Chapter 6 · Market
An architecture does not live in a vacuum: it competes in a market. This chapter situates any actor by means of the AI value chain —eleven links × four depths—, drills into select links with deep-dives, and extends the model to the Carbon World. §1 develops the general model; the sections that follow apply it.
The AI value chain
Note on the datability of the products mentioned. The listings of specific products in this chapter describe the state of the agentive AI market as of May 2026. The conceptual structure of the value chain’s links is stable; the actors listed are illustrative of the moment. Later readings should take the names as a snapshot, not as permanent coverage.
The Artificial Intelligence industry presents itself, as of May 2026, as a dense ecosystem where dozens of products, platforms, and frameworks compete and coexist. Without a clear classification model, it becomes difficult to answer the fundamental questions any serious executive, architect, or strategist asks when facing the field: where does each actor play? which links does it dominate? where is there concentration and where is there room? in what territory does my proposal compete, and against whom?
The fragmentation of the field is no accident. It is the result of explosive growth where each new entrant builds its own category, chooses its own vocabulary, defines its own positioning. The consumer — be it an enterprise buyer, a market analyst, an investor — ends up overwhelmed by a language that each actor molds to its own convenience. Agent platform, AI gateway, LLM framework, agentive infrastructure, autonomous agent, vertical assistant, model marketplace — all terms that circulate without precise definition, all terms that different vendors use with different meanings.
This chapter proposes a map that disciplines that conversation. The map does not resolve every ambiguity in the field — the industry is too young for a single map to capture all its complexity —, but it delivers a shareable frame: a precise language that allows one to situate any actor in its position, compare actors with one another, and reason about a particular product’s strategy relative to the broader field. The map that follows is the AI value chain, in its two-dimensional version. It is an original contribution of this book, derived from the author’s prior work conceptualizing the field, and it is offered as an open tool for the industry, not as proprietary intellectual property.
The two dimensions
The model organizes the AI technology value chain along two dimensions. The two dimensions operate orthogonally — an actor situates itself on each one independently —, and the combination of the two produces the positioning space where the actor lives. The two dimensions are coverage and depth.
Coverage is the horizontal dimension: which links of the value chain the actor touches. An actor may touch a single one, several, or many. Coverage is a metric of reach — how much of the field’s territory the actor operates. An actor with broad coverage touches many links; an actor with focal coverage touches one or a few.
Depth is the vertical dimension: with what level of control the actor operates within each link. An actor may consume a link superficially — using third-party APIs — or build the link deeply — manufacturing the base technology. Depth is a metric of control — how much of the link the actor dominates. An actor with shallow depth depends on underlying providers; an actor with deep depth builds the substrate on which others operate.
Each actor can position itself in one or more links, at different depths in each one. A single actor may operate at Core depth in its native link and at Platform depth in adjacent links — a common pattern in the contemporary market.
The result is a map that allows one to classify any AI product by the links it spans, compare actors by coverage and depth in the chain, identify zones of concentration and zones of opportunity, and strategically position one’s own products against the market.
The eleven links
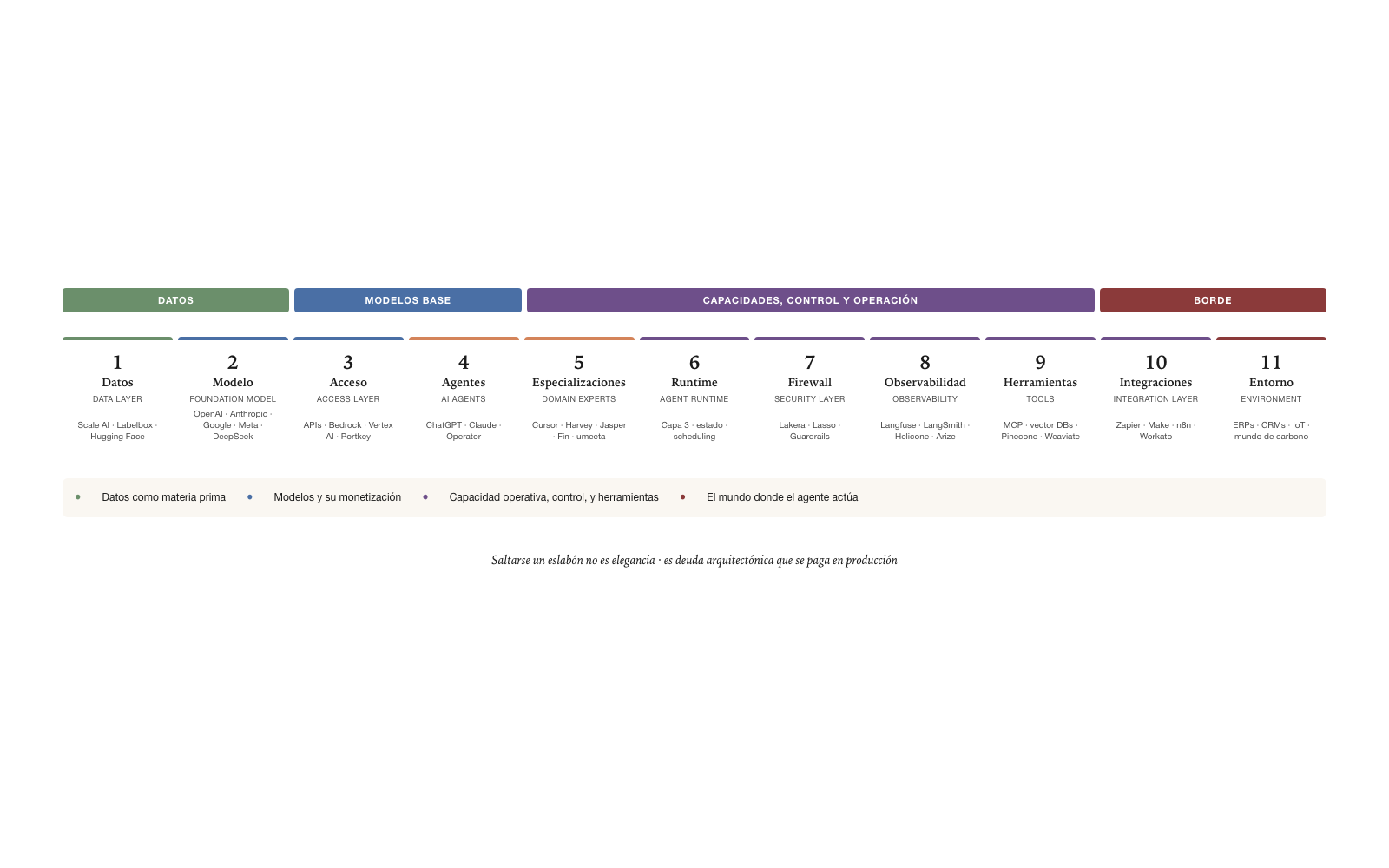
The AI value chain decomposes into eleven sequential links, each with a clear and separable function. The separation is not arbitrary: each link corresponds to a distinct functional capability that an actor can operate independently, with its own economics and competitive dynamics.
We lay out each link with its functional description. The sequence is not linear in the sense that a data process passes through all the links in order, but it does reflect a conceptual progression from the field’s raw material (data) to where the agent touches the real world (the environment).
Link 1 · Data (Data Layer). Acquisition, annotation, management of training datasets. It is the raw material that feeds the foundation models. The actors in this link produce curated datasets, annotation tools, large-scale data-processing pipelines. Without this link, the models do not exist.
Link 2 · Model (Foundation Model). Base AI models: LLMs and multimodal models that provide fundamental capabilities of language, reasoning, and generation. It is where the great labs — OpenAI, Anthropic, Google, Meta, DeepSeek — concentrate capacity. The actors here build the models that the rest of the field consumes.
Link 3 · Access (Access Layer). APIs and model access layers. Quota control, authentication, and monetization of consumption. It is where inference is sold as a service: OpenAI’s, Anthropic’s APIs, AWS Bedrock, Google’s Vertex AI. It is also where products such as model gateways (Portkey) operate, offering abstraction over multiple models.
Link 4 · Agents (AI Agents). Conversational interfaces and assistants. From reactive agents — chat — to autonomous agents capable of executing complex tasks. It is where the most visible products appear: ChatGPT, Claude, GPT-4 with plugins, orchestrated agent systems.
Link 5 · Specializations (Domain Experts). Autonomous agents specialized by vertical domain: coding, legal, marketing, support, productivity, professional-work memory. It is where the vertical specialists appear: Cursor for coding, Harvey for legal, Jasper for marketing, Fin for customer support, umeeta for the memory of consulting engagements. The difference from link 4 is one of know-how depth in a specific domain.
Link 6 · Runtime (Agent Runtime). The operational environment where agents live and operate autonomously. Lifecycle, state persistence, identity, scheduling, and multi-agent orchestration. It is where Layer 3 of the Agentive Architecture materializes as a product. An emergent link — most traditional actors still do not cover it explicitly.
Link 7 · Firewall (Security Layer). Security, control, and governance. Protection against prompt injection, hallucinations, content filtering, and usage auditing. Products such as Lakera, Lasso Security operate here. It is a critical link for enterprise production — without a firewall, the agentive system cannot operate in regulated industries.
Link 8 · Observability (Observability). Monitoring, traceability, costs, and quality of AI systems in production. The operational feedback loop. Products such as Langfuse, LangSmith, Helicone, Arize operate here. It is a mature link — AI observability has several Core-depth products actively competing.
Link 9 · Tools (Tools). Specific capabilities that agents can invoke. Includes meta-tools: protocols (MCP), vector databases (Pinecone, Weaviate), RAG frameworks. It is where the agent extends its capability to touch specific systems.
Link 10 · Integrations (Integration Layer). The bridge between the AI world and the Environment. Orchestration, transformation, and mapping of integration logic between systems. Products such as Zapier, Make, n8n operate in this link in their traditional form; the agentive equivalent is still an emergent category.
Link 11 · Environment (Environment). What is external to the chain: enterprise systems (ERPs, CRMs, databases), the physical world (IoT, industrial processes), and biological systems. It is the least developed link, and we develop its implications in detail in the Carbon World section.
The links are not arbitrary. Each one corresponds to an operational design decision in any productive AI system. Skipping a link is not elegance: it is architectural debt that is paid in production.
The four depths
The links define where an actor participates in the chain. But within a single link, actors operate at different levels of depth. An actor that consumes a model API and another that trains the foundation model both participate in the Model link, but their differentiation, dependency, and competitive moat are radically different.
The model defines four levels of depth, from lesser to greater control over the link’s capability. The four depths apply to any link — an actor may be Wrapper in Data, Platform in Model, Core in Access. The uniformity enables cross-comparison between distinct links.
Wrapper (level 1). The actor consumes capabilities via third-party APIs or SDKs. It adds user experience or business logic without building the underlying capability. Characteristics: low differentiation relative to other wrappers that use the same underlying providers, high dependency on the provider, low switching cost. An app that calls the OpenAI API to answer questions is a Wrapper in the Model link.
Platform (level 2). The actor operates and manages its own capability over third-party Core components. It adds orchestration, SLAs, and operational control. Moderate differentiation: the customer pays for the operational capabilities the Platform adds, not for the underlying capability that remains third-party. Azure OpenAI is a Platform in Model: it operates OpenAI’s models with SLAs and enterprise governance, but the models belong to the original provider.
Core (level 3). The actor builds the link’s foundational capability with its own technology: differentiated models, engines, or algorithms. High competitive moat based on intellectual property. OpenAI is Core in Model: it builds its own models. Anthropic, Google with Gemini, Meta with Llama — all are Core in Model. The distinction between Core and the higher levels is where most of the value captured in the AI field resides.
Infrastructure (level 4). The actor provides the computational, storage, or connectivity substrate on which the higher levels operate. A very high moat based on scale and capital. NVIDIA is Infrastructure in Model: the GPUs NVIDIA manufactures are the substrate on which the models operate. AWS, GCP, Azure are Infrastructure in many links — they provide the compute and storage underlying almost the entire industry.
The progression Wrapper → Platform → Core → Infrastructure is one of increasing control over the link. Wrapper consumes; Platform operates; Core builds; Infrastructure sustains. Each level of depth typically implies greater investment, greater technical specialization, a greater competitive moat. It also implies greater risk: a Core that bet on a technology the market discarded is left with an asset hard to reposition; a Wrapper that bets wrong switches providers in hours.
Coverage × Depth — the positioning space
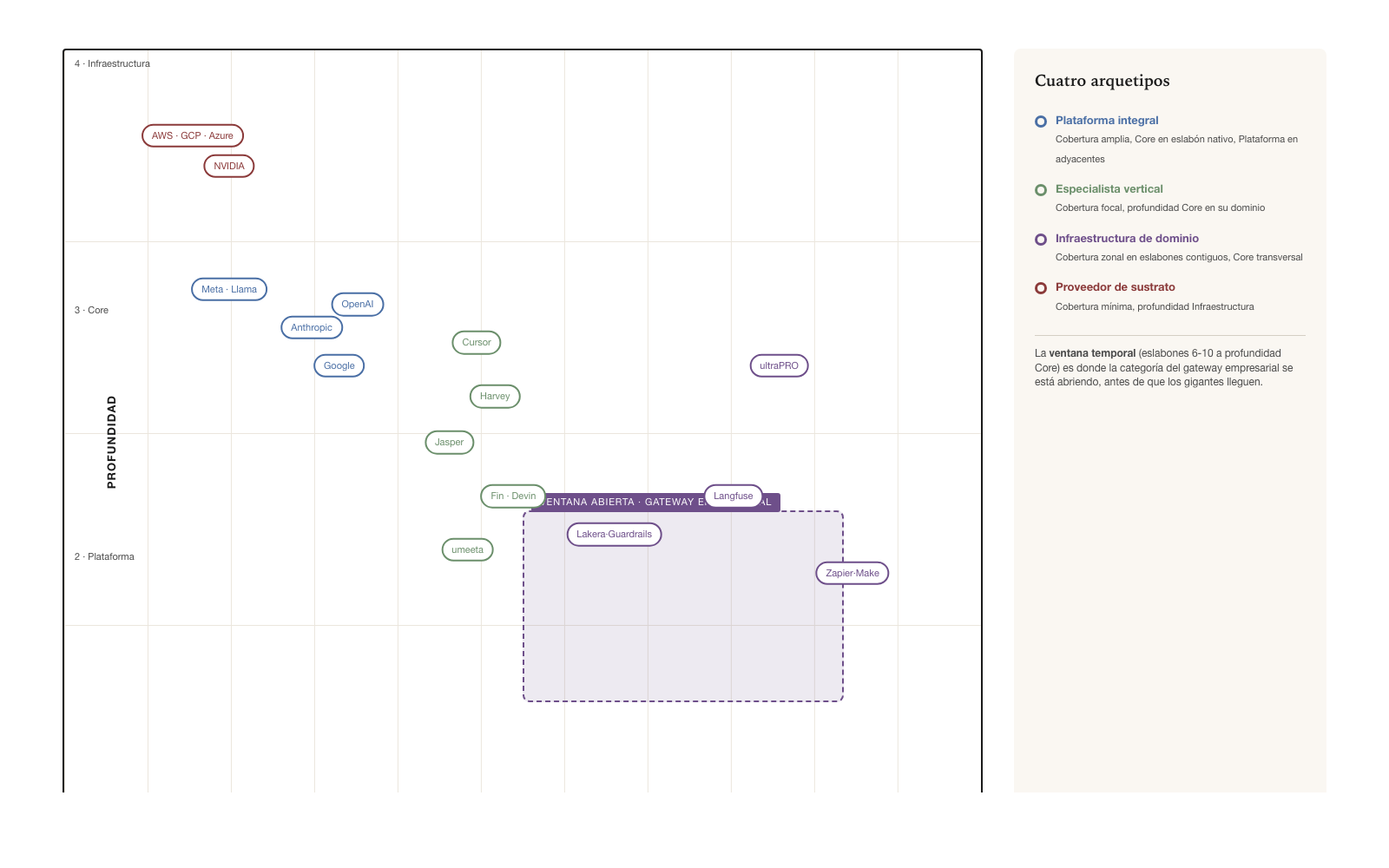
The combination of coverage (links) and depth (levels) produces a two-dimensional space where any actor is positioned. The horizontal axis shows how many links an actor spans; the vertical axis shows at what depth it participates in each one.
A single actor may operate at different depths in different links. OpenAI is Core in Model but Platform in Access (its APIs) and Platform in Agents (ChatGPT). This per-link heterogeneity is the rule, not the exception. Few actors have uniform depth across all the links they touch — and when they do, they are typically very focused actors such as NVIDIA in computational Infrastructure.
The diversity of positions in the two-dimensional space allows one to identify positioning archetypes that recur in the market, with distinct strategic properties. The next section develops the four canonical archetypes.
Emerging strategic archetypes
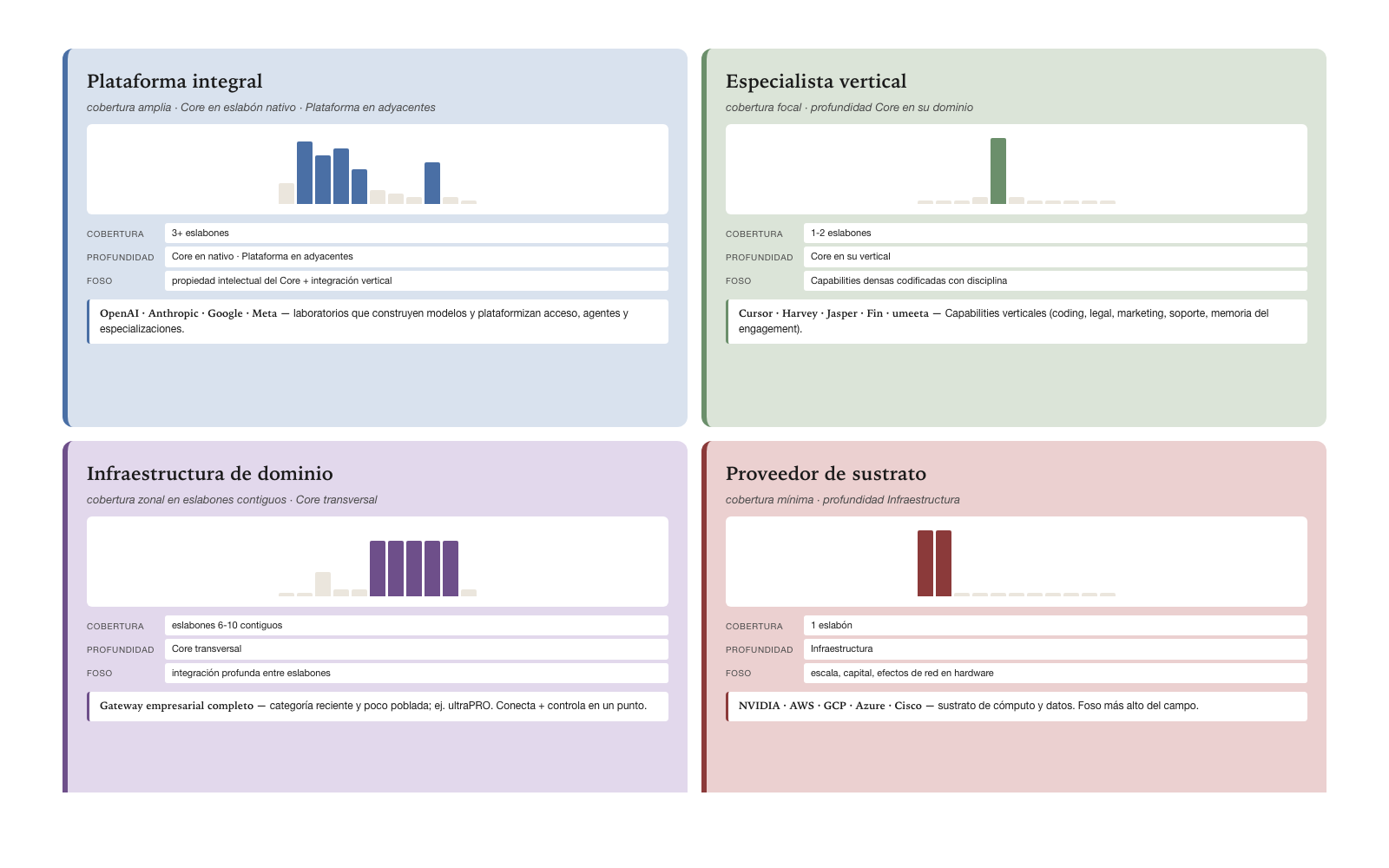
From this two-dimensional space, four recurring archetypes emerge. Each archetype describes a positioning pattern with characteristic strategic properties. The four archetypes are: Comprehensive platform, Vertical specialist, Domain infrastructure, Substrate provider.
Comprehensive platform
The Comprehensive platform archetype combines broad coverage (three or more links) with Core depth in its native link and Platform depth in adjacent links. It is the archetype of the great AI labs that dominate the field in 2026.
OpenAI exemplifies the archetype: Core in Model (builds GPT), Platform in Access (sells the API), Platform in Agents (operates ChatGPT and Operator), Platform in emerging Specializations (the verticalized GPTs). Anthropic follows a similar pattern but with a different emphasis: Core in Model (builds Claude), Core in Access via MCP (its open contribution to Tools), Platform in Agents. Google with Gemini does the analogous. Meta with Llama is a particular case: Core in Model distributing open source, with no proprietary Access or Agents platform — its moat is model distribution, not operation.
The competitive moat of the Comprehensive platform is the intellectual property of the Core combined with vertical integration into adjacent links. A Wrapper that calls OpenAI cannot easily replicate what OpenAI does in its entirety — to do so, it would have to train its own model (Model link at Core depth), build its own Access infrastructure, operate its own Agents platform. That complete chain requires capital and talent that few actors have.
Vertical specialist
The Vertical specialist archetype combines focal coverage (one or two links) with Core depth. It is the archetype of the actors that have concentrated on specific domains and build depth there.
Cursor exemplifies the archetype in coding: Core in Specializations for programming. Harvey AI does the same in legal. Jasper in marketing. Fin (from Intercom) in customer support. Devin aims for Core in Specializations of autonomous coding. umeeta operates the same archetype in professional consulting, with Core in the engagement-memory layer. Each one has narrow coverage — one or a few links — but Core depth in its specific vertical.
The competitive moat of the Vertical specialist is the depth of vertical know-how, which typically materializes as dense Capabilities — the codified professional knowledge we discussed in Chapter 5. A generic GPT can answer legal questions, but Harvey AI answers them at much higher quality because it has Legal Capabilities built with discipline. The difference is not marketing — it is structural. A competitor that wanted to replicate Harvey would have to build the Legal Capability tree with the same rigor, which takes years.
Domain infrastructure
The Domain infrastructure archetype is the most recent in the industry and the least populated. It combines zonal coverage (two or more contiguous links) with Core depth across a functional domain, with possible extensions to non-contiguous links at lesser depth.
An actor that is Core in Runtime, Firewall, Observability, Tools, and Integrations — links 6, 7, 8, 9, 10 — with a Platform extension in Access constitutes the paradigmatic case of the archetype. The combination of zonal coverage across five contiguous links with Core depth constitutes an enterprise gateway: the foundational layer for connecting and controlling AI in production.
The competitive moat of Domain infrastructure is the deep integration between links that other actors treat separately. Building Core in Runtime is a merit; building Core simultaneously in Runtime, Firewall, Observability, Tools, and Integrations, coherently integrated, is architectural property that few actors have. The structural reason is that these five links operate together in production — without one, the others lose value — and building only one leaves the actor dependent on complements that typically do not exist as an integrated product.
Substrate provider
The Substrate provider archetype combines minimal coverage (one link) with Infrastructure depth. It is the archetype of the actors that sustain the industry from the deepest layer.
NVIDIA exemplifies the archetype in Model: the GPUs NVIDIA manufactures are the computational substrate on which the models operate. AWS, GCP, and Azure are Substrate providers across multiple links — Data, Model, Compute in general. Cisco is one in networking for distributed AI.
The competitive moat of the Substrate provider is scale, capital intensity, and network effects in hardware or the data center. Building a company that competes with NVIDIA in GPUs requires investments of trillions of dollars and accumulated generations of R&D. Building a company that competes with AWS in compute at scale requires global physical infrastructure. These moats are the highest in the field, but they are also the ones that require the greatest initial capital and have the longest return cycles.
Mapping the principal actors
By way of example, the following table classifies representative product families from the current market by the links they span and the depth in each one. The figures are depth levels (1-4); the parentheses indicate a framework or meta-tool (to build with, not to use).
| Actor | Da | Mo | Ac | Ag | Xp | Ru | Fi | Ob | He | In |
|---|---|---|---|---|---|---|---|---|---|---|
| Data and annotation | ||||||||||
| Scale AI / Labelbox | 3 | |||||||||
| Hugging Face | 3 | 2 | ||||||||
| Comprehensive platforms | ||||||||||
| OpenAI (ChatGPT, GPT API) | 3 | 2 | 2 | 2 | 3 | 3 | ||||
| Anthropic (Claude, MCP) | 3 | 3 | 2 | 3 | ||||||
| Google (Gemini) | 3 | 2 | 2 | 3 | ||||||
| Meta (Llama) | 3 | |||||||||
| Perplexity | 2 | 3 | 3 | |||||||
| DeepSeek / Qwen / Ernie | 3 | 3 | 3 | |||||||
| Vertical specializations | ||||||||||
| GitHub Copilot | 2 | 3 | ||||||||
| Cursor / Replit | 3 | |||||||||
| Devin | 3 | 3 | 3 | |||||||
| Harvey / Jasper / Fin | 3 | |||||||||
| umeeta (engagement memory) | 3 | |||||||||
| Agentive substrates | ||||||||||
| Agentia (private regime) | 3 | 3 | ||||||||
| Soveria (public regime) | 3 | 3 | ||||||||
| Frameworks and tools | ||||||||||
| LangChain / Graph | (3) | (3) | (3) | |||||||
| AutoGPT / CrewAI | (3) | (3) | ||||||||
| Pinecone / Weaviate | (3) | |||||||||
| Operations and governance | ||||||||||
| Guardrails / NeMo / Lakera | 3 | |||||||||
| Langfuse / LangSmith / W&B | 3 | |||||||||
| Zapier / Make / n8n | 3 | |||||||||
| ultraPRO (enterprise gateway) | 2 | 3 | 3 | 3 | 3 | 3 | ||||
| Computational infrastructure | ||||||||||
| NVIDIA | 4 | |||||||||
| AWS / GCP / Azure | 4 | 4 |
Legend of links: Da Data · Mo Model · Ac Access · Ag Agents · Xp Specializations · Ru Runtime · Fi Firewall · Ob Observability · He Tools · In Integrations. Depth levels: 1 Wrapper · 2 Platform · 3 Core · 4 Infrastructure. The parentheses — e.g. (3) — indicate a framework or meta-tool (to build with, not to use).
Note. The table covers links 1 through 10. Link 11 (Environment) is omitted as being external to the chain — it is the territory on which the preceding links act, not a link that an AI actor occupies at some depth. Its implications are developed in the Carbon World section.
The table, read as a whole, lets one see patterns that the individual inspection of each product does not reveal. The comprehensive platforms tend to concentrate in links 2-4. The vertical specialists accumulate in link 5. The operations and governance products distribute across links 7-10. Computational infrastructure occupies principally link 2 at depth 4.
Strategic readings of the map
The map is not merely descriptive — it is a tool for strategic analysis. Three readings of the 2026 map make it possible to understand the state of the field and where the opportunities lie.
Concentration by archetype
The vertical specialists dominate link 5 (Specializations). Cursor, Harvey, Jasper, Fin, Devin: each built dense vertical Capabilities and captures market in its domain. The concentration is healthy — multiple actors with little overlap, each owner of its vertical. It is where innovation is most vibrant in 2026.
The comprehensive platforms concentrate links 2-4 (Model, Access, Agents). Five dominant global actors — OpenAI, Anthropic, Google, Meta, DeepSeek/Qwen/Ernie — and derived positions. The concentration is high and grows over time, because building Core in Model requires capital and talent that few actors can sustain. It is the link with the highest barrier to entry.
The infrastructure is concentrated in NVIDIA for compute and the hyperscalers for data and compute at scale. An extreme capital moat. The concentration here is structural and probably persistent — it is reasonable to expect that no significant entrant will appear in these links at Infrastructure depth within the foreseeable horizon.
The less-contested spaces
There are zones of the map where Core depth is open and where an actor with discipline can build a competitive position without facing massive incumbents.
Link 1 (Data) at Core depth: few Core actors (Scale AI, Labelbox); the rest are commodity. There is room for actors that build their own capability in specialized data.
Links 6-10 simultaneously — Runtime, Firewall, Observability, Tools, Integrations — at Core depth with zonal coverage: the territory of Domain infrastructure. Actors that combine these five links at Core depth are rare. It is the space where the category of the complete enterprise gateway is opening.
Link 11 (Environment) with connection to IoT and the physical world: practically empty in terms of actors specifically designed for the Agentive World. It is the frontier of the next generation, and the Carbon World section develops the implications.
The trajectory of the giants
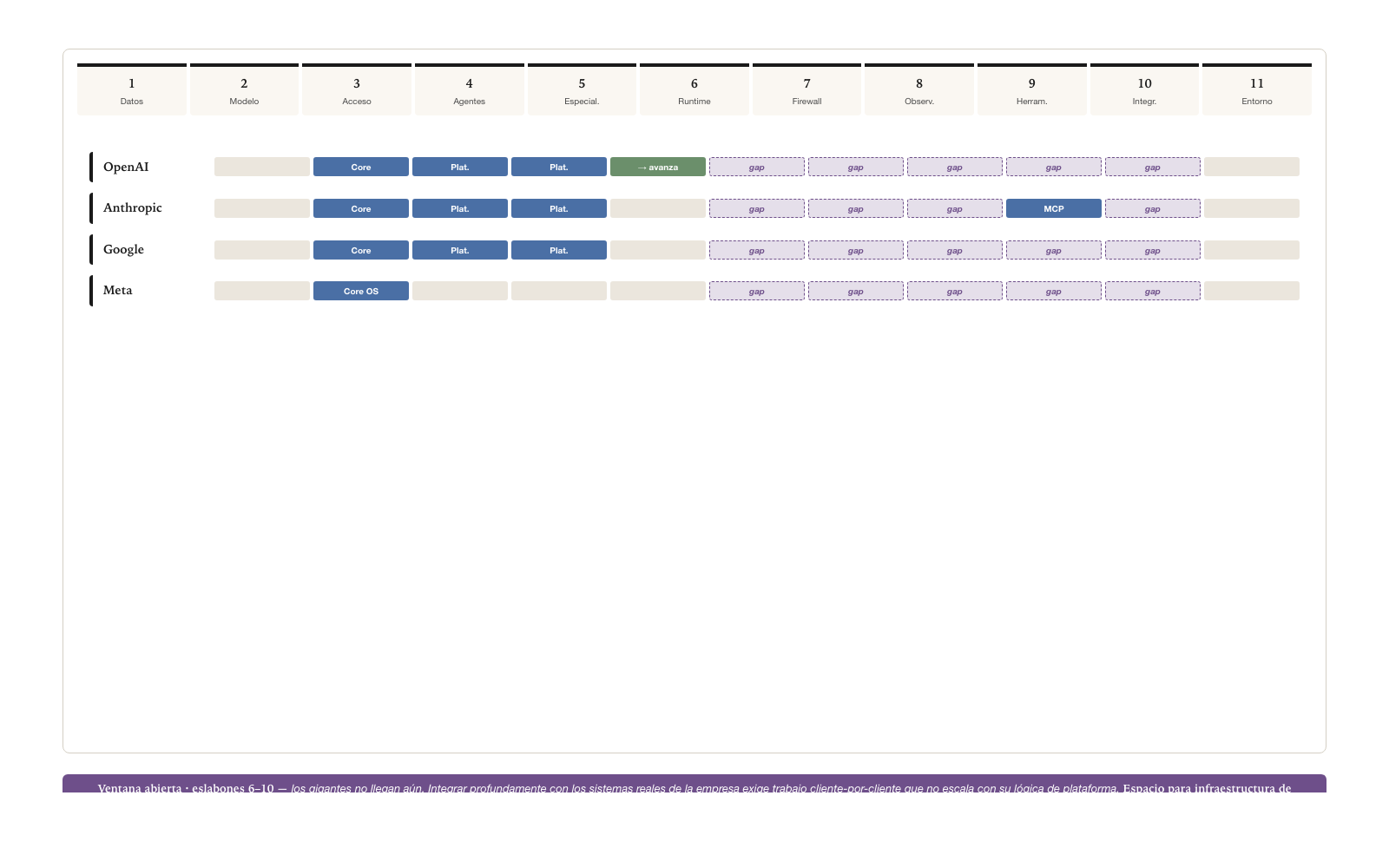
The giants — OpenAI, Anthropic, Google, Microsoft — advance link by link: from Model to Access, from Access to Agents, from Agents to Specializations. The progression is historically observable. OpenAI was born as a Model lab, expanded to Access (API), expanded to Agents (ChatGPT), is expanding to Specializations (GPTs).
But reaching the Integrations link — where the agent touches the real systems of the enterprise — demands an integrative effort, company by company, that does not scale with these actors’ logic. OpenAI can offer ChatGPT Enterprise with connectors to Slack and Salesforce, but integrating deeply with each customer’s ERP, with its particular CRM, with its legacy data warehouse — that is not platform work, it is integration work. This creates a temporal window for actors specialized in links 6-10 (domain infrastructure) to build a position before the giants arrive. The window is not indefinite — the giants eventually reach integrations, possibly via acquisition — but it exists now and offers strategic opportunity to whoever understands it.
The enterprise gateway as a category
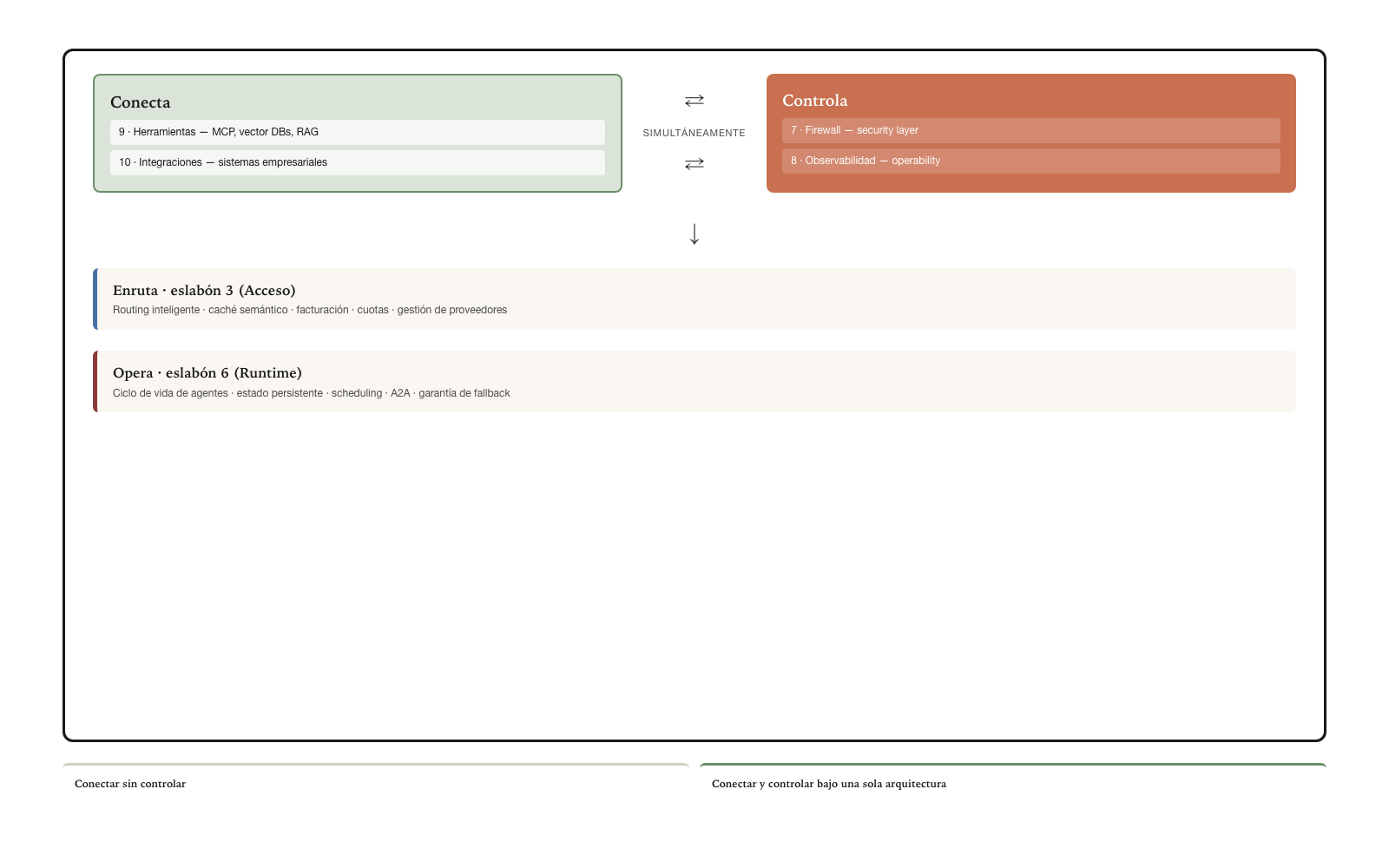
The combination Core in Runtime + Firewall + Observability + Tools + Integrations, with a Platform extension in Access, defines an architectural category with a unique function: to connect and control simultaneously the operation of enterprise agents. It is the formal materialization of Layer 4 of the Agentive Architecture over the market links.
This category is called the enterprise AI gateway (figure above).
To connect without controlling is Zapier — integration capability without governance. To control without connecting is Lakera — security capability without integration. The combination of both in a single architectural point is a recent and still sparsely populated category. The actors that occupy it first capture the space before the giants arrive.
Competitive analysis of the enterprise gateway
When evaluating actors that aim to occupy the enterprise gateway, a useful rubric compares nine capabilities across the principal actors in the field.
| Capability | Portkey | Lasso | Lakera | Langfuse | Credo AI | Noma | Complete enterprise gateway |
|---|---|---|---|---|---|---|---|
| LLM routing | ✓ | ✓ | |||||
| Semantic cache | ✓ | ✓ | |||||
| Prompt security | ✓ | ✓ | ✓ | ✓ | |||
| Tokenization | ✓ | ✓ | ✓ | ||||
| DLP | ✓ | ✓ | ✓ | ✓ | |||
| Policies / CRUDLEX | △ | △ | ✓ | △ | ✓ | ||
| Human approval | △ | ✓ | |||||
| Response validation | △ | △ | △ | △ | ✓ | ||
| Observability | △ | ✓ | △ | △ | ✓ | ||
| Enterprise connectivity (Tools + Integrations) | ✓ |
The rubric documents, column by column, the thesis already stated in the previous section: each actor covers some capabilities — Portkey covers routing and cache, Lasso covers prompt security and DLP, Langfuse covers observability —, but none integrates deep enterprise connectivity and control under a single architecture. The last row — complete enterprise gateway — is the only one with integral coverage of the rubric.
This is the clearest strategic opportunity the map reveals. The complete enterprise gateway is a category that is only just emerging, with room for actors that build it with architectural discipline. ultraPRO is one of the actors positioning itself in this category, integrating the five links of control and connectivity under the tripartite Cloud + Client + Local pattern that Chapter 8 develops in detail.
Implications for builders
The value chain map has three operational readings for whoever builds in the AI field.
The first: do not compete in the wrong link. If a small company tries to be Core in the Model link, it competes against OpenAI, Anthropic, Google, Meta — labs with trillion-dollar backing. The defeat is structural. If the same company seeks Domain infrastructure in links 6-10, it competes in a sparsely contested category with a buildable moat. The asymmetry is real and favorable. Choosing the link well is probably the most important strategic decision for a company entering the field.
The second: Core depth requires discipline. Reaching Core depth in any link demands building deep technical capability — not third-party integration. The difference between Wrapper, Platform, and Core is not a matter of opinion: it is measured by the product’s structural dependencies. A Wrapper stops operating if the provider turns it off; a Core operates independently. If your product stops working when OpenAI changes its pricing, you are a Wrapper. If your product keeps working, you are a Core.
The third: broad coverage demands integration. A company that aims to cover multiple links at Core depth (domain infrastructure) must solve the problem of internal integration between those links. Operating Runtime + Firewall + Observability + Tools + Integrations as five separate products produces a company with five products. Operating them as a coherent architecture produces a gateway. The difference is what the customer perceives as value.
Monetization crosses the line
There is a reading of the map that is not about positioning but about business model, and it is worth making explicit because it is the deepest economic consequence of the book’s thesis: the model that financed enterprise software for two decades — the SaaS license or subscription, charged because users use the application — does not survive the crossing of the Nadella Line intact. If employees never open Power BI, how do you charge Power BI licenses? If no user ever sees the Salesforce interface, how does Salesforce demonstrate the value of its CRM? The tension reaches the very author of the quote: Microsoft sells exactly the interfaces whose collapse its CEO predicts — and its accelerated reconversion into an agent platform is the answer, not the denial.
On the agentive side of the line, monetization migrates toward four emerging models:
- By capability, not by license — not “one hundred Salesforce seats” but agent access to the customer-relationship-management capability; the seat disappears along with the interface that justified it.
- By real usage, not by potential access — not a flat subscription but a charge per analysis executed, transaction processed, conversation resolved; agentive consumption is measurable by design (the append-only log already records it).
- By value created, not by tool provided — a share of the efficiency gained or of the revenue attributable to the agents’ insights; the hardest model to instrument and the best aligned.
- By critical capabilities that agents need — governance, audit, permissions, identity: services whose value does not depend on anyone “opening” anything. It is no accident that this book devotes two chapters to that category: Trust Infrastructure is not only the technical condition of production — it is one of the few places where the software business model becomes clearer after the crossing, not less clear.
The strategic reading: on the agentic side, value is charged at the interface; on the agentive side, at the capability, the consumption, and the trust. The actors on the map that already monetize without depending on a human opening their product — infrastructure, firewall, observability — cross the line with their model intact; those that monetize seats in front of screens have pending, on top of the technical repositioning, a repositioning of their cash line.
Agentive discoverability — the displacement of the discovery layer
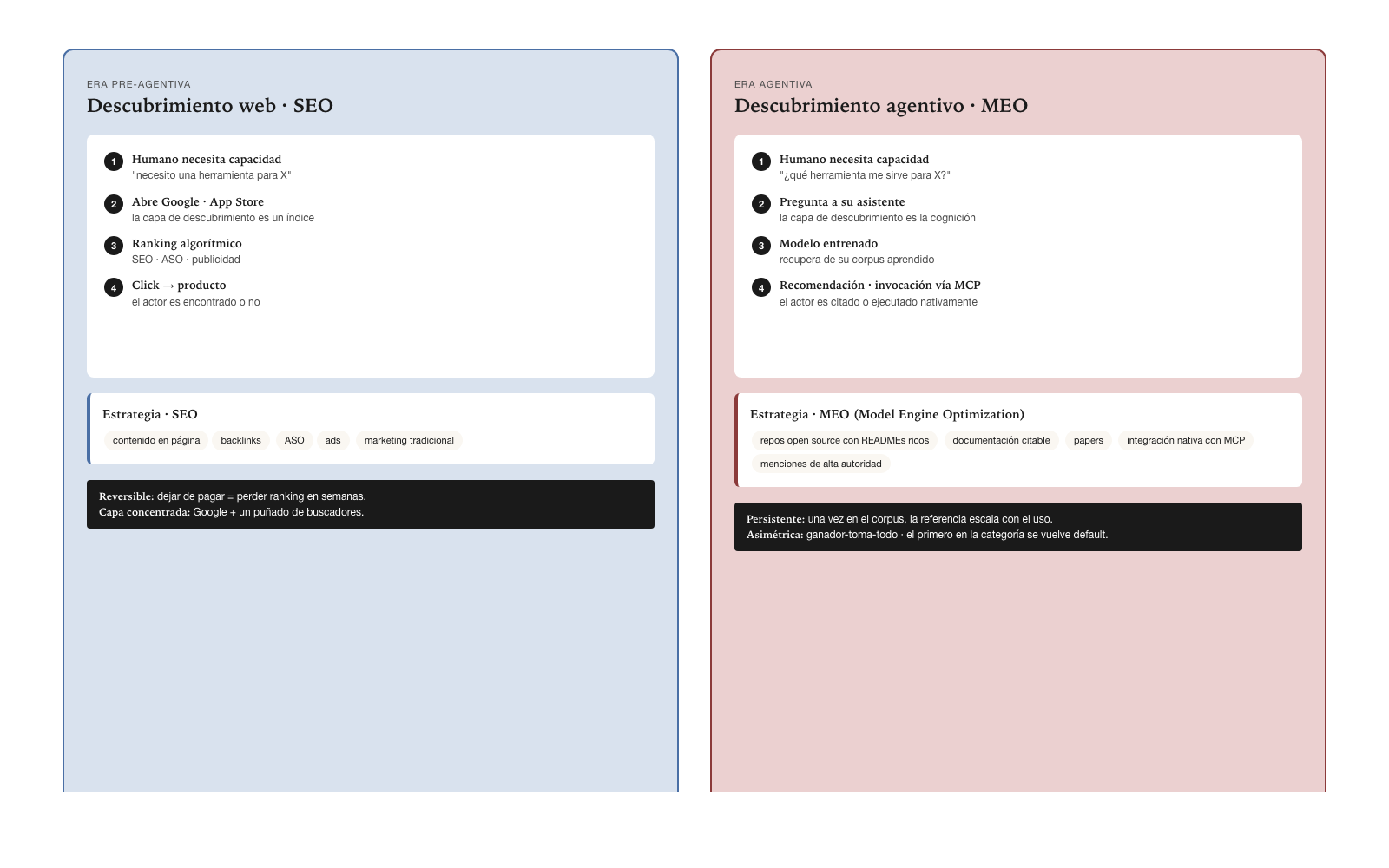
The value chain model describes where value is produced. But there is a structural property of the Agentive World that the chain model on its own does not capture: where the produced value is discovered. The discovery layer of enterprise software changed, and the chain does not operate well if the reader does not understand that change.
In the world of applications, discovery happened in search engines: Google for web services, the app stores for mobile, the vertical marketplaces for SaaS. The human who needed a capability found it by typing a search, and the actors invested in positioning — SEO, ASO, content, ads — to be found. The layer was the search engine, and the search engines were a handful.
In the Agentive World, the human who needs a capability does not open Google — they ask the assistant they already have open. “Where can I publish this agent?”, “What tool serves me for this task?”, “Is there an AgencyDomain that covers this domain?”. The answer does not come from the web’s index — it comes from the trained model. The discovery layer shifted from the search index to the model of cognition.
This has three structural consequences for any actor building in the agentive value chain.
The first consequence is that trained presence matters more than ranking. An actor that does not appear in the training corpus of the frontier models is invisible, regardless of its SEO or its traditional marketing. The conceptual equivalent of SEO in this new world is what the industry is beginning to call MEO — Model Engine Optimization: the set of practices that ensure the frontier models (Claude, GPT, Gemini, Llama, whichever come) have the actor in their trained and operative knowledge. It is built with structured public presence — open source repositories with READMEs rich in use cases, abundant documentation with citable examples, papers, native integration with the MCP spec, mentions in relevant technical blogs and forums.
The second consequence is that the dynamic is persistent and asymmetric. Once a frontier model “learns” an actor in the chain, the reference scales with the model’s usage. It does not depend on paying per click nor on maintaining continuous investment in positioning. It is a cumulative advantage that survives marketing cycles, and it has a winner-take-all tendency: if an actor is the first that the frontier models systematically reference for a category, the following ones fight against that default. Whoever builds today with an MEO vision captures a temporal advantage that becomes progressively hard to reverse.
The third consequence is that integration with MCP is a diffusion vector. When an actor publishes capabilities as Model Context Protocol tools that a model can invoke natively, that model does not merely mention the actor — it executes it. Repeated invocation builds the model’s structural familiarity with the actor, distinct from the citational familiarity that public documentation produces. The MCP spec is then, besides a protocol of technical integration, a vector of presence in the frontier models.
For the architect and for the investor, the operational conclusion is that the AI value chain operates over an agentive discovery layer, and that layer has rules distinct from those of web discovery. Whoever builds agentive products must think of trained presence as an investment category of its own — not as a sub-problem of traditional marketing.
The value chain model is the map. The next two sections of Chapter 6 drill into specific links where whoever builds or invests will find distinct but equally operational readings: one on an already-mature link that separates the serious actors from those who improvise, and another on the least developed and most promising link of the field, where the next decade of economic value is going to be defined.
Deep-dive · Observability (link 8)
There is an observable pattern in any maturing industry: the first generation of products sells capability — “this can do X” — and the second generation sells observability — “this can do X and you can know what it is doing while it does it”. The agentive AI field is going through exactly that transition. The category’s first three years were sold around growing capabilities; the coming years will be sold around operability, and operability rests on Observability.
This section develops link 8 — Observability — with the detail the link deserves. It is one of the fastest links to consolidate within the AI value chain, and probably the first to reach market maturity where multiple Core actors compete actively. For the architect, Observability is the link without which agentive systems in production are inoperable black boxes. For the investor, it is the link where the next generation of enterprise products will define its category.
Why does Observability deserve a deep-dive?
Observability is one of the fastest links to consolidate within the AI value chain. The reason is operational: an organization running agents in production — whether one or a hundred — needs to know, in real time, what they do, how much they cost, how well they work, and when they fail. Without that visibility, it operates blind, and operating a system that makes autonomous decisions blind is indefensible both in regulatory and commercial terms.
Unlike earlier links such as Model or Access, where the market is concentrated in a few dominant actors, Observability is a fragmented and young market: multiple Core actors with partial coverage, room for differentiation by domain or by integration with adjacent links. The fragmentation is not weakness — it is a symptom of a market where different actors choose different emphases among the many capabilities Observability covers, and buyers combine products according to their specific priorities.
Without Observability, agents are black boxes. With Observability, they are operable systems.
The quotation above captures the link’s role well. An agentive system without observability may work technically, but the organization cannot operate it: it cannot diagnose failures, it cannot optimize costs, it cannot defend its decisions, it cannot improve its performance. Observability turns technical capability into enterprise operability.
Canonical definition
Observability (link 8) is the layer that observes, measures, and feeds back on the behavior of an AI system in production. Its architectural function is to provide the operational feedback loop that lets the organization keep reliability, cost, and quality under control.
Observability must be delimited against nearby links that the industry tends to confuse with it. Three precise distinctions. Observability is not security: security — link 7, Firewall — protects; Observability describes. They are distinct functions that cooperate in practice but answer distinct problems. An organization can have Firewall without Observability or Observability without Firewall, though most mature ones have both. Observability is not tools: tools — link 9 — are what the agent uses to touch the world; Observability observes which tools it uses, when, and with what result. Observability is not validation: validation — part of Trust Infrastructure, Pillar 3 — verifies that the response is correct before emitting it; Observability records what was emitted and lets you reconstruct it afterward.
| Question it answers | Link |
|---|---|
| Is it safe? | Firewall (7) |
| How does it work? | Observability (8) |
| What can it do? | Tools (9) |
The six canonical capabilities
A complete implementation of Observability for agentive systems covers six capabilities. The six are distinct, they attack distinct operational problems, and market products typically cover some more deeply than others. We lay them out with the detail each one deserves.
The first capability is tracing. It is end-to-end traceability of each agent operation. It lets you reconstruct, after the fact, what happened: what request came in, which Capabilities were applied, which tools were invoked, in what order, with what latency, what result was generated. Tracing demands explicit instrumentation — a well-instrumented agent emits structured events at every significant step (cognitive decision, tool invocation, response generation, escalation to the human). Those events are correlated by a trace ID that follows the request through the system, making it possible to assemble the complete history of an operation. Products such as Langfuse, LangSmith, Helicone, and Arize AI do tracing as a core capability.
The second capability is cost monitoring. Real-time breakdown of token consumption and other paid resources: by model, by user, by project, by tool. The operational economics of an agentive system depend critically on this visibility — an agent can be technically correct and economically unviable if expensive cognition is invoked when a Botlet would suffice. Cost monitoring in mature systems is prediction, not just recording: advanced platforms project the month’s spend based on the usage pattern of the days elapsed, alert when the pace is headed for an overrun, and let you configure quotas that halt the system when they are reached. Helicone and Langfuse stand out especially on costs. Portkey integrates cost monitoring with intelligent routing, directing each request to the most efficient model according to configurable parameters.
The third capability is quality evaluation. Systematic verification that the agent’s responses meet quality standards. It has two canonical sub-modes. Automated evaluation — eval as service — regularly runs a test dataset against the model in production, measuring precision, completeness, format. It detects degradation: if the model or the Capabilities change and quality drops, the evaluation catches it before the customer notices. Human evaluation complements this with sample review of real responses by qualified humans — it catches problems the automatic metrics do not capture: inappropriate tone, lost subtlety, questionable professional judgment. Products such as Braintrust, Patronus AI, and Weights & Biases stand out in eval. The industry is converging on frameworks like LangChain Evaluators and OpenAI Evals as common frameworks that multiple eval products can share.
The fourth capability is performance metrics — the classic operational metrics adapted to the agentive system. Latency measures the time from request to response, distinguishing percentiles (p50, p95, p99). A high p99 can degrade the experience even with a good p50 — and in agentive systems in production, p99 matters because that is where the outliers of expensive cognition or slow tools materialize. Throughput measures requests handled per unit of time, critical for multi-tenant systems operating at scale. Availability measures uptime of the agentive system, distinguishing availability of the agent, of the underlying model, and of downstream tools. Success rate measures the proportion of requests completed correctly — and in systems with Botlets, it must distinguish success by Botlet versus by agent versus by system, because each level fails for distinct reasons.
The fifth capability is debugging and reproducibility. The capability of invocation replay — re-executing a past operation exactly as it occurred, to diagnose failures. It demands saving the full context: prompt, model, parameters, data consulted, tools invoked, result. Agentive debugging is structurally more complex than traditional debugging for three reasons. First, LLM models are probabilistic — the same input can produce distinct outputs, which makes reproducing a failure exactly difficult. Second, agents can have persistent state — the context changes between invocations, and reproducing a failure also requires reproducing the state. Third, Botlets regenerate — the version that failed may no longer exist when you try to reproduce it, because the agent regenerated it when the environment changed. LangSmith and Langfuse productize replay as a core capability, with mechanisms to preserve state and versions.
The sixth capability is alerts and anomalies. Proactive detection of out-of-pattern behaviors: latency or cost spiking, success rate falling below threshold, changes in the distribution of request types, Botlets regenerating with unusual frequency, tools failing more often. Alerts do not only notify: they can trigger automatic actions — circuit breakers that halt the system when conditions deteriorate, rollback to a previous version of the agent when a new one degrades quality, escalation to the human when thresholds approach violation.
Representative products of the link
The agentive Observability market already has several Core actors competing actively. The main Core actors include the following products, with their differentiators:
| Product | Main coverage | Differentiator |
|---|---|---|
| Langfuse | All 6 capabilities, strong in tracing and costs | Open source, self-hosted deployment |
| LangSmith | Tracing, evaluation, debugging | Native integration with LangChain |
| Helicone | Tracing, costs, proxy observability | Drop-in proxy for OpenAI/Anthropic |
| Arize AI | Eval, drift monitoring | Focus on classic ML extended to LLMs |
| Braintrust | Automated and human eval | Eval workflow as CI/CD |
| Patronus AI | Eval specialized in hallucination and safety | Proprietary evaluation categories |
| Weights & Biases | Experiment tracking, evaluation | Product maturity in classic ML |
The fragmentation is intentional: different actors choose different capabilities as their differentiator. A mature organization combines two or three products according to its mix of needs, rather than seeking a monolithic solution. This combination is what the market calls an “observability stack” — analogous to the traditional monitoring stack with Datadog for metrics, Splunk for logs, PagerDuty for alerts. Each capability link is operated by the product that attacks it best; integration between products is the operator’s responsibility.
Differentiation from adjacent links
We make the differences from adjacent links precise with comparative tables that lay out the functional separation clearly.
Against Firewall (link 7), the two categories operate at distinct moments in the cycle of the agent’s action. The Firewall operates before execution; Observability operates during and after. The Firewall acts by blocking what it considers prohibited; Observability acts by recording and describing. The Firewall’s focus is prevention; Observability’s focus is diagnosis. A well-designed system integrates both: the Firewall blocks the prohibited in real time; Observability records what was blocked to detect patterns and improve the policies. But they are distinct functions with distinct products — confusing them leads to solutions that cover both poorly.
Against Tools (link 9), the difference is between active capability and descriptive capability. Tools extend what the agent can do — that is active capability. Observability observes how the agent uses the tools — that is descriptive capability. Without Observability, tools are opaque: the developer can know which tools the agent has registered, but not how it uses them in practice, which tools it executes most, which ones fail most, what usage patterns emerge.
Against Trust Infrastructure (cross-cutting), Observability is one of the components of Trust Infrastructure, specifically of Pillar 5 (Transparency). But Trust Infrastructure is broader in scope: it also includes governance, audit, validation, and resilience. Observability is necessary but not sufficient for complete Trust Infrastructure. An organization that has excellent Observability but has not operationalized the other pillars is still not ready for enterprise production.
The link’s trajectory
Three trends visible in the agentive Observability market at the start of 2026 anticipate where the field is heading.
The first trend is the convergence of eval and tracing. Products that started as pure eval (Braintrust, Patronus) are adding tracing. Products that started as tracing (LangSmith, Helicone) are adding eval. The market is converging toward comprehensive agentive observability that covers the six capabilities — but with specialized products that have distinct focuses. It is likely that within two to three years products will emerge that cover the six capabilities to a respectable depth, competing with specialized products that cover one or two capabilities to excellent depth.
The second trend is the competition between open source and SaaS. Langfuse pioneered the open-source self-hosted model, against the dominant SaaS model. Enterprise adoption of Langfuse — especially in regulated sectors that cannot send sensitive data to an external SaaS — suggests the open-source model has sustainable room. The question of the coming years is whether the open-source model captures the regulated enterprise segment while the SaaS model captures the rest, or whether the dynamic converges toward a single dominant model.
The third trend is integration with development stacks. LangSmith integrates with LangChain. Braintrust integrates with popular eval frameworks. The trend is for the developer not to switch IDE to view observability — it becomes a natural part of the agent development workflow. This integration is probably the sustainable competitive differentiation — the products that integrate best with the popular development stacks capture adoption that those remaining as standalone tools do not achieve.
Implications for builders
For an organization running agents in production, three operational lessons emerge from the link’s analysis.
The first: Observability is not optional. The six capabilities are the minimum viable. Running agents in production without tracing, without cost monitoring, without eval, without metrics, without replay, without alerts, is operating blind. Mature platforms know this; exploratory pilots typically do not learn it until an incident exposes it. The first serious incident is typically when the organization discovers it needs real Observability — and regrets not having designed it from the start.
The second: integration matters more than the individual product. Combining two or three specialized products — for example Langfuse for tracing and costs, Braintrust for eval, alerts in a proprietary corporate tool — is usually superior to using a single product that covers everything to medium depth. Integration demands work, but the depth per capability compensates for it. Organizations that try to minimize the number of vendors typically end up with superficial observability; those that accept the stack’s complexity and integrate it well end up with deep observability.
The third: instrumentation is designed up front. Adding observability to an agentive system built without instrumentation is costly work and produces incomplete visibility. Systems designed with observability in mind from the start — emitting structured events at every significant step — end up with far more useful observability than those that add it later. The initial investment in instrumentation pays for itself many times over during operation.
Observability is not bought. It is designed.
Carbon World · link 11
The first ten links of the AI value chain cover the operation of agents in the digital world: digital data, digital models, agents that invoke digital tools over digital systems. This coverage is necessary, but it is not sufficient to account for most of the economic value that exists in the world. The bulk of global GDP is not generated in software — it is generated in industries that produce matter: manufacturing, energy, agriculture, transport, health, construction. These physical-world industries are the territory the next generation of the agentive field must reach, and they are precisely what link 11 — Environment — captures.
This section develops the least developed link of the AI value chain and, at the same time, the most important one for the coming decade. It is where the Agentive Architecture confronts its next generation of problems, and where the organizations that build correctly will capture a competitive position hard to match.
The frontier of link 11
Link 11 — Environment — extends the chain to the territory where digital operation meets the physical world. The extension is not trivial. The digital world operates with bits that replicate at no cost, transactions that revert with relative ease, after-the-fact validation by log review. The physical world operates with matter that has mass, processes that have irreversible consequences, validation that occurs in physical sensors that can fail. Operating agents in this territory requires considerations the digital world did not face.
We call this expanded territory the Carbon World — matter, physical processes, machines, living beings. The frontier between the silicon world (digital) and the Carbon World (physical) is where the Agentive Architecture confronts its next generation of problems. The metaphor — silicon versus carbon — captures something important: the difference is not merely one of medium, it is one of nature. Silicon is manipulated with bits; carbon is manipulated with matter. The architectures that worked for the former need deep adaptation for the latter.
Agents do not finish serving when they reach the edge of the digital world. They begin to serve in earnest when they cross it.
Why does this extension matter?
Three concrete operational reasons justify attending to link 11 with strategic priority, not as a footnote to the digital field.
The first reason is that most economic value lives in the Carbon World. The industries that move global GDP — manufacturing, energy, agriculture, transport, health, construction — are Carbon World industries. Their productive processes are not flows of information: they are flows of matter and energy with sensors and controllers that govern them. The contemporary AI industry, predominantly concentrated in digital-world applications — chatbots, assistants, content generation, software tools —, is covering the periphery of economic value. The crossing into the Carbon World is where the higher-impact problems lie and where the business volumes the field can capture are orders of magnitude larger.
The second reason is that Carbon World industries already generate massive data. A modern manufacturing plant generates terabytes of sensor data per day. A connected truck fleet, the same. An agricultural field with smart irrigation and monitoring drones, the same. A telecommunications network, the same. The data exists. What is missing is not the raw material — it is the architectural layer that turns that data into governed autonomous operation. The AI value chain, developed up to link 10, connects. Link 11 is where the agent acts upon the world the data describes.
The third reason is that the crossing opens new technical categories. Operating agents that touch the physical world demands solving problems that purely digital agents do not face. Latency with physical consequences is one: an agent that takes thirty seconds to decide whether to open a valve may be unacceptable; the physical process does not wait, and a delay may mean lost product, equipment damage, or a safety risk. Limited reversibility is another: in the digital world, most actions are reversible (with enough work); in the physical world, once a part has been cut, a fertilizer applied, or a medication injected, there is no rollback. Validation with physical sensors is the third: Layer 4 validation is not done only against data schemas — it is done against physical measurements (temperature, pressure, weight, position), and the agent must read the world, not just APIs, with all the complications of sensors that can fail, drift, or return outlier readings. Resilience to hardware failure is the fourth: a bad sensor, a stuck actuator, an intermittent network — these are everyday conditions in the physical world, and the Trust Infrastructure must treat them as the normal case, not as an exception.
Sub-categories of link 11

The Environment is not uniform. For analytical purposes, we distinguish four sub-categories with distinct properties. Each has its own current market maturity, its leading actors, its specific challenges.
The first sub-category is traditional enterprise systems: ERPs (SAP, Oracle, Microsoft Dynamics), CRMs (Salesforce, HubSpot), DBMS (Oracle, SQL Server, PostgreSQL), HR systems, legacy financial systems. They are digital but institutional — the agent touches them via APIs, but the APIs reflect data models that have been evolving for decades with their own logic. It is the most mature sub-category of link 11. The enterprise integration industry — Zapier, Make, n8n, Workato, MuleSoft — is Core in this sub-link but operates mostly in an agentic model, not an autonomous one. Contemporary products integrate systems but do not operate agentively over them; that is the next generation.
The second sub-category is the industrial physical world — manufacturing and energy. SCADA systems, MES (Manufacturing Execution Systems), PLCs (Programmable Logic Controllers), industrial sensors, line robots, valves, pumps, furnaces, turbines, electrical grids. They are digital but connected to hardware — each API ends, eventually, in a physical piece of equipment that acts upon matter. It is the most promising sub-category in terms of capturable economic value, and simultaneously the most conservative. Industrial processes operate under strict regulations — plant safety, product quality, equipment certifications — that admit no free experimentation. The agent must demonstrate exemplary Trust Infrastructure before being authorized to touch critical systems.
The third sub-category is the mobile physical world — transport, logistics, agriculture. Connected vehicles, fleets, drones, agricultural equipment with sensors. They are digital, connected to hardware, and mobile — adding to the previous challenge intermittent connectivity and geographically distributed coordination. It is the sub-category with the fastest adoption. Logistics fleets (Amazon, FedEx, DHL) already operate with autonomous agents in routing and dispatch. Precision agriculture is advancing rapidly in developed countries.
The fourth sub-category is the biological world. Genomic data, continuous medical monitoring, electronic health records, pharmacovigilance systems, epidemiological tracking. These are data of the biological Carbon World, with extremely strict regulations — HIPAA, health GDPR, pharmaceutical regulations. It is the sub-category with the greatest potential for human impact and, simultaneously, the highest demand for Trust Infrastructure. An agent that interprets medical results operates in territory where an error has a direct human consequence.
Integration patterns for the Carbon World
Operating agents in link 11 demands specific architectural patterns that are not common in the purely digital world. The adaptation of the Agentive Architecture to this territory deserves to be made explicit.
The first pattern is edge computing as distributed Layer 3. Agents that touch industrial processes cannot depend on remote cognition — latency and intermittent connectivity prohibit it. If an agent controlling a valve has to wait for the round-trip to a cloud server before each decision, the system is not viable. Layer 3 — Autonomy — is distributed to the edge: industrial gateways, edge controllers, on-premises devices that keep agents operating locally with eventual synchronization to the center. Botlets are particularly useful here: they execute locally without requiring remote cognition; cognition is invoked only when a change in the environment demands it and connectivity is available.
The second pattern is the digital twin of the physical world. A growing practice: agents operate not over the physical world directly, but over a digital twin that reflects the state of the physical system in real time. The digital twin acts as a Layer 4 abstraction — the agent queries and modifies it; the twin propagates to the physical world when it is safe to do so. The digital twin enables prior validation: the agent can simulate in the twin the effect of a decision before applying it to the real world. This is critical when reversibility is limited — if the simulation shows that the decision produces a problematic result, the agent can adjust before affecting the physical world.
The third pattern is multiple approval levels. Unlike the digital world, where most of the agent’s decisions execute autonomously, in the Carbon World human approval is habitual for high-impact actions. The Trust Infrastructure must model approval layers: the agent decides, a local operator approves, a remote supervisor verifies. Each approval layer adds latency but also adds safety — and in the physical world, where the consequences are irreversible, the additional latency is justified for high-impact decisions.
The fourth pattern is sensors as Layer 4 tools. A peculiarity of the Carbon World: sensors are Layer 4 tools. The agent “queries” a temperature sensor the same way it queries an API. The difference is that the sensor does not return synthetic data — it returns measurements of the physical world, with all the noise, drift, and possible failures that entails. Layer 4 validation must account for measurement quality: detecting sensors with outlier values, sensors that stopped updating, sensors whose calibration has drifted. This differs from the validation of digital API responses, where the datum is right or wrong by clear rules; the sensor may be technically operating yet return readings that do not correctly reflect reality.
Current state of the market
As of early 2026, the link 11 market for agents is fragmented and young. Maturity varies significantly across the four sub-categories, and the leading actors are typically actors from each specific vertical who are adding agentive capability, not agentive-AI actors entering the vertical.
| Sub-category | Market maturity | Representative actors |
|---|---|---|
| Traditional enterprise systems | High (mature integration industry) | Salesforce · SAP · Oracle · Workato · Zapier |
| Industrial world — manufacturing/energy | Low-medium (pilots underway, partial scaling) | Siemens (Mindsphere) · GE (Predix) · PTC (ThingWorx) · Aveva |
| Mobile world — transport/logistics | Medium (large operators with proprietary capabilities) | Amazon Logistics · Tesla · Deere · fleet management providers |
| Biological world | Low (high potential, high regulation) | Tempus · Flatiron · Veeva — actors specialized by sub-vertical |
The visible pattern: in highly regulated sub-categories, the market is one of vertical-specialized actors. In less regulated sub-categories, there is room for horizontal infrastructure not yet built.
The opportunity for agentive infrastructure for the Carbon World
The current AI value chain covers links 1-10 with growing maturity in each. Link 11 remains, for the most part, the territory of legacy actors that were not born designed to integrate with autonomous agents. Siemens, GE, PTC, Aveva — the traditional actors of the industrial world — have the domain knowledge but not the agentive architectural discipline. Their platforms operate principally in a monitoring and human-supervised control model, not in an agentive model where agents execute autonomously.
This creates an architectural opportunity: an agentive infrastructure specified as a gateway toward the Carbon World, offering normalized tools to connect to SCADA/MES/PLC systems, pre-built edge computing patterns, digital twins as a native abstraction, Trust Infrastructure tuned to the regulations of each sub-vertical, and multi-level human approval models.
This infrastructure is not a contemporary product of any actor in the digital AI market. Building it demands deep knowledge of the Carbon World — industrial vocabulary, regulations, operational practices — combined with the architectural discipline of the AI value chain. The actors who achieve it first keep a territory the giants will take years to set foot on.
The AI enterprise gateway connects cognition with digital systems. The enterprise gateway extended to the Carbon World connects cognition with matter.
The evolution frontier
Link 11 is the most visible evolution frontier of the Agentive Architecture. Three open problems the technical community will have to solve for the crossing to become massive.
The first open problem is tool standards for the industrial world. MCP (Model Context Protocol) provides a standard for digital-world tools. No mature equivalent exists for industrial-world tools. The existing protocols — OPC UA, MQTT, Modbus — are of the pre-agentive era: the agent can consume them but they are not designed for it. The open problem is to build an MCP for industry that defines how an agent discovers, authenticates, and operates industrial sensors and actuators with the same uniformity with which it operates digital APIs today.
The second open problem is Trust Infrastructure specialized by vertical. The regulations of the Carbon World — functional safety (IEC 61508, ISO 26262), process safety (IEC 61511), health (HIPAA, FDA), aviation (DO-178C) — demand specific requirements that generic Trust Infrastructure does not fully cover. The open problem is to build vertical extensions of Trust Infrastructure that codify the regulatory requirements of each vertical, formally certifiable. A Trust Infrastructure with IEC 61508 certification can be used in regulated industrial plants; without that certification, the agentive system simply cannot operate in those environments.
The third open problem is model learning in the Carbon World. Foundation models were trained mostly on digital data — text, images, code. Their understanding of the physical world is indirect — they read documentation, they do not operate equipment. The technical frontier of Layer 2 (Cognition) is to train models that understand the Carbon World directly: from sensor data, physical simulations, industrial video, biomedical data. The open problem is to build multimodal models that integrate Carbon World data as a native modality, not as a translation into text.
Strategic implications
For those building on the Agentive Architecture, three operational lessons matter.
The first: the Carbon World is not a distant horizon for all industries. For industries that already operate in the Carbon World — manufacturing, energy, telco, health, agriculture, logistics —, link 11 is the immediate link of their reality. Postponing it is not an option: every agentive-stack decision they make has to account for it from the start. An industrial organization that adopts agentive AI without considering how it will touch its PLCs and SCADAs builds a system that will serve office tasks but not productive operation.
The second: the infrastructure gap is a temporary advantage. For the actors who build an enterprise gateway extended to the Carbon World now, there is a window of several years before the digital-world actors arrive. The current industrial-world actors have the domain knowledge but not the agentive architectural discipline. The digital-world actors have the opposite. Whoever combines both first defines the category. That window eventually closes — the giants acquire capability or build it — but it exists now.
The third: Trust Infrastructure is the filter. In the Carbon World, the filter for entering the market is not the most capable agent — it is the agent with certifiable Trust Infrastructure. A brilliant agent that cannot demonstrate conformance with functional-safety regulations simply cannot operate in a plant. This inverts the typical priority of the digital world, where capability dominates over conformance. In the Carbon World, conformance is a prerequisite; capability is a secondary differentiator once the prerequisite is met.
What comes next
With the market model closed, the book enters its most concrete stretch. Whoever seeks a case where the Agentive Architecture delivers demonstrable value today will find in the next chapter the development of a foundational canonical application. Whoever needs the operational detail to build what has so far been described as principle will find in Chapter 8 the translation into actionable artifacts.