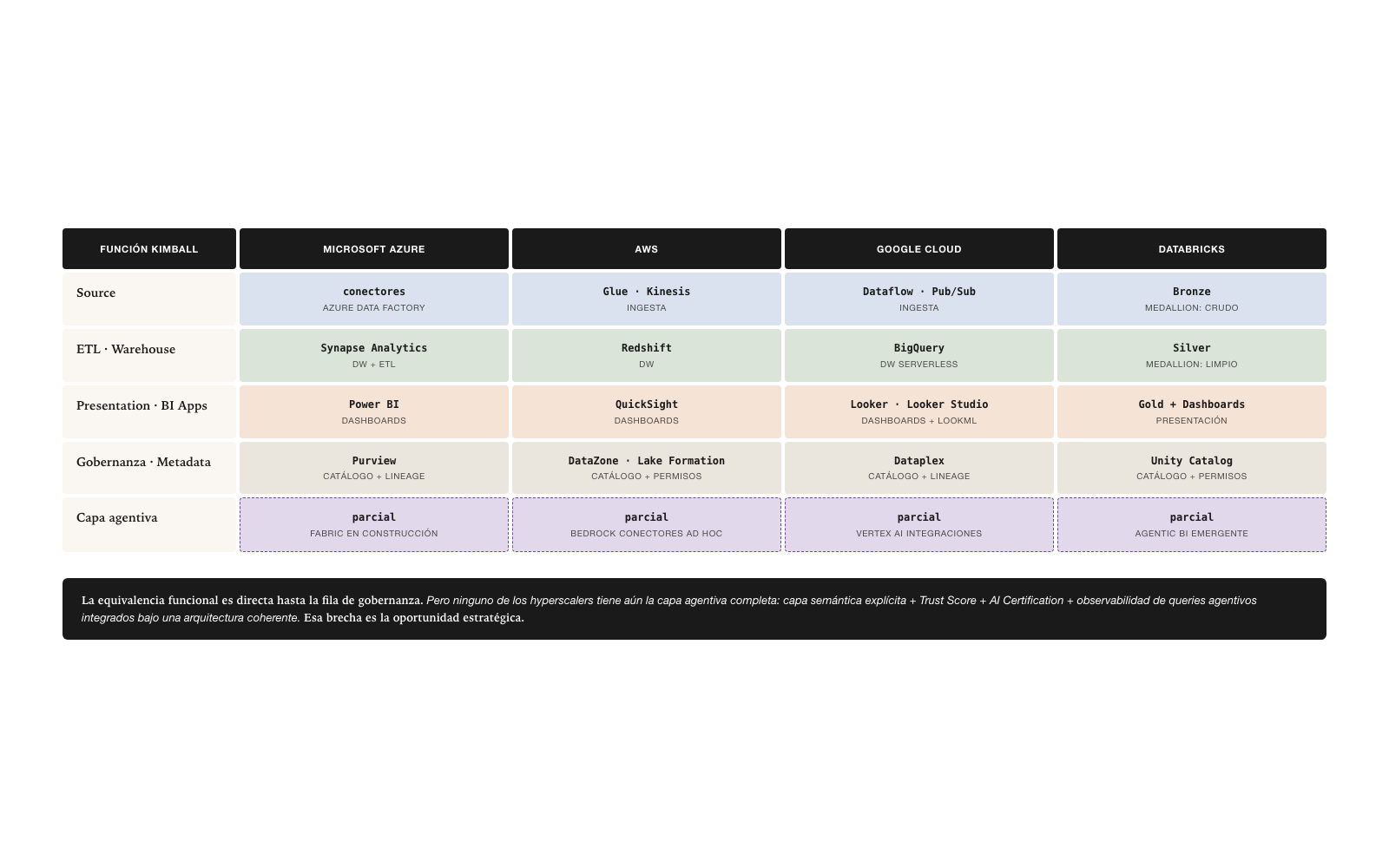
Each hyperscaler implements base Kimball under its own terminology, which confuses anyone trying to navigate the market for the first time. The functional equivalence, however, is direct.
Microsoft Azure implements Kimball with Synapse Analytics as ETL and warehouse, Power BI as the BI App, Purview as governance, and Fabric as the unifying layer. AWS implements it with Redshift as warehouse, QuickSight as the BI App, DataZone as governance, Lake Formation as the data layer. Google Cloud implements it with BigQuery as warehouse, Looker as the BI App, Dataplex as governance. Databricks implements it with Lakehouse using Medallion Architecture (Bronze/Silver/Gold) as ETL and warehouse, and Unity Catalog as governance.
Databricks’s Medallion Architecture deserves a special note: it is a modern implementation of Kimball over a lakehouse. Bronze corresponds to Source — raw data. Silver corresponds to transformed ETL — clean and conformed data. Gold corresponds to Presentation — data ready for consumption. The nomenclature is new but the concept is classic Kimball applied to a lakehouse.
No hyperscaler yet has a complete implementation of the agentive layer of Varnished Kimball. The explicit semantic layer, the Trust Score per datum, AI Certification, the observability of agentive queries — these are pieces that each hyperscaler is adding gradually, but none has a complete integrated offering. Quest/erwin is one of the few vendors that productizes the full extended model under the concept “Model to Marketplace” — but as a specialized product, not as part of a hyperscaler’s stack.
This gap is a strategic opportunity: the actor that delivers complete Varnished Kimball, integrated under a single coherent architecture, captures the space that no actor currently covers completely.
The industry consensus
Ten actors converge — from different angles — on the same vision of conversational BI over Kimball architecture: Tableau, Cube, Tellius, ThoughtSpot, Salesforce, AtScale, Databricks, Informatica, eWeek, and Gartner, whose formulations have already run through this chapter and Chapter 2. The list makes it clear that this is not the isolated proposal of a single actor — it is emerging consensus across the field.
The common pattern is clear. The conventional industry recognizes that traditional BI must be extended with agentive capability. The difference among the actors lies in how explicitly the architecture is integrated. The actors that treat agentive BI as a loose feature produce limited solutions; the actors that treat it as an architectural redesign of the data layer produce solutions that can be sustained in production.
How is the canonical case implemented?
For an organization that has a reasonable Kimball architecture and wants to add agentive capability, the implementation path follows a recurring pattern.
Stage one is to build or acquire an explicit semantic layer that encodes the meaning of the dimensions, facts, hierarchies, and business rules. Without this layer, agents hallucinate or produce incorrect queries. The organization has several product options: AtScale as a specialized product, dbt Semantic Layer as a layer that integrates with dbt modeling, Cube as a product with an emphasis on performance, LookML as Looker’s semantic layer for cases where Looker is already the BI tool. The choice depends on the existing stack and on architectural preferences. What is critical is not which product is chosen — it is building the layer with discipline.
Stage two is to build or configure an agent with access to the semantic layer. The agent does not generate SQL directly — it generates semantic queries that the semantic layer translates into correct SQL. This is what distinguishes a robust conversational BI from a “chatbot demo over a data warehouse.” The agent that generates SQL directly hallucinates frequently; the agent that operates over a semantic layer with clear contracts maintains high accuracy.
Stage three is to apply Trust Infrastructure over the agent. The five pillars — Governance, Audit, Validation, Resilience, Transparency — over the conversational agent. Governance defines what data it can query, who can ask what. Audit records each query and each answer. Validation especially detects financial or KPI hallucinations — a particularly serious category of error in conversational BI. Resilience against failures of the semantic layer. Transparency about which tools the agent invoked to produce each answer.
Stage four is gradual onboarding. Start with a limited data domain — finance, sales, or a specific one — where the quality of the model is high and the users are sophisticated. Expand to more domains only after validating that the agent delivers value without hallucinating. Patience is key — saturating the agent with all of the organization’s data from the start guarantees that the first users lose trust due to incorrect answers. The project has to earn credibility before expanding.
Stage five is evolution to the real-time enterprise. Once the agent answers questions correctly over historical data, evolve toward having it act on the data: proactive alerts when it detects anomalies, execution of automatic corrective processes within governed limits, escalation to the human for above-threshold decisions. It is the transition from online enterprise to real-time enterprise described in Chapter 2. This stage is where the agentive system goes from being better BI to being autonomous operation.
Why does this case qualify as a canonical application?
The three reasons that opened this chapter — universal, with a clear metric, built on existing architecture — explain why the case is foundational. The close calls for a different angle: what this case does for the others.
Real-time access to information is the enabling condition for the rest of the agentive transformation. Without it, the agents that act in other domains — operations, sales, customer support — lack an informational foundation. That is why this case typically appears as the first in the adoption trajectory of the Agentive Architecture by serious organizations. The organizations that try to skip the real-time knowledge case to go directly to autonomous-operation cases typically fail — without the real-time information base, the operational agents operate blind.
And because it builds on what already exists, it is also the lowest-barrier case: an organization can earn its first agentive experience — the question answered in seconds that turns skepticism into demand — without committing to a massive transformation budget. That first experience is what opens the door to the domains that follow.
Whoever solves real-time knowledge earns the right to raise the other cases. Whoever does not, operates in perpetual pilot.