Chapter 4 · Agentive Architecture
Chapters 1 and 2 established the paradigm; Chapter 3 mapped the pre-agentive state from which most organizations will cross the line, and identified which cells of that state migrate and how. This chapter delivers the architectural answer on the side one crosses to. What follows is the Agentive Architecture — the canonical technical design of a system built to live on the right side of the line.
The operative question the architecture answers is concrete: how does one build a system in which an agent can reason, persist, act upon the real world, and account for what it does — without those four functions blurring into an indistinguishable magma? The question is not rhetorical. The blur — fusing cognition, autonomy, action, and governance into a single undifferentiated surface — is exactly what produces the pilots that work in a demo and die on the way to enterprise production. It is the recurring pattern behind the forty percent of cancelled projects we documented in Chapter 2. The root cause of that failure is not technical in the sense of missing algorithms or compute capacity: it is architectural. The systems do not separate concerns, and without separation of concerns there is no way to reason in a disciplined way about what they do.
The answer this book proposes is separation of concerns into four layers, organized in a parallel topology, governed by a cross-cutting trust infrastructure and ordered by a governing principle we will call Agent First. The four layers are not an arbitrary division — each corresponds to a distinct architectural concern that can be reasoned about, specified, and implemented independently. The cross-cutting infrastructure is not an additional layer; it is a property that runs through all four. And the governing principle is not a slogan: it is an operative design rule that orders how any dilemma is resolved.
The precision around parallel topology matters from the first reading. The numbering of the layers (1 → 2 → 3 → 4) suggests a sequence, but the real operation of the system is not linear. Layers 2 (Cognition) and 3 (Autonomy) are parallel paths between Layer 1 (Interaction) and Layer 4 (Access), not stages in series. An operation that enters through Layer 1 may reach Layer 4 by way of Cognition — costly and decisive — or by way of Autonomy — cheap and repetitive, via Botlets. The two paths interact with each other, but neither dominates the other. The section “The parallel topology” develops the consequences.
The urgency of the work is not theoretical. Bain & Company identifies the absence of shared architectural foundations as the root cause of the stall between pilot projects and productive operation. Only twenty-one percent of organizations have mature governance over the agents they operate. The industry still lacks a shared formal architecture that would allow reasoning about these systems with the discipline applied to distributed architectures, operating systems, or networks. This chapter proposes that architecture, not as revealed truth but as a reasoned point of departure that any organization or product can adopt, criticize, extend, or replace.
A necessary clarification before entering the detail. The four layers this chapter develops are an X-ray of the individual agent — the four behaviors every agent must exhibit, whether they materialize in a single monolithic block or are distributed among cooperating components. They are not links in an industrial value chain, nor slots where one assigns a market product to each. The industrial value chain — who participates in the agentive economy and where each actor positions itself — is developed by Chapter 6. The two lenses are both true and cross cleanly when kept separate: the X-ray describes the agent; the chain describes the ecosystem in which the agent operates. Confusing them produces the reasoning errors typical of discussions about the in-market product portfolio — for example, assuming that each layer “belongs” to one particular product.
The four layers, seen together
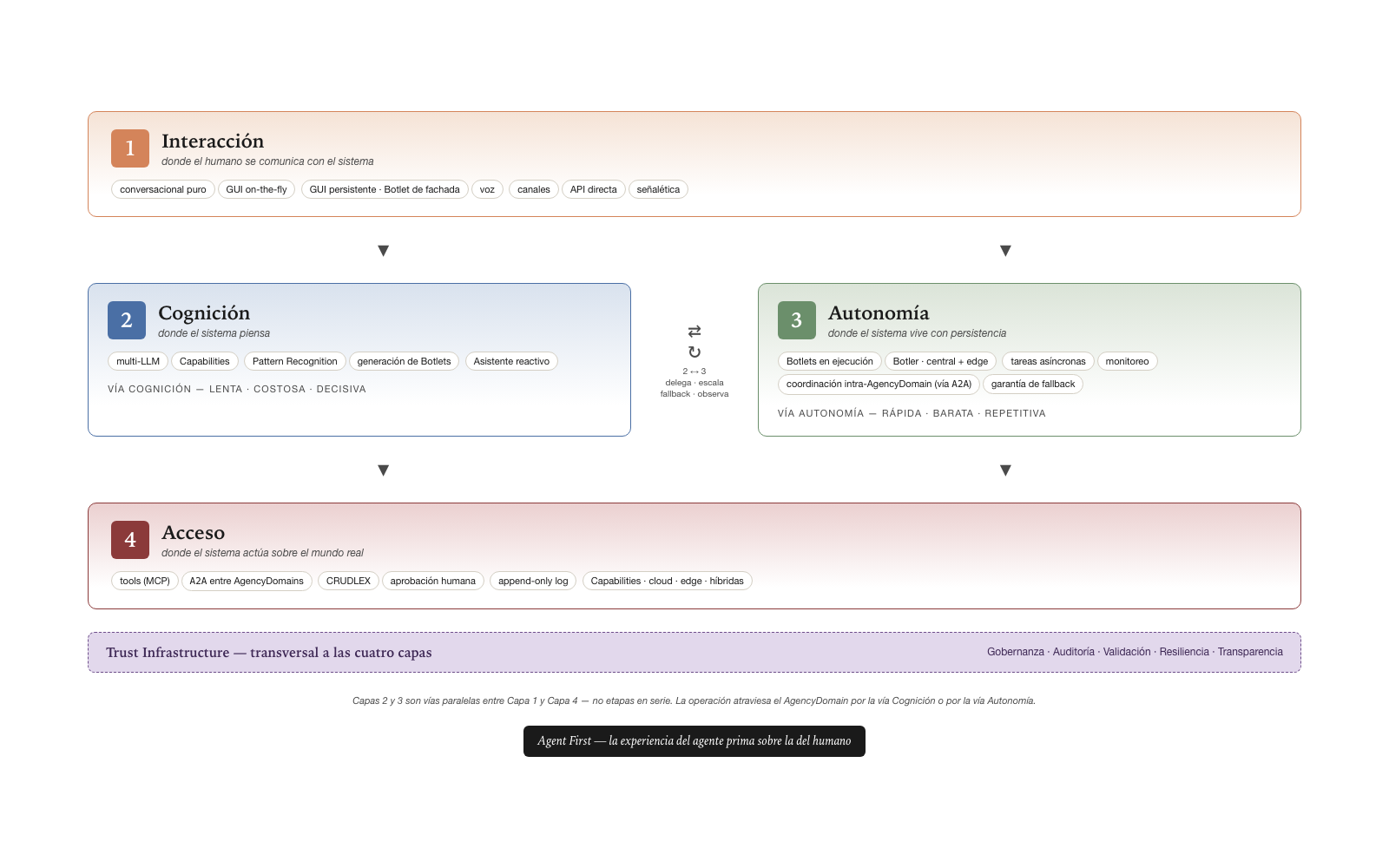
The four layers of the Agentive Architecture are named Interaction, Cognition, Autonomy, and Access. The numbering has didactic value — Layer 1 is the surface the human encounters, Layer 4 is the point where the system touches the real world — but it does not describe the order in which operations traverse the system. Layer 1 is where the human (or the external agent) communicates with the system; Layer 2 is where the system thinks; Layer 3 is where the system lives and persists; Layer 4 is where the system acts. Layers 2 and 3 are parallel paths, not stages in series — the following section develops this.
The separation matters because each layer solves a distinct problem, demands distinct properties, fails for distinct reasons, and evolves at distinct rhythms. A well-architected system can improve its Layer 1 — adding new interaction channels — without touching the other three. It can change its Layer 2 provider — moving from one model to another — without rewriting its Layer 4. It can strengthen its Layer 3 — adding persistence or continuous monitoring — without the Layer 1 human seeing any change. This independence between layers is not abstract elegance: it is what allows the system to evolve over years without a complete rewrite, which is exactly what a production system needs in order to survive beyond the first year.
Separation of concerns is a necessary condition for being able to operate agents with confidence.
Each layer is an architectural concern, not an attribute. The distinction matters: a system that mixes cognition and action into a single surface does not have a “fused layer” — it has an architectural violation that is paid for on the way to production. The difference between an architectural violation and a “simplifying decision” is practical: in a controlled pilot, the fusion works because the operating volume is low and the human supervises closely; in enterprise production, the fusion makes it impossible to diagnose failures, govern policies, scale volume, or change individual components. The system ceases to be explainable, and a system the team cannot explain is a system the organization cannot operate.
Next, before developing each layer, we formalize the topological model that relates them. After that we present each layer with the detail its role demands, the cross-cutting infrastructure — Trust Infrastructure — and the governing principle that orders the design. To close the chapter we describe the evolution frontier, those vectors where the architecture admits extension that has not yet set as normative spec.
The parallel topology
The mental diagram with which most readers enter the four-layer model is the linear stack: the human interacts with Layer 1, Layer 1 invokes Layer 2, Layer 2 produces a plan, Layer 3 executes it persistently, Layer 4 touches the world. That reading is wrong and produces concrete design errors. The real topology is parallel: Layers 2 and 3 are alternate paths between Layer 1 and Layer 4, not sequential stages. An operation traverses the AgencyDomain by one of the two paths — or by both across different stretches — but never by the two in mandatory series.
Each path has its own regime. The Cognition Path is slow, costly, and decisive — it works well for conversation, new decisions, unanticipated cases, situations where the human needs reasoned dialogue and the system needs to combine Capabilities into new patterns. The Autonomy Path is fast, cheap, and repetitive — it works well for executing Botlets over stable patterns, where cognition has already consolidated operative know-how into traditional code that runs without invoking the model. The operating economics of the AgencyDomain depend on the mix: the more operation flows through Path 3, the lower the unit cost; the more flows through Path 2, the greater the capacity to adapt to new cases.
The two paths do not operate in isolation. Three interaction patterns
cross between them and we develop them in their corresponding chapter,
but it is worth naming them here so the topological model is complete.
First, Cognition delegates to a Botlet
(2 → 3): when Pattern Recognition detects a repetitive
operation, cognition generates a Botlet that will execute the pattern
thereafter without invoking it. Second, the Botlet escalates
fallback to Cognition (3 → 2): when the
environment changes and the Botlet fails, cognition rescues the
operation, regenerates the Botlet with the variant incorporated, and
returns execution to Path 3. Third, Cognition observes the
Botlet log (2 ← 3): the Botlet emits events and
metrics that cognition consults when the human asks or when it needs to
reason about the behavior of the system as a whole.
The parallel topology has five practical consequences worth retaining. The first is that the offline mode of an edge node — a physical site without a network — is trivial to explain under this model: the Cognition Path typically depends on cloud and goes inactive without a network; the local Autonomy Path stays active because its Botlets run on the edge against a local DB and local Connectors. The operation traverses the AgencyDomain by the path that remains alive. What without a parallel topology would seem to require a separate system, under it emerges as a structural property.
The second is that cognitive economics becomes evident. The organization does not pay for “the AgencyDomain” — it pays for the mix of paths its operation triggers. Decisions about which patterns to consolidate into Botlets are explicit economic decisions, not an implementation detail. The fine-grained view of this economy distinguishes three rungs of cost, not two: within the Autonomy Path coexist units of zero marginal cost (Botlets) and units of bounded, budgeted inference (Agentlets, Chapter 5 §7) — the middle rung between muscle memory and full Cognition.
The third is that Trust Infrastructure is exercised on both paths, not only on the one that passes through Cognition. The linear model could suggest that cognition filters everything that reaches Layer 4. The parallel model makes clear that Path 3 also passes through Trust — the policies are applied before invoking Layer 4 regardless of which path the invocation comes from. A Botlet that invokes DTE-SII — the electronic invoicing of Chile’s tax regulator — passes through the same Trust validations as the cognition that would do it.
The fourth is that the parallel topology distinguishes two types of Botlets that the linear model confused. Operational-facade Botlets are invocable from Layer 1 — a button on a POS, a command line, an endpoint — with a stable contract and human identity propagated toward Layer 4. Cognition internal-tool Botlets are invocable only from Layer 2 — cognition composes them into plans that it itself executes. Both live in Layer 3, but their invocation surface is distinct and so are their governance properties.
The fifth is that the path
Layer 1 → Layer 3 → Layer 4 ceases to be an exception and
becomes a canonical path. A specialized surface — a
floor POS, a kitchen screen, a cashier dashboard, an industrial
operation panel — that invokes a senior Botlet and produces an action in
Layer 4 traverses this path without touching Layer 2. Under the linear
model, that looked like a bypass of cognition, a local decision with a
caveat. Under the parallel topology, it is one of the
AgencyDomain’s two structural paths, perfectly legitimate, with
its own Trust and observability properties.
The agent’s three times

The parallel topology describes where each operation lives within the AgencyDomain. This section describes when the agent operates — the temporal dimension that the topology alone does not capture. Without this second reading, capacity plans confuse background activity with online activity, and the agent ends up mis-sized: either it is asked for continuous service with no windows to stay capable, or so much maintenance time is reserved that effective operation suffers.
The spec recognizes three canonical times of the agent. All three are real and simultaneous activities in a productive system; they differ in their regime, their urgency, and their cognitive economics.
Preparation
Preparation is the time in which the agent creates and improves its capabilities outside the service window. It refines its catalog, improves its cognitive capabilities, studies the environment, regenerates Botlets that detected drift, incorporates new variants, trains Pattern Recognition on observed traffic, tunes Capabilities from field feedback. It is the agent’s mise en place — the work that sustains the quality of service without being visible to the user.
Preparation operates predominantly on the Cognition Path (Layer 2) over consolidated data, not over the burst of the moment. It is typically batch / off-peak: it runs when effective operation does not demand all available cognition, or on separate cognitive infrastructure. Its metrics are about quality — how good the catalog is, how accurate the recent Botlets are, how complete the Capabilities are.
Attention
Attention is the time in which the agent interacts with users or events in real time. Layer 1 active, live conversation, execution of Botlets that sustain operation, escalations where appropriate. It is the critical path — where the organization feels the agent, where the SLA matters, where the cost of error materializes.
Attention operates over both paths (Cognition and Autonomy) according to the pattern, with priority, with bounded latency and high availability. Its metrics are operational — user satisfaction, response latency, resolution rate without escalation, mean time between escalations.
Engineering
Engineering is the bridge between Preparation and Attention: the time in which the agent converts latent capacity into executable capacity for a concrete case. It receives a request, identifies which Capabilities apply, configures a seed Botlet for the specific context, validates its execution over real data, deploys it to the corresponding environment, observes the result. It is configuration and orchestration work, not general reasoning nor pure service.
Engineering operates on a mix of paths: it uses cognition to decide composition but generates artifacts that persist in Autonomy. It is typically medium term — minutes to hours, not seconds — and has its own rhythm distinct from the rhythm of Attention. Its metrics are about coverage — what fraction of requests can be served with configured seed Botlets, what success rate they have on first deploy, how many iterations on average they require.
Implications for reasoning about the system
The distinction among the three times has three practical consequences for the operation of the AgencyDomain.
First, scheduling of cognitive capacity. Cognition is a costly and finite resource. The organization consciously chooses how much is allocated to each time: Attention demands bounded latency and high priority; Preparation tolerates batch and exploits demand valleys; Engineering occupies an intermediate band. Without this distinction, cognition is allocated by temporal proximity to the request and Preparation is relegated — the agent stops improving itself, its catalog ages.
Second, distinct metrics per time. A single “agent performance” dashboard lies: Preparation is measured by aggregate catalog quality and Attention is measured by operational satisfaction. Mixing them hides where the problem is when something goes wrong. The mature organization instruments the three times separately.
Third, availability model. A well-operated agent is not 100% in Attention. It needs Preparation windows. The promise “always-available agent” is better understood as “Attention always available” — Preparation operates behind it. This distinction is what allows offering service SLAs without cannibalizing the background work that sustains quality.
The agent does not attend at all times — but it can attend at any time because it devotes time to preparing itself.
Required properties
| Property | Level |
|---|---|
| Explicit recognition of the three times in operation | MUST |
| Separate metrics per time (Preparation, Attention, Engineering) | MUST |
| Reserved Preparation windows, not optional | SHOULD |
| Scheduling of cognitive capacity by time priority | SHOULD |
| Traceability in the log of which time executed which operation | SHOULD |
Layer 1 — Interaction
Layer 1 is responsible for all communication between humans and the system. It is pure interface, with no business logic. The human who interacts with an agentive system never directly touches the other three layers — they only see Layer 1, and Layer 1 translates their intentions toward the layers that execute. It sounds simple stated that way, but the design of Layer 1 contains almost all the decisions that determine whether the human will use the system frequently or abandon it after the first week.
The canonical modalities of Layer 1 are six, and a serious agentive system typically supports more than one. The textual conversational modality — direct chat with the agent — is the most visible and the one most contemporary commercial products implement first. It is an efficient modality for analytical or drafting tasks, where the human formulates their requests well. The voice conversational modality — virtual assistants, calls, audio-bots — is critical for use cases where the human has their hands busy or needs to interact while on the move. Corporate channels — Slack, Teams, WhatsApp, email — function as conversational surfaces when the human does not want to open a specific application to talk to the agent, but prefers the agent to appear where the human already is. The programmatic API enables external systems to invoke the agent without human intermediation — a critical pattern for cases where the agent is invoked by another system, not by a person.
The two least-discussed but structurally important modalities are the generated GUI and passive signage. Passive signage is surfaces that communicate information continuously without requiring human interaction — panels, operation dashboards, ambient displays. The human does not operate: they read. This modality is central for operational use cases where the agent must keep the human informed without waiting for the human to ask. The generated GUI deserves extended treatment because it is where the reading of the agentive paradigm is most easily confused. The section that follows develops it.
Three GUI regimes in the agentive Layer 1
A recurring — and wrong — reading of the agentive paradigm concludes that the Agentive World implies abandoning all graphical interface: if everything is conversation with the agent, GUIs disappear. That reading confuses two distinct things. What disappears is not the GUI — it is the GUI pre-created by human teams in pre-agentive times. The GUI continues to exist when operation requires it; what changes is its mode of existence: it goes from being a fixed template coded before use to being a surface generated by cognition according to the needs of each interaction.
The productive Layer 1 of the Agentive World distinguishes three regimes of generation:
1. Pure conversational. The agent responds in text or voice; sufficient when the information is sequential and the decision is flexible. A customer asking about their balance, a user asking to draft an email, an operator checking the status of a process — all cases where conversation is the correct modality. There is no generated graphical surface because none is needed.
2. GUI generated on-the-fly. The agent composes a graphical surface adapted to the immediate task: a view, a form, a panel, a dashboard. The GUI lives as long as the task lasts; the next time the human needs something similar, the agent can regenerate it differently according to context. It is the correct modality when the information is dense or multidimensional, when the decision demands visual comparison, or when the human must manipulate several elements simultaneously. It is what is usually understood as “dynamic GUI”.
3. Persistent GUI generated as a Botlet. For repetitive operational roles — a cashier at peak hour, a kitchen panel, a cashier dashboard, an industrial monitoring screen — the agent generates a stable surface and consolidates it as a facade Botlet — a Botlet that lives in Layer 3 and exposes that surface with a stable contract in Layer 1. It is generated GUI that persists because the usage pattern is stable, the operational role is clear, and response speed is critical. It remains agentive: the agent can regenerate it when the environment changes (new products, new rules, new flow), exactly as any other Layer 3 Botlet regenerates when its environment changes. The difference from the traditional GUI is that no human UI/UX team designed it: cognition generated it because the usage pattern justifies it.
The three modalities coexist in a mature agentive system. The distinction among them is not hierarchical — it is not that the persistent GUI is “better” than the conversational one. It is fit to the usage pattern: conversation when the case is new or flexible, on-the-fly GUI when the task is dense but occasional, persistent GUI when the role is operational and repetitive.
The GUI does not disappear in the Agentive World. What disappears is the pre-created GUI. Every GUI in an agentive Layer 1 is generated by cognition — some ephemeral, others stabilized as facade Botlets.
The practical consequence of the distinction is operational. Without
it, “agentive” is interpreted as “everything is chat” — operationally
impractical for roles that need speed. A cashier at peak hour does not
converse to ring up a sale; a cook does not chat with the ordering
system; a plant operator does not ask the agent by voice to show the
process status. With the distinction, those roles operate over
persistent GUIs generated as facade Botlets — stable,
fast, specialized surfaces that invoke Layer 3 Botlets directly (the
Layer 1 → Layer 3 → Layer 4 path that the parallel-topology
section formalizes). The system remains entirely agentive; what changes
is that cognition does not participate in every operational interaction
— it does participate in the initial generation of the facade, it does
when the facade needs to regenerate, it does when the operator escalates
a new situation.
The facade Botlets connect naturally with the seed/emergent distinction of Chapter 5 §2: persistent GUIs typically correspond to seed facade Botlets — Layer 3 Botlets with their surface in Layer 1, generated by cognition at the design team’s request as part of the initial product, just like the seed transactional Botlets of the same layer.
Composition of the surface · shell, view, operation
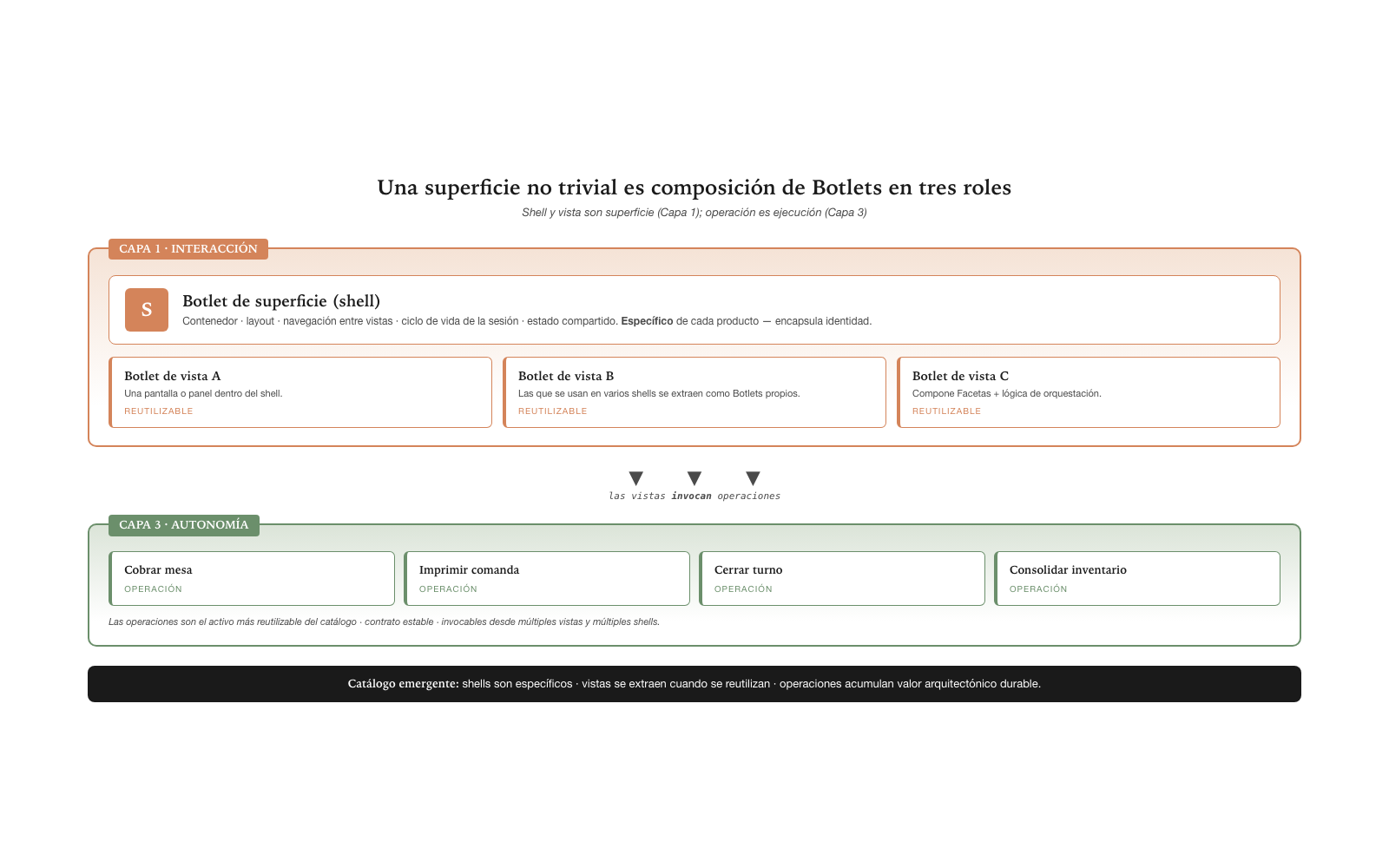
A non-trivial surface is not a monolithic Botlet. It is composition. Reading it this way makes explicit what is reused, what is specific, and where each piece lives within the architecture; treating it as a single block condemns the design of the productive Layer 1 to intuition and wastes reuse across surfaces.
The spec recognizes three canonical roles that compose a surface:
Surface Botlet (shell) — Layer 1. It is the container: layout, navigation among views, session lifecycle, shared state. The product-specific part. There is typically one shell per principal operational role — the floor POS shell, the cashier panel shell, the mobile executive dashboard shell. The shell is the least reusable: it encapsulates product identity.
View Botlet — Layer 1. A screen or panel within the surface. A surface has one or several views; those used in several shells are extracted as their own Botlets. The “shopping cart” view, the “order detail” view, the “shift summary” view. Views are highly reusable — the same “order detail” view can appear inside the POS shell and inside the cashier panel shell.
Operation Botlet — Layer 3. The business execution that the view invokes. It lives in Autonomy, not in Interaction. “Charge a table”, “print a kitchen ticket”, “close a shift”, “consolidate inventory” — these are operations in Layer 3, not surfaces in Layer 1. An operation can be invoked from multiple views within multiple shells. Operations are the most reusable asset of the catalog.
The key distinction: shell and view are surface (Layer 1); operation is execution (Layer 3). A surface is a composition of Layer 1 Botlets that orchestrate and invoke Layer 3 Botlets.
Emergent catalog. This decomposition is a prerequisite for reasoning about the catalog of reusable pieces: operations accumulate in the catalog over time and form the most durable architectural asset; reusable views are extracted and catalogued; shells remain specific but their construction is accelerated because they assemble existing pieces. Without the explicit decomposition, everything is treated as an “application feature” and reuse is not exploited.
Multi-view Information Product · drill-through. An
Information Product (PI) — the
manifestation that an informational operation Botlet leaves on being
consumed — is not necessarily a single piece: it can be composed of N
named views connected by
drill-through, the navigation-with-context that narrows
— never widens — what the viewer can already see. The normed description
of the PI — the multi-view composition, the data-anchored /
no-bypass property, and its canonical example — lives in Chapter 5 §2,
alongside the manifestation that begets it.
Facet · atomic primitive of Layer 1

So far Layer 1 has been described in terms of generation regimes (pure conversational, on-the-fly, persistent as a Botlet) and composition (shell, view, operation). What is missing is to name the atomic unit with which these surfaces are built: the Facet — an atomic reusable component of Layer 1: a catalog-picker, a calendar, a clickable map, a slider, a freehand drawing board. It is an instrument, not a process: the agent picks it up while thinking — in live conversation or inside a view Botlet — and drops it when it is done.
The Facet is not a Botlet: it has no fallback
guarantee, no 95/4/1 cycle, no maturity phases — if it
fails, the agent returns to conversation. Offering a Facet is, moreover,
a cognitive act of the agent, not a pre-programmed feature: cognition
estimates whether the information is obtained faster visually than
verbally, and decides. The full canonical distinction, the two uses, and
the heuristics of that decision live in Chapter 5 §6, where the Facet is
formalized as a primitive.
If the human opens applications to do their work, we are not in the Layer 1 of the Agentive World.
The statement gathers Satya Nadella’s thesis from the BG2 podcast of December 2024, which we already cited in Chapter 1. It is an operative calibration exercise with an additional nuance under the three regimes we have just defined: the question is not whether there is a GUI or not, nor how pretty it is. The question is who generated it. If the GUI was pre-created by a UI/UX team in traditional application sprints, it is not agentive Layer 1. If the GUI was generated by cognition — ephemeral or persistent as a Botlet —, it is.
Three required properties distinguish a well-designed Layer 1 from a collection of ad hoc adapters. Being channel-agnostic means that the conversation logic does not depend on the medium: the same agent must manifest coherently in chat, voice, on-the-fly GUI, without the developer rewriting the logic for each channel. If the agent knows the customer’s data and preferences, that information is the same regardless of whether the customer is speaking by voice from their car or by chat from their laptop. Register adaptation requires that the agent understand the channel’s register — formal in corporate email, concise in chat, verbal in voice — without that adaptation living in conditional code. It is a property of cognition manifesting through Layer 1, not of Layer 1 itself. And context persistence guarantees that the conversation survives the change of channel: a human who begins by chat and continues by voice keeps the thread. Without this property, the system fragments the human experience into channel silos, and the human perceives the “agent” as multiple disconnected agents — exactly the friction the agentive paradigm promises to eliminate.
Layer 2 — Cognition
Layer 2 is where the system thinks. It is the agent’s brain — interpretation, reasoning, planning, application of specialized know-how, the decision to delegate. If Layer 1 is the agent’s face, Layer 2 is what lies behind the face.
The canonical components of Layer 2 are five. The first is multi-LLM: cognition is not tied to a single model provider. Different providers, models, modalities — text, multimodal — and architectures — LLM, symbolic, hybrid — coexist under a common contract. The reason is operative before it is philosophical: the landscape of cognition providers evolves on the scale of months, and a system tied to a single provider accumulates debt every time that provider loses competitiveness against a new entrant. A well-designed multi-LLM system allows migrating between providers without rewriting the agent’s logic.
The second component is Capabilities — units of modular, composable know-how, organized in a hierarchical tree. Cognition selects and applies Capabilities according to the task. Capabilities are codified professional know-how — accounting know-how for a financial agent, regulatory know-how for a legal agent, operative know-how for a support agent. We develop them in detail in Chapter 5. For now it suffices to retain that Layer 2 does not operate with monolithic knowledge — it operates by selecting modules of specialized know-how and combining them according to the case.
The third component is Pattern Recognition — detection of repetitive patterns in the agent’s activity. The capacity is inspired by the neurobiological architecture of human memory; Chapter 5 §2 develops the parallel (Squire and Wixted) alongside the Botlet cycle. When the agent recognizes a repetitive pattern in the activity — the same task executing with variable frequency but stable structure —, it triggers the generation of a Botlet that automates that task without requiring additional cognition each time. Pattern Recognition is the entry to the Botlet cycle, which we develop in Chapter 5.
The fourth component is Botlet generation itself. Cognition decides when to delegate repetitive tasks to Layer 3 — where Botlets execute without invoking cognition. This decision is not trivial: a cognition that delegates too much loses flexibility when the environment changes; a cognition that delegates too little saturates its resources on tasks that traditional code executes better. The calibration of when to generate a Botlet is an emergent property of mature cognition.
The fifth component is the reactive Assistant — the agent operating in response-to-request mode. It waits for input from the human, responds, moves to the next turn. This mode is pure Layer 2 — cognition without autonomy, unlike the proactive mode that lives in Layer 3. The Assistant vs Autonomous Agent distinction is developed by Chapter 5 §5.
The specification further recognizes two modes of access to cognition: Tokens — the system centralizes credentials, billing, and policies; the natural mode for background Autonomous Agents — and Subscription — the user’s assistant (Claude, ChatGPT, Copilot, Gemini) accesses under the user’s own subscription, consuming no tokens from the system. The two coexist in the same system, the spec requires declaring which mode applies to which component, and confusing them is the most recurrent source of economic errors in an agentive deployment. The full formalization of both modes lives in Chapter 5 §1.
Under fixed Subscription plans, Botlets are the architectural mechanism for extending autonomy without saturating the plan: an agent that executes its daily work via Botlets, reserving cognition for when the environment changes, can operate in continuous background without exhausting the quota. This makes the Botlet an economic lever, not just a technical optimization. Chapter 5 §2 develops this economics of the subscription.
A complementary property of Layer 2 is the configurability of the cognition provider. A conformant agentive architecture must allow the system to use a default provider — the one the AgencyDomain operator has chosen as its base economics — but admit its substitution by a provider brought by the end client. The industry uses the term BYOModel (bring your own model), analogous to the BYOK (bring your own key) or BYOIP (bring your own IP) pattern of the cloud field. The architectural consequence is that the agent’s spec — its Capabilities, its tools, its Trust Infrastructure policies — must be independent of the cognition runtime. This enables multi-tenancy with heterogeneous cognition (different clients operating on the same substrate with different model providers) and respects the client’s cognitive sovereignty: the organization decides who processes its prompts. The spec requires BYOModel as a SHOULD property: not every implementation supports it today, but architectures that aspire to operate in regulated markets will have to incorporate it within a foreseeable timeframe.
A final note on the evolution frontier of Layer 2: the specification admits agnostic cognition — symbolic, hybrid, multimodal. Contemporary implementation is predominantly LLM-centric, but the architecture does not require it. The formal extension of Layer 2 to other cognitive substrates — symbolic systems for formal problems, multimodal models that integrate sensor data, hybrid architectures that combine both — is a strategic horizon, not a short-term one. The importance for the architect is not to tie the design of the other layers to the assumption that Layer 2 will always be LLM. The architecture must survive the change.
A second note on the role of the semantic layer — a concept Chapter 2 already introduced with its figures. The quality of cognition depends critically on the quality of the information that feeds it. A serious agentive architecture contemplates the semantic layer as a necessary integration between Layer 2 and the Environment’s data (Layer 4): without it, cognition operates over inconsistent representations of reality and produces answers that look coherent but fail at what matters.
Layer 3 — Autonomy
Layer 3 is where the agent lives. It is persistent life, continuous execution, action on its own initiative. Where the Autonomous Agents dwell — proactive, not reactive. Distinct from the Assistant that lives in Layer 2 and waits to be invoked.
The Autonomous Agent is distinguished from the Layer 2 Assistant by an operational difference: the Assistant responds when asked, with no persistent state nor Botlets of its own; the Autonomous Agent pursues objectives without continuous human input, maintains state, regenerates Botlets, and lives in the background. Chapter 5 §5 develops the distinction.
The canonical components of Layer 3 are six. Proactive
processing is the heart of the layer: the agent does not wait
for orders; it pursues objectives. Asynchronous tasks
are operations that execute in the background without blocking any
conversational thread. Continuous monitoring detects
anomalies, events, thresholds that trigger action. The Lets in
execution — the packaged units that inhabit the layer — are two
sibling species: the Botlets — the agent’s muscle
memory operating, canonical cycle 95/4/1: 95% normal
execution, 4% change detected in the environment that makes the Botlet
fail, 1% regeneration of the Botlet by cognition — and the
Agentlets — packaged routine judgment, units whose body
invokes bounded inference for tasks recurrent in form but interpretive
in every instance (Chapter 5 §7 formalizes them). The
Botler is the framework runner that executes the Lets
of both species — a piece invisible to the user and to the agent itself,
a responsibility of the implementation. Intra-AgencyDomain
coordination —via the A2A protocol— is
communication among specialist components that live in the same
computational space: coordination among specialist agents, dynamic
delegation, exchange of results.
And the non-negotiable property that defines the layer: fallback guarantee. If a Botlet fails catastrophically, cognition executes the task manually. The process never stops. This guarantee distinguishes the agentive system conformant to this specification from any fragile “AI automation”. An organization that delegates operation to agents must be able to trust that an isolated failure does not stop its business. Resilience is what makes that trust reasonable. Without a fallback guarantee, Botlets are fragile scripts disguised as innovation; with a fallback guarantee, they are operational pieces the organization can lean on.
Without Layer 3, the agent only reacts. With Layer 3, the agent can anticipate.
Layer 3 demands three strong properties that any implementation must satisfy. Persistence between sessions ensures that the agent’s state survives disconnections, restarts, and migrations. An agent that loses its state when the server restarts is not an Autonomous Agent — it is an Assistant with a long-running process. Execution isolation ensures that the Lets — Botlets and Agentlets — run under sandboxing appropriate to the environment — containers, WASM, MicroVMs according to the security-versus-overhead trade-off. A Botlet generated by cognition is new code; it must operate under strict confinement before touching sensitive resources. Structural resilience ensures that no failure of an individual Botlet stops the agent’s operation. One Botlet fails, another replaces it, cognition regenerates, and the system continues.
There is a recurring temptation, especially in teams coming from the traditional software world, to treat Layer 3 as “where the workflows run” — the agentive analog of a classic orchestrator like Airflow or Temporal. The analogy is misleading because traditional workflows are static: they are defined by code a human wrote, they execute the steps in the foreseen order, they fail when something departs from the flow. The agentive Layer 3 is dynamic: the Botlets it executes were generated by cognition, they regenerate when the environment changes, and the organization trusts that the whole operates coherently without any human having explicitly written the flow. A classic orchestrator is an executor of human instructions; Layer 3 is an executor of instructions that cognition itself generated — and that changes the entire governance model of the system.
The interface by which Cognition commands this layer is
internal and lives within the same
AgencyDomain: Layer 2 commands Layer 3 — Cognition operating
its own muscle memory. The natural transport is MCP
(Cognition is an LLM agent and MCP is the LLM↔︎tool
protocol): the Botler exposes MCP
server(s) and Cognition is the client. This
is not A2A — A2A is the
relation between AgencyDomains (agents), federation or external, not the
internal operation of an agent over its own runtime. The development of
this interface and of its operation API lives in the AgencyDomains
specification (Chapter 5 §1) and in the Botlets chapter.
An additional structural property of Layer 3 — central for systems
with multiple physical presence — is that it admits geographic
distribution within a single AgencyDomain. A system that
operates 7 restaurant locations, 50 bank branches, or 200 healthcare
points of service does not need 7, 50, or 200 independent AgencyDomains
— it needs a single AgencyDomain with Layer 3
distributed between a central Botler (orchestration, planning,
reporting, global-decision Botlets) and N edge Botlers (local
transactional Botlets with a local DB and an event queue toward the
center), coordinated by intra-AgencyDomain coordination —via the
A2A protocol— between Botlers of the same AgencyDomain.
This is not A2A federation between distinct AgencyDomains;
it is internal distribution of Layer 3 within a single
AgencyDomain. The complete spec of the pattern lives in Chapter 5
§1.
Layer 4 — Access
Layer 4 is where cognition becomes real action upon the world. It is the agent’s power of execution over systems, data, and external agents. The point where every decision of the agent must pass through governance before touching the world. If Layer 3 is where the agent lives, Layer 4 is where the agent acts.
The canonical components of Layer 4 are eight and we lay them out carefully. Tool servers are tools the agent can invoke to touch external systems — email, calendars, repositories, databases, ERPs, CRMs, public APIs, files. The contemporary canonical protocol is the Model Context Protocol (MCP), introduced by Anthropic in November 2024 and progressively adopted as an open industry standard. The rapid adoption of MCP — faster than almost any recent open protocol had achieved — reflects a real need: the field lacked a standard for connecting agents with tools, and all serious actors understood that fragmentation was a problem rather than an advantage. Connectors are the know-how to access source systems — the legacy API of the pre-agentive world brought into Layer 4 as an access capability with execution power, not as cognitive know-how (that lives in Layer 2 as a Capability). It is the materialization in the architecture of the destiny that the Bounded Concerns Architecture assigns to the API cell: it persists, intensifies, and is repositioned as a Connector.
A2A between AgencyDomains enables
interaction between agents that live in distinct computational spaces —
federation between AgencyDomains of different organizations, integration
with agents of external providers. The Trust Infrastructure
exercised at the point of action is probably the most critical
component of Layer 4: governance, audit, validation, resilience, and
transparency are exercised here, where the agent is about to act. The
detailed description of Trust Infrastructure comes later in this chapter
and is developed in detail in Chapter 5. The CRUDLEX
permissions are the canonical model of granular control:
Create, Read, Update, Delete, List, Execute, applicable by user, agent,
or context. The complete operational description of CRUDLEX lives in
Chapter 8. Human approval is optional, configurable by
policy, for critical operations — sending external email, financial
transfer, irreversible modification. Intelligent routing and
semantic cache optimize the cost and latency of invocations.
The immutable append-only log is the auditable record
of every action of the agent, with complete lineage for later
reconstruction.
Layer 4 turns cognition into real action with governance.
The required properties of Layer 4 are four and all are mandatory for an enterprise production system. The first is non-repudiation: every action is recorded with the agent’s identity, context, and result. When the system executes an operation, it must afterward be possible to reconstruct which agent executed it, on behalf of which human or organization, with what authorization, and with what result. Without non-repudiation, there is no possible audit and no regulatory defense. The second is reversibility where applicable: critical operations have a rollback or compensation mechanism. Not all operations are reversible — a sent email or an executed transfer typically are not —, but when reversibility is technically possible, it must be designed from the start. The third is policy before execution: no action executes without having passed through the governance plane. The policy is evaluated before, not after. A system that records decisions after making them and then waits for the human to correct them has a governance model that arrives too late. The fourth is uniform observability: every invocation produces traces, metrics, and events in the same format. Without uniformity, observability data is operationally unconsumable.
Layer 4 is where most agentive projects fail, according to the field data of Chapter 2. The structural reason: teams coming from the traditional software world treat Layer 4 as an “API gateway with permissions”, and it is not that. A traditional API gateway operates over human requests — the human makes the request, the gateway validates permissions, the system executes. The agentive Layer 4 operates over requests generated by agents acting autonomously. Validation cannot assume that a human supervised the request beforehand; it must assume that the agent decided on its own, and that the human will not see it until the audit log. This demands levels of validation, recording, and approval that traditional systems did not need.
Trust Infrastructure — the cross-cutting axis
Trust Infrastructure is not an additional layer. It is cross-cutting to all four. Without Trust Infrastructure, agent pilots die on the way to enterprise production — and “die” is not a metaphor; it is what produces the wave of cancellations Chapter 2 documents. Trust Infrastructure is the difference between experimenting and operating.
Five pillars constitute Trust Infrastructure. Governance defines configurable policies, CRUDLEX permissions, human approval for critical operations, AI registry. It is exercised principally in Layer 4, cross-cuttingly in the rest. Audit maintains an immutable append-only log, a trace of every action, lineage of decisions, identity tagging per action. It is exercised in Layer 4 and cross-cuttingly. Validation detects hallucinations, validates responses, prevents prompt injection, executes DLP and tokenization. It is exercised in Layer 2, in Layer 4 and — over the bounded inference of Agentlets — in Layer 3. Resilience guarantees fallback, handles errors, sandboxes the Lets. It is exercised in Layer 3 and cross-cuttingly. Transparency delivers complete observability, metrics, end-to-end traces, proactive alerts, governance dashboards. It is cross-cutting to all four layers.
The detailed description of each pillar — its canonical mechanisms, its required properties, its operationalization into concrete policies — lives in Chapter 5 §4 and in Chapter 8 (which operationalizes the five pillars into policies, the complete CRUDLEX model, the format of the append-only log, human-approval protocols). In this chapter it suffices to retain the fundamental architectural property: Trust Infrastructure is not added after the agent works — it is designed from the start, in the architecture itself.
The urgency of Trust Infrastructure is no longer only architectural — it is regulatory: the state and international frameworks that demand it are developed in Chapter 5 §4. The question is no longer whether regulators will require trust infrastructure — it is whether the organization can demonstrate it auditably when asked.
The state of the field with respect to governance is documented with figures in Chapter 2: most of the organizations that operate agents today are not prepared to defend what their agents do. What matters here is the architectural consequence of that diagnosis: if governance is not designed from the start, it is not built afterward.
The governing principle — Agent First
Faced with any dilemma, the agent’s experience is prioritized over the human’s. The agent is the primary user; the human’s needs are resolved in a management layer without degrading what the agent sees and can do.
The Agent First principle is a design-governance rule that orders any architectural dilemma. It inverts the logic of traditional software design, where the human is always the primary user and everything is designed so they can operate it. In the Agentive Architecture, the APIs, the schemas, the errors, and the control flows are designed first for the agent’s consumption. The human surface — settings, dashboards, administrative interfaces — is secondary and does not condition the architectural decisions.
The inversion is not rhetorical — it has concrete operative implications. Any new capability of the system is specified first as a tool with a declarative JSON schema, then as a GUI if applicable. Errors are structured and actionable: codes and messages designed so the agent decides the next step, not so the human “reads the log”. Idempotency where applicable: the agent’s retries must be safe without requiring defensive logic in the caller. Uniform pagination and filters across tools: a consistent format, predictable for the agent. Machine-readable documentation: the public documentation is consumable by the agent as context, not only legible by humans.
Agent First is a governance rule. Any design dilemma that violates it requires explicit, documented justification. When the team faces a decision where “this would be easier for the human operator, but makes it harder for the agent”, the default answer is to prioritize the agent. The exception must be argued and recorded. Without an explicit governance rule, the inertia of traditional software pushes all decisions toward the human side, and the system ends up being just another application with agentive makeup.
The structural reason behind the principle: in the Agentive World, the frequency with which the system interacts with agents is orders of magnitude greater than the frequency with which it interacts with humans. An agentive system in production typically has millions of agent invocations against hundreds of human operations. Optimizing for the minority case — the human — degrades the majority case — the agent — exponentially. Agent First is recognition of that asymmetry.
The evolution of agents

The architecture admits three evolutionary phases in the sophistication of the agent. Different organizations find themselves in different phases, and the conversation about architecture changes significantly according to the current phase.
Phase one is the specialized agents: one agent per domain. Each with its specific Capabilities, its clear role, its limited surface. The financial agent operates over cashflow; the customer-service agent operates over tickets; the operations agent operates over inventory. This is the current phase of the market. Most agents in production at the start of 2026 are phase-one specialized agents. The reason is practical: it is the easiest phase to govern — the scope is narrow, the risk is contained, the use case is clear.
Phase two is the orchestrator
agents: one agent coordinates multiple specialists. Dynamic
delegation according to the task. The orchestrator agent does not solve
the problem directly — it decomposes the problem, identifies which
specialists can solve each part, delegates, integrates the results. This
is a transition phase that some leading actors are already exploring,
especially in cases where tasks cross domains — a customer-service case
that requires a query to finance, validation with operations, and a
response to the end customer, for example. Phase two demands a robust
Layer 3 so the specialized agents can coordinate intra-AgencyDomain, via
the A2A protocol.
Phase three is the multi-specialist agents: deep multi-domain expertise in a single agent. The future phase — it requires a maturity of Capabilities and Pattern Recognition that the industry has not yet reached. A multi-specialist agent does not decompose the problem by delegating — it solves it directly by integrating know-how from multiple domains. The difference from the orchestrator is ontological: the orchestrator is a coordinator of specialists; the multi-specialist is a deep specialist in many things at once. The Capabilities in the multi-specialist case form a much broader and deeper tree, and cognition must be able to navigate it efficiently.
The architecture is the same across the three phases. What changes is the complexity of cognition and the depth of the Capabilities tree. A well-designed system in phase one can evolve to phase two without a rewrite — by adding more specialized agents to the computational space and enabling intra-AgencyDomain coordination. A well-designed system in phase two can evolve to phase three when Capabilities mature — by fusing trees of specialized know-how into broader trees. This capacity for evolution without rewriting is an emergent property of the four-layer design. A poorly designed system — with fused layers — needs a complete rewrite to go from phase one to phase two, and that is typically when projects collapse.
The computational scope — AgencyDomains
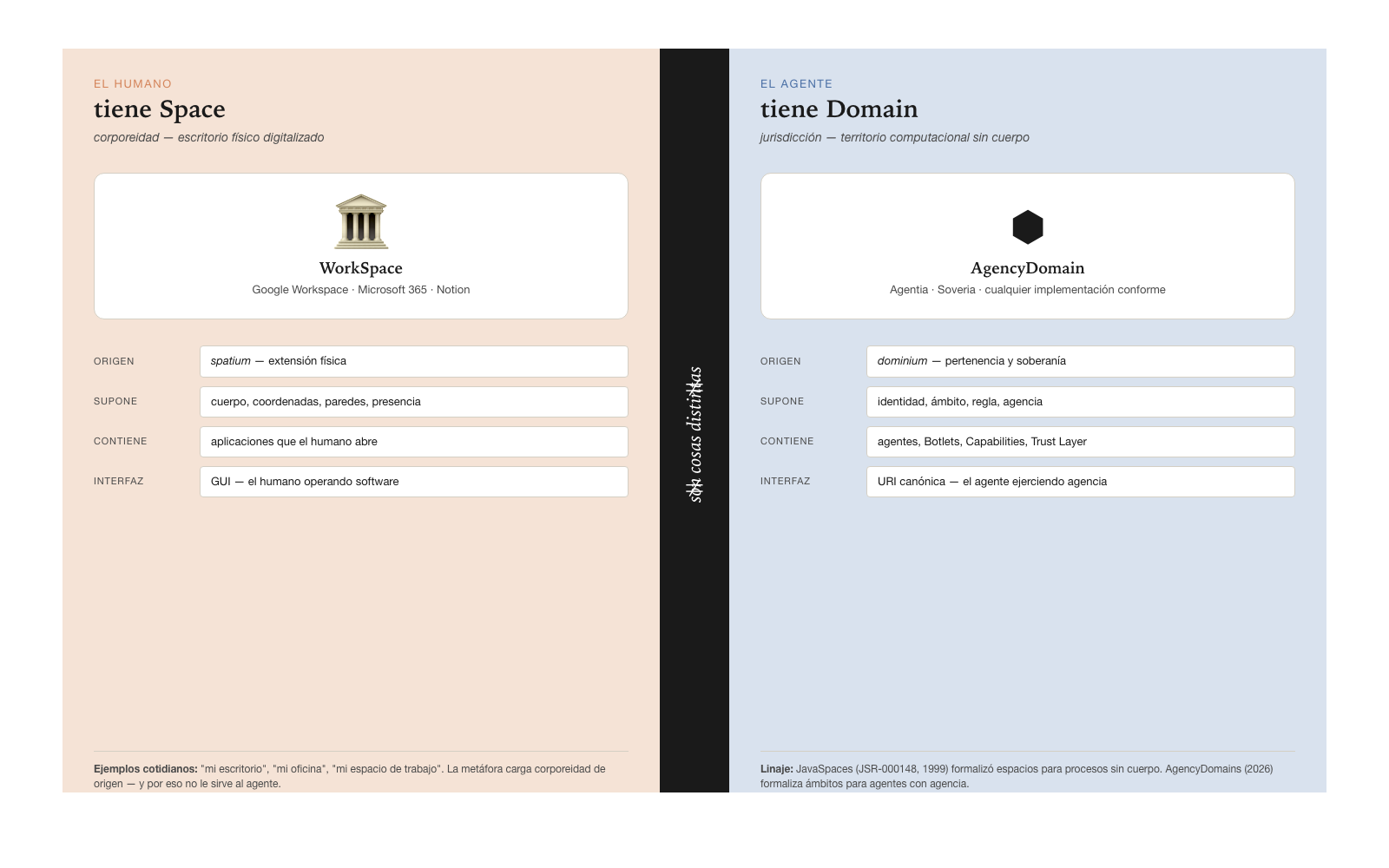
Foundational premise — Space ≠ Domain
Where the human has a Space —corporeality inherited from the physical desktop, extended by the industry to WorkSpace—, the agent has no body: it exercises agency over a Domain, a scope of computational jurisdiction where its identity rules, its Capabilities apply, and its Botlets run. Chapter 5 §1 develops the complete derivation of this premise.
Where the human has a Space (WorkSpace), the agent has a Domain (AgencyDomain).
The AgencyDomain as a formal construct
The architecture materializes in a formal construct: the AgencyDomain — a computational scope where autonomous agents dwell. It defines how agentive environments ought to be built — layers, cycles, primitives, interfaces — without prescribing a specific implementation; its historical parallel (JavaSpaces, the JSR-000148 spec of 1999) and the full derivation of the Space ≠ Domain premise live in Chapter 5 §1.
The formal specification of AgencyDomains lives in its dedicated document, which is the first section of Chapter 5. In this chapter it suffices to retain that the Agentive Architecture, seen as a concrete technical construct, is instantiated in AgencyDomains. When we speak of “the agentive system”, we refer to an instance of an AgencyDomain that materializes the four layers, exercises Trust Infrastructure, and respects the Agent First principle.
The specification covers aspects such as the identity and addressing
model of agents and Botlets, the agent’s lifecycle within the scope,
intra-AgencyDomain coordination and A2A between
AgencyDomains (both via the A2A protocol), federation
between AgencyDomains (how two distinct scopes collaborate), and the
tenancy and isolation model. All these details are developed by Chapter
5 §1.
Reference implementations
This architecture admits multiple implementations. The first coordinated implementation is the ultraBASE portfolio, where the responsibility for the four layers materializes through cooperating products — without each layer being exclusively assigned to one product. Each product contributes one or more of the agent’s behaviors; the integrated stack composes them so the agent exhibits all four.
Other actors who adopt this architecture will have their own implementations — each valid insofar as it respects the four layers, exercises Trust Infrastructure, and honors the Agent First principle.
The book deliberately avoids describing the specific implementation of ultraBASE within its chapters, so as not to confuse the formal architecture with its particular implementation. The Epilogue, in “What is NOT in this book”, develops why that separation preserves the claim to an industry standard.
Evolution frontier
The architecture admits legitimate extension over time along three
technical horizons: non-LLM cognition —symbolic,
hybrid, multimodal— which the Layer 2 frontier already anticipated
above; federation between AgencyDomains —the
A2A between non-related scopes, today an emergent
capability and not a consolidated spec—; and the Carbon
World —connecting Layer 4 to the physical world (IoT,
industrial systems, manufacturing), link eleven of the value chain that
Chapter 6 §3 develops—. The Epilogue develops the four living frontiers
of the architecture, these three technical ones plus the institutional
one.
The three vectors define the platform’s innovation frontier. All three are sustained by the market projections documented in Chapter 2: mass penetration of agents in enterprise applications toward 2026, significant autonomous decision-making toward 2028, collective capital betting an entire decade on the agentive direction. The question this architecture answers — how these systems are built with discipline — only becomes more urgent with each passing quarter.
The four layers are the architectural answer to the paradigm. But the layers do not stand on their own — they need reusable pieces to populate them so an implementer can build against them with discipline. Chapter 5 delivers those pieces — eight canonical technical primitives that constitute the constructive vocabulary of a conformant agentive system: AgencyDomain as computational space, Botlet as the agent’s muscle memory, proto-Botlet as its pre-forged piece, Agentlet as packaged routine judgment, Capability as the tree of cognitive know-how, Trust Infrastructure as the trust infrastructure, the Assistant vs Autonomous Agent distinction as the operative axis, and the Facet as the atomic unit of Layer 1. Whoever completes the two chapters holds the set of formal constructs with which the agentive category can be reasoned about and built.
A note on the numbering of the primitives: throughout the book the Facet is labeled the sixth canonical primitive, the proto-Botlet the seventh canonical primitive and the Agentlet the eighth canonical primitive. Those ordinals indicate the order in which each primitive was incorporated into the canon, not their position in the enumeration above, where the proto-Botlet appears alongside the Botlet as its pre-forged piece and the Agentlet alongside both as its sibling species.
Visual summary
The four layers in parallel topology, with their principal components, the cross-cutting infrastructure, and the governing principle:
| Layer | Role | Principal components |
|---|---|---|
| 1 · Interaction | where the human communicates with the system | textual conversational · voice conversational · channels · direct API · generated GUI (on-the-fly · persistent as facade Botlet) · signage |
| 2 · Cognition (slow · costly · decisive path) | where the system thinks | multi-LLM · Capabilities · Pattern Recognition · Botlet generation · reactive Assistant |
| 3 · Autonomy (fast · cheap · repetitive path) | where the system lives with persistence | Botlets and Agentlets in execution · central + edge Botler · asynchronous tasks · monitoring · fallback guarantee |
| 4 · Access | where the system acts upon the real world | tools (MCP) · Connectors (cloud · edge · hybrid) · A2A between AgencyDomains · CRUDLEX · human approval · append-only log |
Trust Infrastructure is cross-cutting to the four layers (Governance · Audit · Validation · Resilience · Transparency). Layers 2 and 3 are parallel paths between Layer 1 and Layer 4 — not stages in series —, and the governing principle is Agent First.