Chapter 5 · Primitives
The four layers of Chapter 4 are the architectural answer to the paradigm, but they do not stand on their own: they need reusable pieces to populate them. This chapter delivers those pieces — the canonical technical primitives of the Agentive World. Each section formalizes one: the AgencyDomain (§1), the Botlet with its proto-Botlet (§2), the Capability (§3), the Trust Infrastructure (§4), the Assistant vs Autonomous Agent distinction (§5), the Facet (§6), and the Agentlet (§7).
AgencyDomains
Chapter 4 introduced the notion of the AgencyDomain as the formal construction where the Agentive Architecture materializes. This section develops that notion with the detail of a specification. What follows is the closest thing to a normative spec that this book delivers — a document an implementer can take and build from, knowing what is mandatory and what is optional, what properties it must satisfy and what decisions it may make freely.
Foundational premise — Space ≠ Domain
Words carry corporeality. Space is born describing physical extension: office, desk, home, city. When a human says “my space”, they invoke place — coordinates, walls, presence. The enterprise software industry extended the word to WorkSpace — Google Workspace, Microsoft 365, Notion — to name the collection of solutions that digitize what the person does at their physical desk: reading email, scheduling meetings, writing documents, filing. WorkSpace is the digital prosthesis of the human Space; both terms carry the same corporeality of origin.
The agent has no body. It does not open applications. It does not
work on a desktop. It does not dwell in a physical space nor in any
metaphor of one: it exercises agency over a scope of
computational jurisdiction — digital territory where its
identity rules, its Capabilities apply, and its Botlets run. The Latin
word that names exactly that is Domain
(dominium: scope of belonging and sovereignty).
Where the human has Space (WorkSpace), the agent has Domain (AgencyDomain).
The historical parallel — JSR-000148
The historical parallel holds: just as JavaSpaces (JSR-000148, 1999) formalized distributed spaces for Java systems without tying the implementation to a vendor, this specification formalizes AgencyDomains for agentive systems with the same agnosticism. Multiple implementations arose over JavaSpaces — GigaSpaces, Blitz, others —, all mutually compatible because they respected the common contract. The spec outlived the implementations; the implementations evolved without the spec needing constant rewriting. That is the pattern AgencyDomains seeks to replicate for the agentive field. This book proposes the spec; implementations that comply with it may call themselves conformant AgencyDomain.
The difference in name from its predecessor is not a rupture — it is
precision. A Java Space was computational space for bodiless
processes; an Agency Domain is a scope of jurisdiction for
agents with agency. What in 1999 was named “space” is better named in
2026 as “domain”. The term AgencyDomain carries meaning
in each word. Agency — agency, in its philosophical sense of
the capacity to act — denotes that the scope is inhabited by entities
with their own initiative, not by passive processes. Domain —
dominium: scope of belonging and sovereignty — denotes
territory where the agent’s identity rules, not an ephemeral process.
The union of the two words names exactly what the spec defines: a scope
where the agent exercises agency.
Terminological note: in commercial lore (brand, sales, customer communication) the short form
DomainreplacesAgencyDomain. It is the Apple iCloud / CloudKit, Stripe Connect / Account pattern: short brand + long technical name. The two forms are interchangeable; each record picks its own.
Definition
An AgencyDomain is a computational space with its own identity where autonomous agents and running Botlets dwell, where the Capabilities that give them their know-how are hosted and executed, and where the resources that sustain them live — cognition, tools, persistent storage. It constitutes the minimal unit of deployment of a productive agentive system.
The Capability is not a support resource: it is cognitive know-how, a first-order inhabitant of the space alongside the agent and the Botlet. The relation between the two primitives is direct — an AgencyDomain hosts and executes Capabilities; a Capability runs in a host AgencyDomain.
The spec defines how those spaces must be built — layers, identity, life cycles, communication protocols — without prescribing a specific implementation. Multiple implementations are admissible as long as they respect the contract. One implementation may use Kubernetes for containerization; another may use isolated microVMs; another may use native processes on a single machine. All three are valid if they satisfy the fundamental properties the spec requires.
Where an agent lives, that place is an AgencyDomain. Where there is no AgencyDomain, there is no life of the agent — there is model invocation.
The quote above distinguishes the AgencyDomain conformant to this specification from any “endpoint that invokes an LLM”. An endpoint that invokes an LLM responds to requests; an AgencyDomain hosts agents that live. The difference is structural, not one of degree. A system without persistent state, without its own Botlets, without the capacity for proactive operation, is not an AgencyDomain — it is a service. It can be a useful service, but it does not satisfy what the agentive field requires.
The minimal unit matters. An AgencyDomain is not a subcomponent of something larger — it is the atomic unit of deployment. A larger agentive system is a collection of cooperating AgencyDomains, possibly under a single governance or federated across distinct owners, but each one preserves its own identity and its fundamental properties.
Fundamental properties
Every implementation that intends to call itself an AgencyDomain conformant to this spec must satisfy five fundamental properties. Satisfaction is not optional — a system that does not meet them is not an AgencyDomain, but something else with another name.
The first property is own identity. Each AgencyDomain has a unique identity — a canonical URI — that distinguishes it on any network. The identity survives the restart of the space, migration across infrastructures, and a change of implementation. If an AgencyDomain migrates from one cloud provider to another, its identity does not change: the agents that inhabit it, the humans who interact with it, the other AgencyDomains that invoke it, all continue to recognize it as the same space. The identity is stable, not ephemeral.
The second property is materialization of the four layers. An AgencyDomain materializes the four layers of the Agentive Architecture — Interaction, Cognition, Autonomy, Access — and exercises cross-cutting Trust Infrastructure. The materialization may be distributed technically — the layers may live in distinct infrastructures, on distinct physical servers, even across distinct cloud providers —, but responsibility for all four rests with the space. There is no conformant AgencyDomain that delivers only three layers, or that delegates some layer to an external system without assuming responsibility for it. Completeness is non-negotiable.
The third property is persistence. The state of the AgencyDomain — active agents, running Botlets, capabilities data, audit logs — survives disconnections, restarts, and migrations. An AgencyDomain is not an ephemeral process; it is a persistent entity. If the system restarts for maintenance, the agents that were active continue where they were. If the connection to an external service drops temporarily, the agent waits and resumes. Persistence is what makes the AgencyDomain a place and not a process.
The fourth property is isolation. Each AgencyDomain has an explicit boundary. Internal resources — compute, memory, data — are not accessible from outside except through defined interfaces. Communication with the exterior passes through Layer 4 (Access) and is recorded. Isolation is not only security — it is fault containment: an AgencyDomain that goes down does not affect other AgencyDomains that share infrastructure, because the boundary contains the failure. The implementation models that offer isolation vary — from strong sandboxing via MicroVMs to lighter isolation via Kubernetes namespaces —, but the explicit boundary always exists.
The fifth property is addressability. Both the AgencyDomain and the agents and Botlets that inhabit it are addressable via predictable URLs. The canonical syntax the spec adopts is:
{domain}/ → the space itself
{domain}/agents/{agent} → an agent that lives in it
{domain}/agents/{agent}/botlets/{botlet} → a specific Botlet
{domain}/tools/{tool} → a tool exposed via Layer 4Addressability matters for two operational reasons. First, it is the basis of A2A communication — an agent that needs to invoke another agent does so through its canonical URL, with no need for ad hoc discovery. Second, it is the basis of MEO (Model Engine Optimization — the SEO→MEO shift Chapter 6 §1 develops): the frontier models that learn to reference AgencyDomains do so through predictable URLs that appear in their training corpus. Chaotic or unstable URLs make the AgencyDomain invisible to models that were not trained with its specific map.
Canonical data model

The internal structure of a conformant AgencyDomain follows a canonical model that the spec defines with precision (figure above).
Each component of the model has its specific role. Identity maintains the information that identifies the space to the world: its canonical URI, the credentials with which it authenticates to external systems, the root policies that no agent may contravene. Agents is the collection of agents that live in the space, each with its assigned Capabilities, its running Botlets, and its persistent state. Capabilities Registry is the tree of capabilities available to the agents of the space — shared know-how that agents can invoke according to their role. Tools Registry is the collection of tools that Layer 4 exposes outward — the interface through which the AgencyDomain touches external systems. Trust Layer exercises cross-cutting governance and audit — policies, append-only log, validation mechanisms. Cognition Bindings are the bindings to the cognitive resource — which model provider the AgencyDomain invokes, under what credentials, with what usage policies.
The notion of Account is a commercial concept superimposed on the technical model. An Account may own multiple AgencyDomains. The spec treats the Account as an opaque entity; each implementation defines its specific semantics — a client company, a federated organization, an individual user. The distinction between AgencyDomain (technical) and Account (commercial) matters because it allows the technical model to evolve without the commercial model needing a rewrite each time.
The regime model

One aspect that significantly distinguishes the AgencyDomains spec from more limited agentive solutions is its recognition of three possible regimes of an AgencyDomain, analogous to the regimes of cloud computing. The three regimes are technically equivalent in their internal structure; what changes between them is the access boundary, not the architecture.
The private regime corresponds to an AgencyDomain where the space and all its components live within a perimeter controlled by an organization. There is no public access. The agents of the space are invocable only from within the organization. The data of the space do not leave the perimeter. It is the conceptual analog of the Private Cloud — the organization has total control of its resources, pays for that control in terms of operation but gains in terms of sovereignty. The private regime is typical for cases where the organization operates sensitive data or complies with regulation that demands local residency.
The public regime corresponds to a publicly accessible AgencyDomain. Agents, Botlets, and tools are invocable from outside the perimeter. The AgencyDomain has a public URL and the agents that inhabit it are registered in a directory that any external system can query. It is the conceptual analog of the Public Cloud — maximum accessibility, maximum exposure, a different operating model. The public regime is where the network of agents cooperates openly with the rest of the internet.
The hybrid regime is a combination of the two preceding ones. A hybrid AgencyDomain has components in a private perimeter and components accessible publicly via proxy. Sensitive data remain private, but the interface that exposes capabilities to the exterior is available publicly. It is the conceptual analog of the Hybrid Cloud — the organization chooses what to expose and what to retain, balancing sovereignty and accessibility. The hybrid regime is typical for organizations that need to offer public agents to their customers but want to keep customer data within the corporate perimeter.
What is critical about this regime architecture — and it is a strong property of the spec — is that the technical structure of the AgencyDomain is the same across all three regimes. An agent operating in a private AgencyDomain is technically equivalent to one operating in a public one; what changes is the regime, not the capability. A Botlet executing in private can move that same code to a public regime without rewriting. This structural uniformity enables natural migration between regimes — an agent can graduate from private to public or vice versa without changing its internal logic. The organization governs the regime; the agent’s logic never notices.
This natural-migration property is structurally important because it decouples the architectural decision (how the agent is built) from the commercial decision (in which regime it operates). An organization can begin building agents in the private regime while it validates their usefulness, and migrate them to the public or hybrid regime when maturity justifies it. The initial architectural investment is not lost in the transition.
To fix the idea with concrete instances as of May 2026 — both from the house portfolio; the general frame for implementations lives at the close of this spec and in Chapter 9 —: Agentia operates AgencyDomains in the private regime for firms that keep their agents within the corporate perimeter; Soveria operates AgencyDomains in the public regime where enabled agents are hosted with a public identity and a canonical URL; the same agent can graduate from the first to the second without a technical rewrite, keeping the agent’s spec intact and moving only the regime.
Cognition access models
The spec recognizes two coexisting modes by which the components of the AgencyDomain access the cognitive resource (Layer 2). The two modes coexist because they solve distinct problems, and a serious AgencyDomain typically operates both simultaneously for distinct components.
The first mode is Tokens. The flow is: AgencyDomain → cognitive resource, centralized and billed to the space. The AgencyDomain centralizes credentials, billing, and policies. It provides cognitive access to all its active components. This mode applies when agents must operate in the background without user intervention, when the organization wants central control over consumption and costs, or when multiple agents share a single cognition provider. The organization that operates Autonomous Agents in the background — agents that monitor continuously, respond to events, execute asynchronous tasks — needs Tokens, because there is no human available whose individual subscription would subsidize the invocations.
The second mode is Subscription. The flow is: user’s Assistant → cognitive resource, via the user’s own subscription. The assistant the user interacts with — Claude, ChatGPT, Copilot, Gemini — accesses the cognitive resource directly under the user’s subscription. The AgencyDomain consumes no tokens from the resource. This mode applies when the user already has an active subscription to the cognition provider, when the AgencyDomain exposes tools and data to the user’s assistant without centralizing cognition, or when the AgencyDomain’s operating economics favor minimizing inference costs. The organization that adopts ultraPRO — an implementation from the house portfolio (Chapter 9): the secure integrator between the user’s agent and corporate systems — typically operates in Subscription mode, because users bring their own subscriptions to the cognition providers.
Both modes coexist in mature systems. A single AgencyDomain may operate user Assistants (Subscription mode) and background Autonomous Agents (Tokens mode), simultaneously. The spec requires the AgencyDomain to explicitly declare which mode applies to which component. The explicit declaration prevents the most recurrent source of economic errors in agentive systems: accidental confusion between modes, where an Autonomous Agent that should operate on Tokens ends up billing against the user’s subscription and exhausts it in hours, or where an Assistant that should operate on Subscription ends up billing against the AgencyDomain and consumes tokens it should not.
The role of Botlets in the cognitive economy deserves particular
emphasis. In fixed-Subscription plans, Botlets are the mechanism for
achieving autonomy without additional cost: the Botlets’
95/4/1 cycle is the economic basis of autonomy under
subscription. The full development of this economy lives in §2.
Agent life cycle
An AgencyDomain conformant to the spec manages the complete life cycle of each agent that inhabits it. The cycle has six canonical phases, and each transition between phases is recorded in the Trust Layer’s append-only log.
The provisioning phase is where the AgencyDomain creates the agent. It assigns identity, associates the initial Capabilities the agent may invoke, registers the agent in the space. The agent is born, in system terms, when this phase completes successfully. If the phase fails — by credential error, by name conflict, by quota restrictions —, the agent never comes to exist.
The bootstrap phase is where the agent enters operation. It loads its persistent state if it exists — if the agent had been hibernated or restarted, it recovers its prior context. It establishes bindings with the cognition and the tools it will use. It verifies that its Capabilities are available. After bootstrap, the agent is ready to respond or to operate proactively, according to its mode.
The reactive operation phase corresponds to the agent operating in Assistant mode. Layer 2 active. The agent responds to human requests: each request arrives, the agent processes it by invoking cognition and possibly Capabilities, returns a response. Between requests, the agent is passive — it consumes no active compute, executes nothing. This phase is the most frequent in systems that operate primarily with Assistants.
The proactive operation phase corresponds to the agent operating in Autonomous Agent mode. Layer 3 active. The agent pursues goals in the background, monitors events, executes Botlets when appropriate, escalates to the human when thresholds demand it. Pattern Recognition generates and maintains Botlets as the agent identifies repetitive patterns. This phase is where the model “intelligence goes to people and acts on their behalf” materializes — the agent is active continuously, the human intervenes only when necessary.
The hibernation phase is where the agent is left paused but persistent. State saved. It consumes no active compute. This phase is useful when an agent need not operate for extended periods — a support agent that only operates during business hours, for example, hibernates overnight and reactivates with the start of the next day. Hibernation preserves the context without spending resources.
The decommissioning phase is where the AgencyDomain retires the agent. The agent’s state is archived or deleted according to policy. The Capabilities it had assigned are released. The agent’s identity remains recorded in the historical log, but the agent ceases to exist as an operative entity. The decommissioning phase is important because it formally closes the cycle — a “decommissioned” agent is not the same as a “forgotten” agent. The record of the decommissioning is what allows, weeks or months later, an auditable reconstruction that the agent existed, what it did, and why it ceased to exist.
Communication between agents
The spec reserves the term A2A
(agent-to-agent) for the relation between agents,
and an agent is an AgencyDomain. The A2A relation is, therefore,
between AgencyDomains — between distinct agents, each
with its own identity and agency. Communication within a single
AgencyDomain is not A2A in this relational sense: the components that
sustain it are runtimes of the same agent, not distinct agents. The spec
thus distinguishes two planes: the intra-AgencyDomain
plane (an agent commanding its own runtimes and muscle memory) and the
A2A plane (an agent invoking another agent). When the
A2A protocol is used within an
AgencyDomain as transport between runtimes, one says via the
A2A protocol — the proper name of the protocol —,
never “internal A2A”, so as not to attribute agency to runtimes that do
not have it.
How does the Cognition command its muscle memory? — Layer 2 ↔︎ Layer 3 interface
The Cognition (the LLM agent, Layer 2)
commands its own muscle memory — the Botler, a Layer 3
runtime without agency — through an internal interface
within the same AgencyDomain. It is the Layer 2 → Layer 3 relation: the
Cognition specializes, manifests, consumes, and controls the Botlets
that the Botler hosts. The natural transport of this interface is
MCP (LLM↔︎tool): the Botler
exposes one or more MCP servers and the Cognition is the
client. This interface is not A2A — it
does not cross the AgencyDomain boundary nor mediate between distinct
agents; it is an agent operating its own execution substrate.
A2A is reserved for AgencyDomain↔︎AgencyDomain.
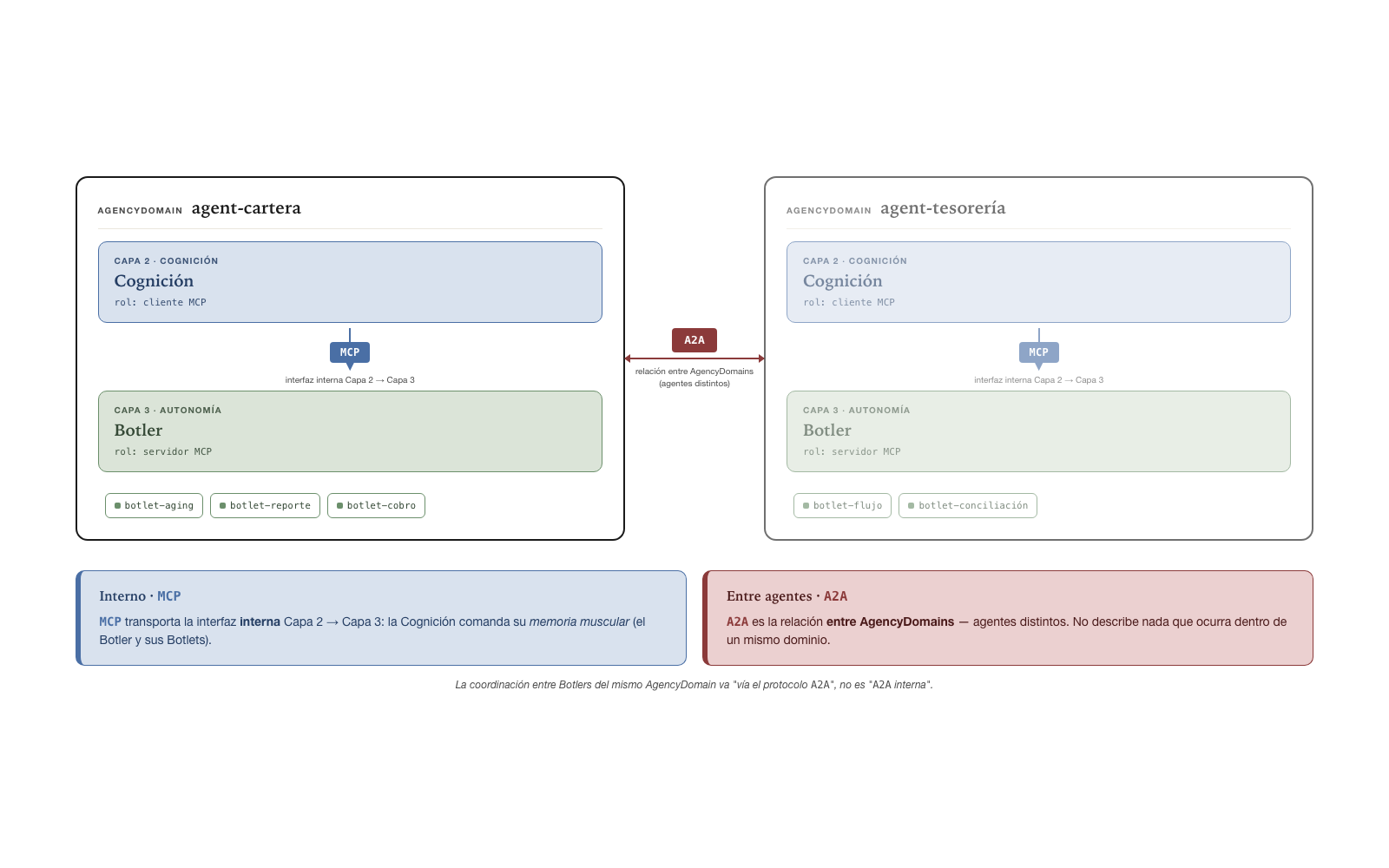
What properties does intra-AgencyDomain communication require?
All communication between components that live in the same
AgencyDomain — be it the Layer 2 → Layer 3 interface via
MCP, be it the transport between Botlers via the
A2A protocol — satisfies three properties the spec
requires. The first is uniform addressability — any
component of the space can be invoked by its canonical URI, with no need
for ad hoc discovery. The second is message typing —
messages have a declarative, verifiable schema; the sender declares the
schema and the receiver verifies that the message complies with it
before processing it. The third is traceability — every
invocation is recorded in the append-only log with the identity of
sender and receiver. If a component invoked another, the system knows
who, when, and with what content.
How do distinct agents communicate? — A2A between AgencyDomains
A2A communication between AgencyDomains
is between agents that live in distinct AgencyDomains.
This modality requires additional protocols that the spec recognizes as
necessary but does not fully normalize in its version 1.0. The open
protocols for A2A are in evolution — the industry is
converging toward certain directions, but full consensus has not
arrived. What the spec does define is that A2A between
AgencyDomains requires three mechanisms: discovery —
how an AgencyDomain publishes the agents it offers to be invoked
externally; cross-authentication — how two
AgencyDomains verify each other’s identity; semantic
resolution — how two AgencyDomains that may have distinct
glossaries negotiate the meaning of tools and capabilities when they
interoperate.
The complete normative specification of A2A between
AgencyDomains — discovery protocol, federated message format, identity
resolution — is open work. Reference implementations
may adopt emerging protocols, for example federated MCP, or
the A2A protocol proposed by Google. When
there is industry consensus on a specific protocol, a future version of
this spec will incorporate it as normative. For now, serious
implementations treat A2A between AgencyDomains as an
emerging capability, not as consolidated spec.
Federation between AgencyDomains

Federation is the formal mechanism by which multiple AgencyDomains collaborate as a network. It must be distinguished from the close but distinct concept of the Cluster — multiple instances of the same AgencyDomain operating as a coordinated set. Cluster is operational; Federation is architectural.
| Concept | Granularity | Example |
|---|---|---|
| Cluster | Multiple instances of the same AgencyDomain | Three instances of one firm’s AgencyDomain sharing load |
| Federation | Multiple distinct AgencyDomains collaborating | Firm A’s AgencyDomain invokes an agent from firm B’s AgencyDomain |
Federation enables ecosystems of agents that cross organizational boundaries. An AgencyDomain can invoke agents from another AgencyDomain, exchange data, coordinate operations — all under explicit trust models that each participant establishes. This extends the agentive model beyond the boundaries of an individual organization and allows cooperation networks that resemble the open internet more than closed corporate systems.
The normative specification of federation is open work. Version 1.0 of the spec recognizes the necessary mechanisms without prescribing their specific implementation:
An open discovery protocol must exist, possibly over DNS and well-knowns. When an AgencyDomain wants to discover what agents another AgencyDomain offers, it must be able to query a standard endpoint and obtain the list. The spec does not prescribe the exact format of the endpoint — that decision depends on the industry consensus that has not yet arrived.
Cryptographic identity standards for AgencyDomains and agents are necessary. Each federated AgencyDomain must be able to authenticate cryptographically — not by a shared API key, but by a verifiable mechanism that requires no central authority. Candidate technologies include W3C DIDs (Decentralized Identifiers), X.509 certificates, blockchain-based mechanisms. The spec admits any that satisfy the fundamental property: verifiable identity without central authority.
Explicit trust models are a requirement. When two AgencyDomains interact, each must declare the level of trust it extends to the other: what operations it permits, what data it shares, what audit it exercises. Trust is not binary — an AgencyDomain may trust another for low-impact invocations but not for high-impact ones, or may trust it for reads but not for writes. The spec requires these models to be explicit and configurable, not implicit in code.
Conflict resolution when two AgencyDomains apply contradictory policies. If AgencyDomain A invokes an agent from AgencyDomain B, and the policies of A and B have conflicts — A permits the operation but B prohibits it, for example —, there must be a clear mechanism to resolve the conflict. The spec defines that priority always belongs to the receiving AgencyDomain — that is, B in this case. The sender may request; the receiver decides.
Distributed Layer 3 — canonical pattern for multiple physical presence
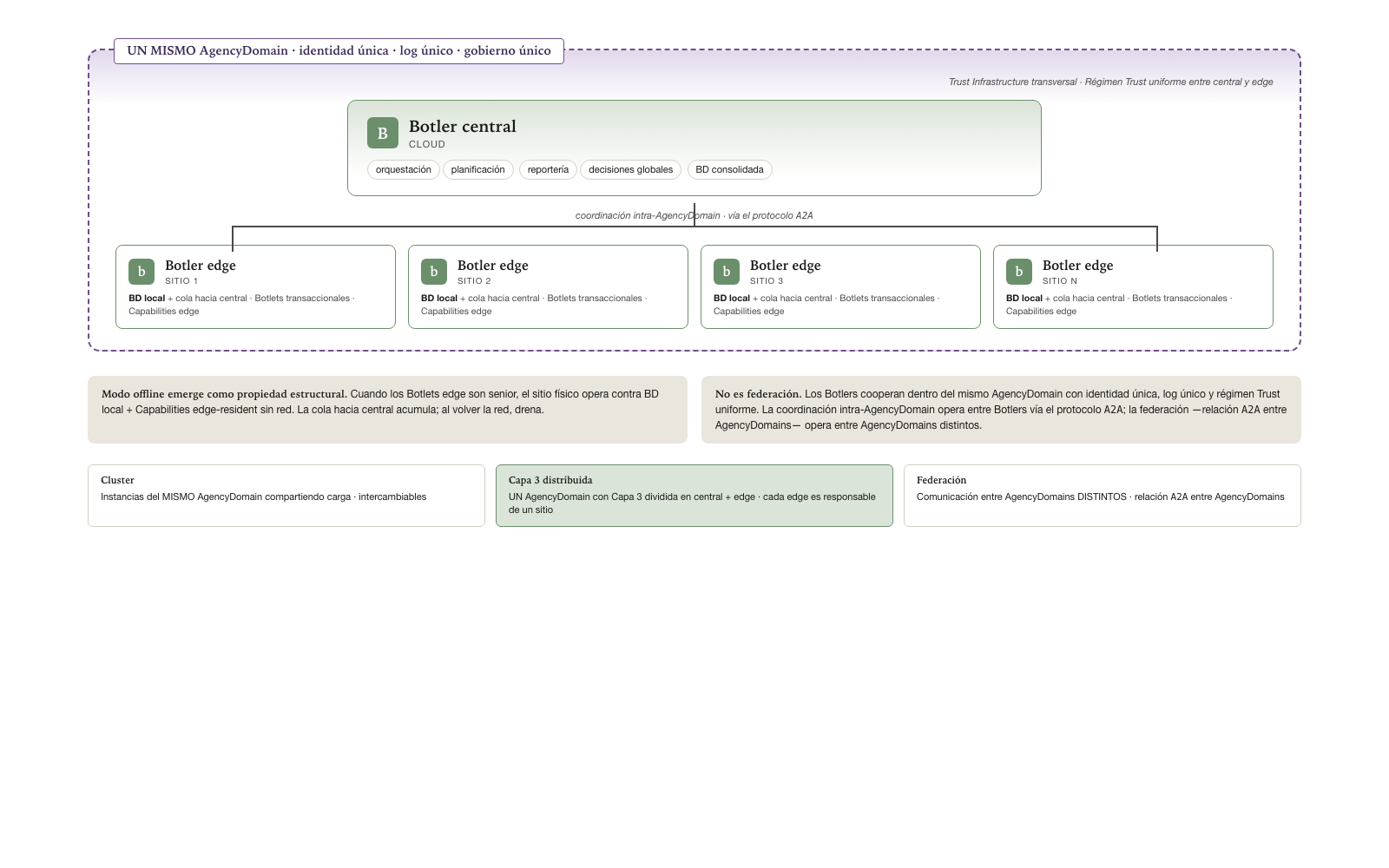
Chapter 4 (in its Layer 3 — Autonomy section) anticipated that the four layers may be distributed technically across distinct infrastructures. This section formalizes the most frequent and operationally important particular case: the geographic distribution of Layer 3 within a single AgencyDomain. The pattern resolves a scenario that any organization with multiple physical branches invariably encounters — multi-location food service, retail with a chain of stores, distributed logistics, healthcare with a network of centers, banking with branches, industrial plants with simultaneous production lines. Without formalization, each implementer reinvents the pattern with its own vocabulary and treats it as an exception to the model. With formalization, it stands as a canonical pattern that any serious implementation must contemplate.
The essential distinction is between internal distribution and external federation. Internal distribution occurs when a single AgencyDomain divides its Layer 3 across multiple coordinated physical nodes — a central Botler and N edge Botlers —, maintaining a single identity, a single governance, a single log, and a single data model. External federation occurs between distinct AgencyDomains, each with its own identity and governance. Cluster is an intermediate case (same AgencyDomain, same instances sharing load). Distributed Layer 3 is Cluster in terms of identity — all the Botlers belong to the same AgencyDomain — with the additional complication that the Botlers are not interchangeable: each edge Botler is responsible for a specific physical site.
Three pieces of the pattern
The canonical pattern distinguishes three pieces with distinct responsibilities:
1. Central Botler. Hosts the Botlets of orchestration, planning, reporting, global decisions. Lives typically in the cloud. It has a consolidated view of the state of all edge nodes. It executes operations that require crossing several sites — consolidating inventory, reconciling the day’s cash, planning the next day’s operation, sending consolidated regulatory reports. It maintains the consolidated DB and the unified audit log. It communicates with the cognition (Layer 2) for escalations and new decisions.
2. Edge Botlers. One per physical site. They host the local transactional Botlets — those that execute the site’s daily operation: taking orders, charging, issuing receipts, managing local inventory, controlling physical devices (pinpads, printers, sensors). Each edge Botler maintains a local DB with the site’s state and an event queue toward the center that synchronizes when there is network. They operate with full autonomy when the network is available and with local autonomy when the network goes down — the site keeps operating against its local DB; events accumulate in the queue; when the network returns, the queue drains and consolidation with the center resumes.
3. Coordination between Botlers via the A2A
protocol. The central and edge Botlers communicate via
the A2A protocol — the proper name of the
coordination protocol. It is not A2A in the relational
sense: these Botlers are runtimes of the same agent — the same
AgencyDomain —, not distinct agents, so the coordination between them is
intra-AgencyDomain communication, not A2A
between AgencyDomains. The conversation traverses the corporate network
but does not traverse the federation — it is entirely
within a single AgencyDomain. The distinction is not rhetorical: the
Trust Infrastructure regime is that of the single AgencyDomain, not that
of federation between AgencyDomains; the log is unified; the identity
model is internal; policies apply uniformly.
Offline mode as an emergent property
Under the parallel topology of Chapter 4 + the distributed Layer 3 pattern, the offline mode of a physical site emerges as a structural property of the system, not as a special capability that requires separate construction. When the network goes down at a site, two things happen simultaneously: the Cognition path becomes inactive (Layer 2 lives in the cloud and is not accessible), and the central Botler is also not accessible. But the edge Botler stays active: its Botlets run against the local DB, the edge-resident Connectors (ESC/POS printer, drawer, pinpad) remain available, the site’s daily operation continues. The event queue toward the center accumulates pending transactions; when the network returns, it drains and consolidates.
The condition for offline mode to operate correctly is that the edge
Botlets be senior in terms of the maturity proposal
(section §2): Botlets that have already incorporated the environment’s
variants and operate with a ratio close to
99+ / <1 / ~0. An edge Botlet in the junior phase —
still discovering variants — cannot operate without the possibility of
fallback to cognition. A senior edge Botlet can, because its only
failure modes are exogenous (power, hardware, catastrophic network), not
pending learning.
Properties required of the pattern
An AgencyDomain implementation with distributed Layer 3 must satisfy:
| Property | Level | Description |
|---|---|---|
| Single identity of the AgencyDomain | MUST | All Botlers (central + edge) belong to the same AgencyDomain with a single canonical URI. |
| Local DB in each edge Botler | MUST | Operational state of the physical site, accessible without network. |
| Event queue toward the center | MUST | Eventual-synchronization mechanism; pending transactions drain when there is network. |
| Conflict resolution in consolidation | MUST | When an event from edge reaches the center and conflicts with the consolidated state, an explicit policy decides. |
| Unified audit log | MUST | A single append-only log for the entire AgencyDomain, fed by all Botlers. |
| Single internal identity model | MUST | The Botlers do not authenticate to each other as external AgencyDomains; they share the AgencyDomain’s identity model. |
| Uniform Trust regime | MUST | Policies apply the same at center and edge; there is no special regime for edge. |
| Offline operation capability at edge | SHOULD | When the edge Botlets are senior, the site operates with intermittent network or without network. |
Portability of the AgencyDomain across conformant platforms
The regimes section formalized natural migration between regimes (private, public, hybrid) without rewriting. This section formalizes a complementary but distinct property: portability across hosting platforms conformant to the spec. A conformant AgencyDomain can be migrated to another conformant platform without rewriting its logic, its state, or its policies. This is a structural property of the spec — not the commercial commitment of a particular provider.
The motivation is operational before philosophical. Without an explicit portability commitment, the AgencyDomain repeats the lock-in of the application era — the client remains tied to its agentive provider exactly as it used to be tied to its SaaS provider. The structural promise of the spec — that the AgencyDomain is the real property of the client, not of the hosting — depends on portability being a property of the spec, not a concession negotiated case by case.
Three technical conditions
Portability requires three technical conditions that any conformant implementation must satisfy:
1. Botlets against canonical primitives. The
AgencyDomain’s Botlets must invoke Capabilities and the conformant
AgencyDomain SDK, not the current hosting’s proprietary
APIs. If a Botlet invokes a provider-specific API —
cloudprovider.lambda.exec, vendor.workflow.run
—, that invocation is portability debt. When the time comes to migrate,
that Botlet must be regenerated to invoke the equivalent canonical
primitive. A conformant implementation provides SDKs and registries that
abstract from the hosting; the Botlet sees the primitive, not the
implementation.
2. Exportable operational DB. The persistent state of the AgencyDomain — agents, Botlets, capabilities, audit log, operational data — must be exportable in a neutral format, without dependencies on the hosting’s storage engine. A documented schema (portable DDL or equivalent representation). A complete dump (all the information needed to reconstruct the space on another platform). No proprietary data types. No engine-specific extensions that have no equivalent in standard engines. The DB’s portability is what allows migration not to be a rewrite.
3. Portable Trust Layer. The policies, the append-only log, the Capabilities configuration, and the identity bindings must be maintained in a neutral reproducible format — typically structured Markdown or YAML/JSON with an explicit schema. The spec does not prescribe the exact format, but it requires the format to be readable by any conformant implementation, not only by the current one. A policy that only one provider’s policy engine knows how to interpret is not a policy of the AgencyDomain — it is provider configuration.
Natural migration vs portability
The two properties — natural migration between regimes and portability across platforms — are complementary but distinct:
| Axis | Natural migration between regimes | Portability across platforms |
|---|---|---|
| What changes? | The AgencyDomain’s regime (private → public) | The hosting platform |
| What remains? | The hosting platform | The AgencyDomain’s regime |
| Who decides? | The owning organization, by usage maturity | The owning organization, by economics or strategy |
| Expected frequency | Once or twice in the AgencyDomain’s life | Zero or few times, but the possibility must exist |
Portability is not a promise that migration will be trivial — there will always be a cost of orchestration, validation, cutover window. It is a promise that migration will be possible without rewriting the agent’s logic. That difference — between possible-with-work and impossible-without-rewrite — is what separates a conformant AgencyDomain from a proprietary agentive system in disguise.
Conformance
An implementation that intends to call itself conformant AgencyDomain to this specification must satisfy the following list of requirements. We mark them with the IETF convention: MUST for mandatory, SHOULD for strongly recommended, MAY for optional.
| Requirement | Level |
|---|---|
| Own identity | MUST |
| Materialization of the four layers | MUST |
| State persistence | MUST |
| Isolation between spaces | MUST |
| URL addressability | MUST |
| Canonical data model | MUST |
| Support for the three regimes | SHOULD (at least one; ideally all three with migration) |
| Support for Tokens and Subscription modes | MUST both |
| Complete agent life cycle | MUST |
Intra-AgencyDomain communication (Layer 2 → Layer 3 interface via
MCP; coordination between runtimes via the A2A
protocol) |
MUST |
A2A between AgencyDomains |
SHOULD |
| Federation | MAY (when the normative spec is available) |
| Cross-cutting Trust Infrastructure | MUST |
| Agent First principle | MUST |
| Distributed Layer 3 (central + edge Botler) | SHOULD (when there is multiple physical presence) |
| Portability across conformant platforms | MUST (Botlets against canonical primitives, exportable DB, portable Trust Layer) |
An implementation that meets all the MUSTs is an AgencyDomain conformant to version 1.0 of the spec. An implementation that meets the MUSTs and the SHOULDs is what we would call a reference AgencyDomain — an exemplary implementation the industry can take as a base. Implementations that also meet the MAYs are frontier implementations, which typically lead the evolution of the field.
Reference implementations
As we mentioned in Chapter 4, this specification is agnostic to
implementation. The public reference implementation is
Vergis: distributed under AGPL, with a
public repository at AgencyDomains.org, designed so that any developer
or student can download it, read it, run it, and learn how the spec
translates into a living system. Chapter 9 develops it
in detail; here it suffices to leave the pointer and assert that it is
conformant.
On the same canonical structure, product implementations in complementary regimes also operate: Agentia materializes AgencyDomains in the private regime within the infrastructure of the client firm, and Soveria materializes them in the public regime as a network of agents with a public identity. Other implementations are admissible and welcome. The specification intends to be an industry standard, not the intellectual property of a single actor.
Evolution frontier
Three areas of the specification are under active evolution and a future version of the book will probably normalize them in greater detail.
Federation is the first. As we mentioned, the normative protocol is not yet agreed upon by the industry. Version 1.0 recognizes the necessary mechanisms without prescribing them in detail. When consensus arrives — probably within the next two to three years —, the spec will incorporate it.
Agnostic cognition is the second. The spec admits non-LLM cognition — symbolic, multimodal, hybrid. The contemporary implementation is predominantly LLM-centric. The extension to other cognitive substrates requires refinement of the interfaces between Layer 2 and the rest of the AgencyDomain’s components.
Cryptographic identity of agents is the third. The model of verifiable on-chain or DID-based identity is under exploration. Adoption depends on the broader decentralized-identity ecosystem maturing sufficiently to support the agentive use case.
Two of these frontiers — federation and agnostic cognition — coincide with those of Chapter 4; cryptographic identity is specific to this spec. All of them are frontiers of the architecture itself, not only of its materialization in AgencyDomains.
Botlets
When a pianist learns a new piece, the first minutes are a conscious, costly experience. The pianist looks at the score, identifies each note, decides the fingering, executes each finger movement with full attention. The piece, in that first reading, is intense cognitive work. An hour later, after deliberate practice, the fingers begin to play on their own. The pianist still follows the score, but no longer has to consciously decide each note — the fingers know where they go. A week later, the piece is embedded in muscle memory: the pianist executes it without thinking. If at some point a mistake occurs, or something departs from the expected — an odd sound, an awkward fingering — consciousness reappears briefly, evaluates the problem, adjusts, and then withdraws again. Muscle memory takes back control.
This dynamic of human motor learning is not an arbitrary metaphor. It is the neurobiological basis documented by Squire and Wixted in their 2011 work on human memory systems, extending Larry Squire’s earlier work on memory modalities. The prefrontal cortex learns new patterns by spending costly cognitive resources. It hands them off to subcortical structures — the cerebellum, the basal ganglia — that execute them without conscious intervention. The prefrontal cortex reactivates only when it detects a significant deviation that the encoded routine does not handle. This architecture is what lets the human brain operate efficiently: the costly is minimized, the cheap is maximized, and conscious attention is reserved for when it is genuinely needed.
The Agentive Architecture replicates this biological architecture with discipline. What the brain does with prefrontal cortex and procedural memory, the agentive system does with LLM cognition and Botlets. When an agent faces a task for the first time, cognition — Layer 2 — processes it with the costly resources of the LLM: it reasons, decides, executes. When the task recurs frequently, cognition delegates execution to a Botlet — traditional, non-LLM code that cognition itself generated — which lives in Layer 3 and executes without invoking the model. If the environment changes and the Botlet fails, cognition takes back control: it regenerates the Botlet adapted to the new environment or, in the worst case, executes the task manually. The costly is minimized, the cheap is maximized, cognition is reserved for genuinely new cases.
Cognition thinks once. The Botlet executes ten thousand times.
This section develops the Botlet primitive with the detail it deserves. The Botlet spec is probably the most important primitive for the operational economy of an agentive system — without Botlets, inference costs make continuous autonomy unviable; with well-designed Botlets, the organization can operate agents in production at predictable, stable costs.
Definition
A Botlet is a self-evolving unit of automation: traditional, non-LLM-based code, generated by an agent to execute a repetitive task without invoking costly cognition. Botlets are the agent’s muscle memory — the computational equivalent of the automated gestures a human executes without conscious thought.
Four properties distinguish the Botlet from any traditional “macro” or “automated script”. The first is that the Botlet’s code was not written by a human: the agent’s cognition generated it when it recognized a repetitive pattern in its activity. This matters because dynamic code generation lets the system adapt the automation to each particular context, without depending on a programmer to anticipate every case. The second is that the Botlet executes without invoking cognition during normal operation. Once generated, the Botlet runs as traditional code — Python, JavaScript, Bash, whatever — independent of the model that created it. The third is that it regenerates automatically when it detects that the environment has changed. If the Botlet fails because an API changed, a data structure varied, or a screen was renamed, cognition regenerates the Botlet adapted to the new environment. The fourth — and critical — is that it has a fallback guarantee: if the Botlet fails catastrophically and cannot execute, cognition executes the task manually. The process never stops.
The difference from a traditional script is structural. A traditional script that fails leaves the operation halted until a human intervenes: someone must identify the problem, modify the script, redeploy it, validate. A Botlet that fails activates cognition, which executes the task — in that particular case, without a Botlet — and logs the event to regenerate afterward. The organization can depend on the Botlet without operational risk, because the Botlet’s failure is not the system’s failure.
The 95/4/1 cycle
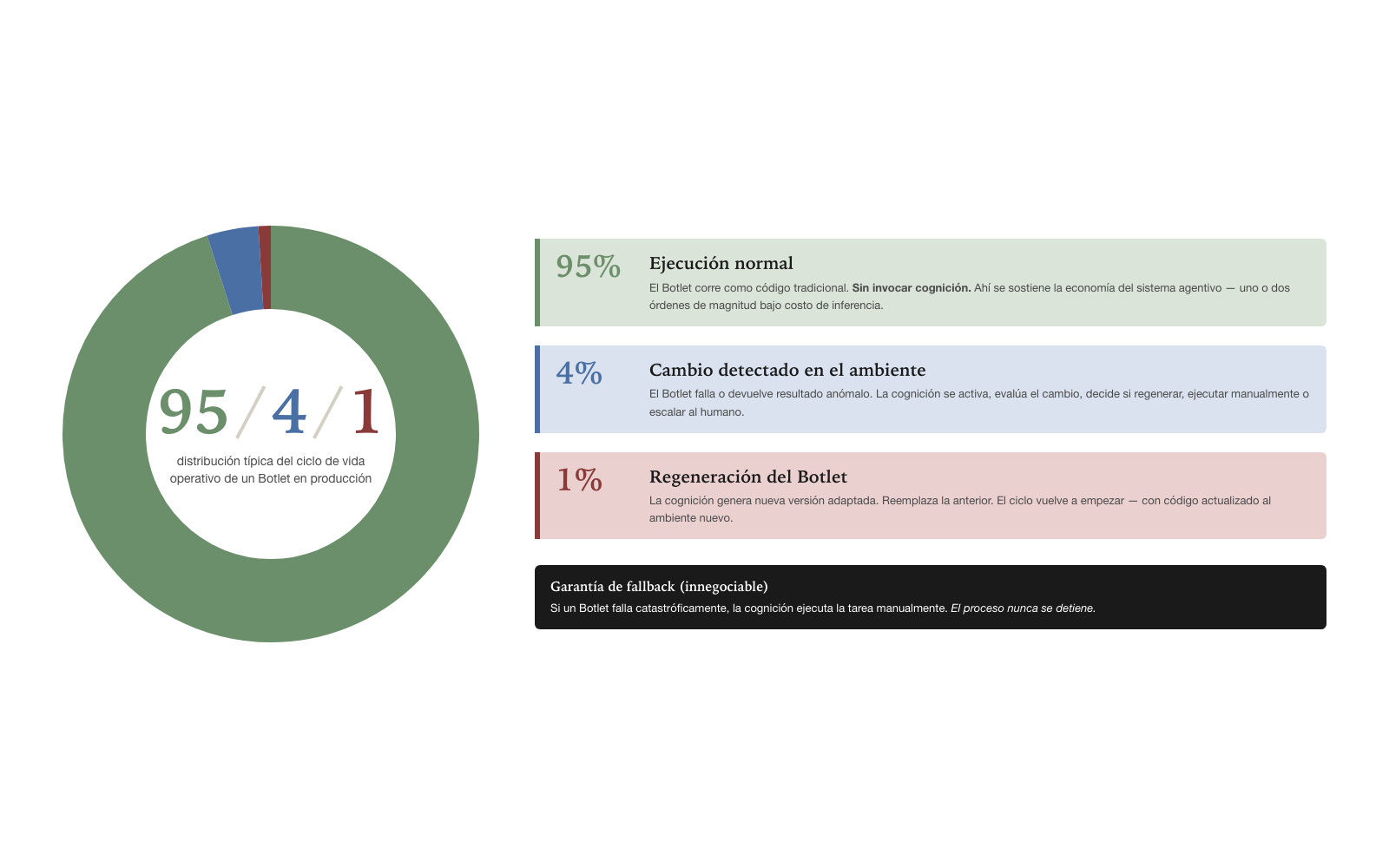
The operational lifecycle of a Botlet in production is typically
distributed in the proportion that gives this model its name:
95/4/1. The proportions are approximate
but structurally correct: most of the time the Botlet executes without
invoking cognition; occasionally the environment changes and the Botlet
fails; rarely does cognition have to regenerate the code.
Ninety-five percent of the time, the Botlet is in normal execution. Cognition is not invoked. The Botlet runs, completes its task in seconds or minutes depending on the case, returns a result. This is the efficient phase — where the whole economy of the agentive system rests. An organization operating a thousand agents with well-designed Botlets executes ninety-five percent of its tasks at traditional compute cost, not at LLM inference cost. The economic difference is one or two orders of magnitude.
Four percent of the time, the Botlet detects a change in the environment. It fails or returns an anomalous result. The environment changed: an API field moved, a data structure varied, an external system’s response has a different format. The Botlet, written for the environment of two weeks ago, no longer works. Cognition activates. It evaluates the change: is this something that can be handled by regenerating the Botlet? is this something that requires a one-off manual execution in this case? is this something that requires escalation to a human?
One percent of the time, cognition decides to regenerate the Botlet. It generates a new version adapted to the changed environment. The new version becomes the active Botlet, replacing the previous version. The next invocations — the new ninety-five-percent phase — use the regenerated version. The cycle closes and begins again.
The exact proportion varies by case. A Botlet operating against a very stable external system may hold ninety-nine percent normal execution and only one percent change detected. A Botlet operating against a volatile external system may drop to eighty percent normal execution with fifteen percent changes and five percent regeneration. What matters is not the specific proportions: it is the structure of the cycle. The Botlet executes most of the time without cognition; cognition is reserved for the cases where the environment changes.
Botlet maturity — junior, learning, senior

The 95/4/1 cycle is a useful didactic presentation, but
it is static: it describes the steady state of an
already-formed Botlet, not the trajectory by which the Botlet reaches
that state. Operational reality demands an additional distinction: a
freshly generated Botlet does not operate at the
95/4/1 proportion. It operates at a worse
proportion. Only after incorporating the environment’s variants does it
reach the maturity the canonical cycle describes. This section
formalizes the trajectory.
The spec recognizes three canonical phases in a Botlet’s maturity: junior, learning, senior. The phases are not administrative labels; they are states with distinct properties that the system tracks in order to decide how much to delegate to the Botlet and when to escalate it.
Junior phase
A junior Botlet is a freshly generated Botlet. It has just come out of cognition. It knows the environment only in the version cognition observed when it created it. The environment’s variants — dates in a different format, error messages with new wording, optional fields that appear only sometimes, edge cases — have not yet passed through it, so its code does not account for them.
The typical proportion of a junior Botlet is something like
60 / 35 / 5: only 60% of invocations are successful normal
execution; 35% are failures due to environment variants the Botlet does
not anticipate; 5% are regenerations when cognition decides the observed
variant is structural and must be incorporated. The proportion is
unfavorable, but it is not a problem — it is the normal phase of any
freshly generated Botlet, and cognition is there precisely to rescue
it.
Operationally, a junior Botlet depends heavily on the availability of cognition (Layer 2). It cannot operate offline because too many of its invocations require rescue. Nor can it assume critical responsibilities without an explicit safety net.
Learning phase
A learning Botlet is a Botlet that has already
passed through its first real invocations. It has faced environment
variants and has been regenerated several times to incorporate them. Its
proportion moves toward something like 85 / 12 / 3: most
invocations are successful, failures due to new variants are less
frequent, regenerations are occasional.
The learning phase is the longest phase of the Botlet’s useful life — it can last weeks or months depending on invocation frequency and the environment’s volatility. Each regeneration consolidates operational know-how: each variant incorporated is one less variant that can surprise the Botlet in the future.
Operationally, a learning Botlet can operate with an intermittent safety net — failures are still frequent enough to need cognition available regularly, but not at every invocation. It can assume operational responsibilities under close human observation.
Senior phase
A senior Botlet is a Botlet that has already
incorporated the environment’s variants. Its proportion tends toward
99+ / <1 / ~0: practically all invocations are
successful normal execution; failures due to environment changes are
rare because the environment now rarely presents it with something it
does not know; regenerations are exceptional.
A fundamental property of the senior Botlet changes relative to the earlier phases: its failures in the senior state are not environment changes; they are exogenous causes. When a senior Botlet fails, the typical cause is something that would halt any stable system: a power outage, downed hardware, catastrophically lost network, a downed external resource (a tool provider, a regulated system). These failures are not pending learning — they are the same thing any operating system encounters occasionally and resolves with redundancy, restart, or human intervention.
Operationally, a senior Botlet can operate offline reliably. The reason is structural: if its only failure modes are exogenous, the presence or absence of cognition does not significantly change the probability of failure — cognition has no way to rescue from a power outage. The senior Botlet, against a local DB and edge-resident Connectors, sustains the physical site’s operation even when cognition is unreachable. This property is the structural basis of offline mode in systems with a distributed Layer 3 (Chapter 5 §1).
Implications of the trajectory
The distinction among the three phases has three implications worth keeping in mind.
First, reliable offline operation is a property of senior Botlets, not of Botlets in general. To expect a Botlet freshly deployed at a new site to operate offline is to violate the spec — it is still junior, it depends on cognition. The trajectory of an edge node from production launch to full offline operation requires time of exposure to the environment; it is not an instantaneous property.
Second, the agentic fallback guarantee is what produces maturity. Each Botlet failure due to an environment change activates cognition; each activation of cognition regenerates the Botlet incorporating the variant. Without agentic fallback, the Botlet would be trapped in its initial version, with no way to learn. The connection with the operational business-continuity section of §4 is direct: the fallback guarantee resolves the junior phase and the transition toward senior; operational continuity resolves the exogenous failures of the senior phase.
Third, a Botlet’s maturity is traceable. The Trust Layer’s append-only log records each invocation, each failure, each regeneration. The proportion of each phase is observable, and the trajectory of a Botlet from junior to senior is auditable. This traceability is what lets the organization make operational decisions — “this Botlet is now senior, we can delegate critical responsibilities to it” — on evidence, not on assumption.
Seed Botlets vs emergent Botlets — the origin of the Botlet
The cycle described so far assumes that Pattern
Recognition — the auxiliary primitive developed further below —
triggers the generation of a Botlet upon detecting an unanticipated
repetitive pattern. That is the emergent modality of
generation. It is the modality the neurobiological model inspires and
the one the 95/4/1 cycle describes in its purest form. But
it is not the only modality, and for real productive
systems it is not even the most frequent.
In a productive system, the MVP’s critical Botlets do not emerge: cognition implements them because the design team planned them as part of the product spec. The team knows, before the system sees its first transaction, that it is going to need a POS Botlet, an order-ticket Botlet, a charge Botlet, a shift-close Botlet. Cognition executes the implementation of those Botlets; but the decision to exist was made by the design, not by Pattern Recognition.
The spec therefore distinguishes two canonical origins of the Botlet:
Seed Botlets. Generated by cognition at the design team’s request, as part of the initial product. Cognition executes the implementation — it writes the Botlet’s code, registers it in the Botler, deploys it to the corresponding environment — but the decision of which Botlets there should be, what tasks they cover, and under what contracts they operate, belongs to the design team. Pattern Recognition does not participate in seed generation.
Emergent Botlets. Generated by Pattern Recognition when cognition, during operation, detects a repetitive pattern not anticipated by the design. Cognition evaluates whether the pattern merits automation, decides affirmatively, and generates the Botlet. This is the modality the previous section described.
Both live and operate identically once generated — both are subject
to the 95/4/1 cycle, both pass through the junior →
learning → senior phases, both have a fallback guarantee, both are
auditable. The difference is in the origin.
Pattern Recognition is not the only path to a Botlet. Design is not technical debt either. The two paths coexist.
The distinction has three practical consequences.
First, a productive agentive system does not require waiting for Pattern Recognition to discover the critical Botlets. Seed Botlets are generated at the outset according to the product spec, and the system enters production with the battery of Botlets needed to operate. Pattern Recognition comes later, during the system’s life, to optimize what the design did not anticipate.
Second, seed Botlets can live in any layer, not only in Layer 3. The persistent GUIs generated as facade Botlets of Chapter 4 §1 illustrate it: the facade Botlet is a Layer 3 seed Botlet that exposes its stable surface in Layer 1, and the presentation Botlets that compose that surface (shells and views) are Layer 1 seed Botlets — generated by cognition at the design team’s request because the operational role (cashier, cook, plant operator) justifies it. The canonical definition of the seed Botlet allows these materializations without the spec treating them as exceptions.
Third, the maturity trajectory applies equally to seed Botlets and emergent Botlets. A freshly deployed seed Botlet is junior; a seed Botlet that has already operated thousands of times and consolidated its know-how of the environment is senior. The origin distinction does not change the trajectory; only the moment of onset.
proto-Botlet — the pre-forged piece
The seed-vs-emergent distinction describes who decides that a Botlet should exist. A prior question remains: when cognition generates a seed Botlet, does it write its code from scratch every time? In operational practice, no. A Botlet’s code rarely springs from nothing: it springs from a pre-forged piece that the agent configures.
A proto-Botlet is a pre-forged piece of operational capability that the agent, in its Engineering time, configures to instantiate a Botlet specific to the case. The proto-Botlet contains the code; the Botlet is the configured instance. The relation is generic → instance: the proto-Botlet lives in a catalog and serves many cases; the Botlet is one of those cases resolved.

The connection with the origin of the Botlet is direct. A seed Botlet that the design team planned does not force cognition to write its entire logic: if the catalog has a proto-Botlet that covers the function — charging an account, an order against a ticket printer, an informational operation — cognition instantiates the Botlet by configuring that proto-Botlet rather than generating it. The decision to exist still belongs to the design (it is seed); the materialization of the code rests on the pre-forged piece.
The spec recognizes two classes of proto-Botlet, according to the nature of their code:
| Class | What is its code? | How is it configured? | Anonymized example |
|---|---|---|---|
| Tempered | Code specific to its function | Bounded parameterization | Charging an account; an order against a ticket printer |
| Platform | Generic code whose specialization lives in a compositional configuration | Compositional configuration, covering N functions of the domain | An informational-operation piece that serves reports and dashboards in many forms |
A tempered proto-Botlet resolves a function and resolves it in full; configuring it is adjusting parameters within a foreseen range. A platform proto-Botlet is an engine: its code is generic and the specific function emerges from a rich configuration — compositional, not a flat list of parameters — so that a single platform proto-Botlet covers N functions of its domain. Mira, in the reference implementation’s catalog, is a platform proto-Botlet for informational operation.
Different implementations maintain catalogs of proto-Botlets — public in AgencyDomains.org, private in proprietary codices. And the degree to which the agent configures the pre-forged piece, co-writes its code, or generates it entirely defines the Botlet generations — the next section fixes them.
The Botlet generations —
G1, G2, G3
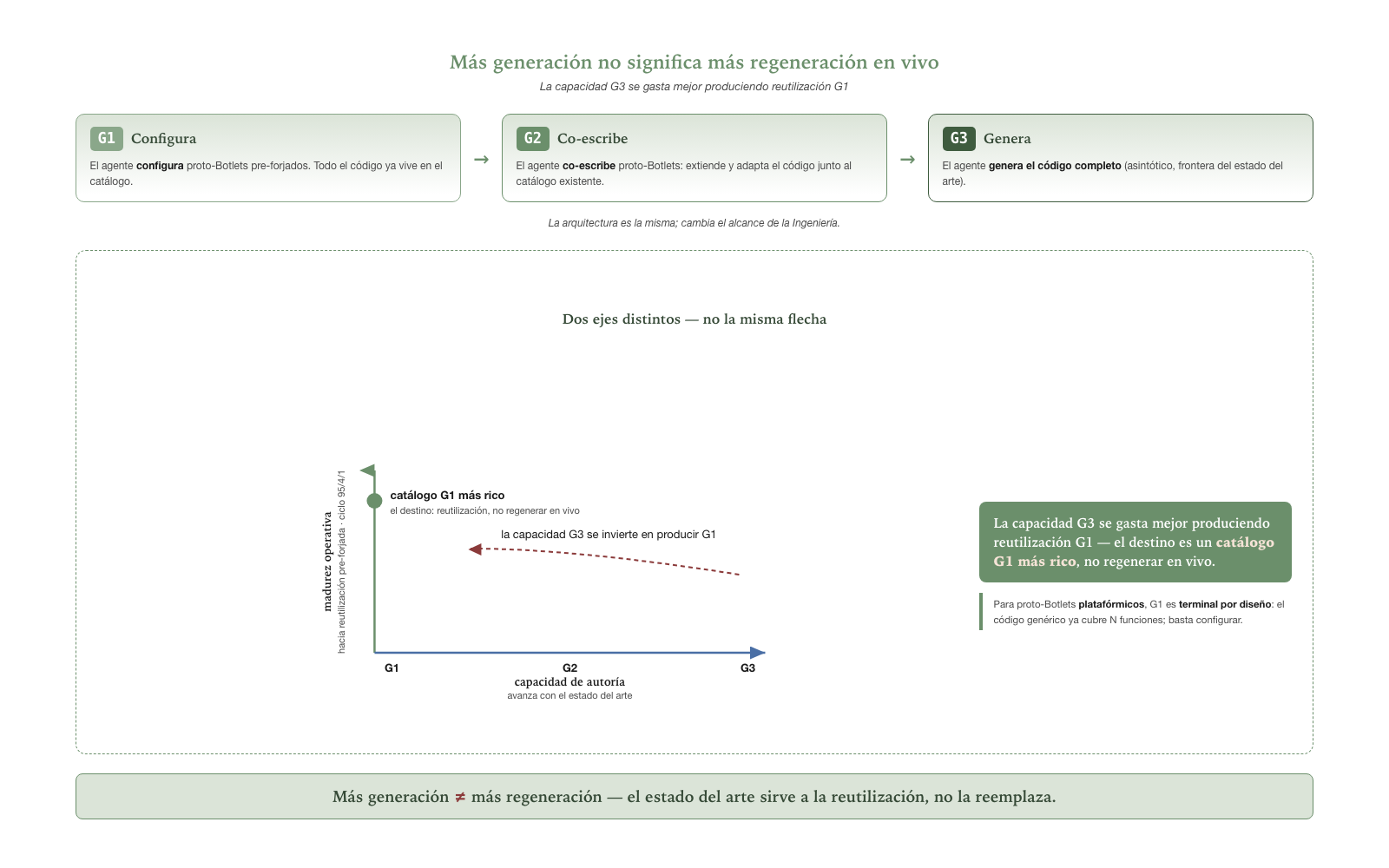
The generations are the evolutionary model of how a Botlet’s code is born as the state of the art of cognition advances:
G1— the agent, in its Engineering time, configures pre-forged proto-Botlets from the catalog. If none serves, it specifies a new one to be forged in the next Preparation.G2— the agent co-writes proto-Botlets with human or model assistance. Part of the work that inG1happened in Preparation migrates to Engineering.G3— the agent generates the Botlet’s complete code in its Engineering time, pre-forging nothing. The asymptotic scenario.
The architecture is the same across all three generations; what
changes is the scope of the Engineering the agent
performs. An implementation can operate in G1 today and
migrate incrementally toward G3 as the state of the art
allows, with no re-architecture.
A higher generation is not a destination. The
previous sentence — migrating toward G3 — induces, read
alone, a false conclusion: that G3 is the destination and
G1 a primitive way station. The error comes from projecting
two distinct axes onto a single arrow:
| Which axis? | What does it measure? | Direction of “progress”? |
|---|---|---|
| Authoring capacity | How much the agent can forge: configure (G1) → co-write
(G2) → generate whole (G3) |
Toward G3, as the state of the art of cognition
advances |
| Operational maturity | For a recurring operation, how much is reused pre-forged vs
regenerated each time (the 95/4/1 cycle) |
Toward reuse (G1), as the Botlet matures junior →
senior |
They are not the same arrow. An agent with G3 capacity
that regenerates every artifact from scratch on every execution is not
advanced: it has the muscle and chooses to re-learn the move every time.
The reconciliation is direct: G3 capacity is best spent
producing G1 reuse. The generations
describe what the agent can author; the 95/4/1
cycle describes what a mature agent reuses. The destiny of
G3 capacity is a richer G1 catalog, not the
live regeneration of everything.
There is a corollary for platform proto-Botlets. For
one of them, G1 is terminal by design, not
a way station: its identity is generic code plus configuration. A
platform proto-Botlet “in G3” — where the agent regenerates
the engine for each piece — is not a more advanced version; it dissolves
the proto-Botlet and collapses back into the agentic mode the
architecture exists to transcend.
G1 is not poor configuration. What
defines G1 is that the agent does not write the body of the
proto-Botlet — but the configuration it fills in can be as rich as a
compositional DSL with evaluable formal expressions. The
G1/G3 distinction is about authorship
of the proto-Botlet’s body, not about the expressiveness of the
configuration. A platform proto-Botlet with a rich DSL is
pure G1.
That leaves one borderline case: configuration that admits evaluable
formal expressions — SQL, chart specifications, filter
expressions. The G1/G2 edge
resolves it:
- A formal evaluable expression that is a parameter of a
well-defined Capability (
SQL→execute-sql, a chart specification →render-chart, a filter expression →filter-stream) is configuration →G1. - An expression that extends or overrides the proto-Botlet’s
internal logic — callbacks, lambdas the proto-Botlet evaluates
internally, fragments concatenated to its body — is code written by the
agent →
G2.
The test is a single one: “does the code belong to the invoked
Capability or to the proto-Botlet itself?”. If a catalog Capability
evaluates it, G1; if the proto-Botlet evaluates it in its
internal logic, G2.
The reference implementation, Vergis, operates today in
G1: its catalog exposes proto-Botlets — Mira among them —
that the agent specializes by configuring, not regenerating (Chapter 9).
The deeper sense of the generations — why the advanced agent generates
less, not more — is the essay that closes the book.
Fallback guarantee — the non-negotiable property
The fallback guarantee deserves detailed treatment because it is what makes the Botlet operationally reliable instead of fragilely automated. An organization that depends on a Botlet for a critical operation — processing a nightly batch, sending regulatory reports, reconciling transactions — must be able to trust that the Botlet will execute or, failing that, that someone will execute the task in its place. The fallback guarantee is what sustains that trust.
When a Botlet fails catastrophically — not because the environment changed slightly and cognition can regenerate the code, but because something genuinely prevents execution — cognition executes the task manually. Manually in this context means the LLM does the work step by step, invoking the underlying tools the Botlet would use, but without the efficiency of compiled code. The process is slower and more costly — cognition consumes tokens — but the work gets done. The organization is not left halted.
This guarantee is not decorative. It is what distinguishes the Botlet conforming to this spec from any fragile “smart macro” or “AI automation”. Traditional macros fail and leave the operation halted; Botlets fail and cognition takes over. The difference is structural and translates directly into operational availability: an organization with correctly designed Botlets can promise operational SLAs that would be impossible with traditional automation.
The Botlet does not replace cognition. It frees it from repetitive work, but it remains as a safety net.
The quote above captures the relation between the two layers well. Cognition is not residual — it remains the general intelligence that sustains the system. The Botlet is operational efficiency that operates while the environment allows it. When the environment leaves the range, cognition returns.
When to use Botlets, and when not?
Not every task benefits from being delegated to Botlets. The spec defines clear criteria for deciding when it is worth generating a Botlet and when it is worth keeping the task under continuous cognition.
It is worth generating a Botlet when the task is repetitive — more than ten invocations is a useful rule of thumb — when the pattern is stable at its core even though the environment may change, when the process is critical and must be fast, when the cost of cognition per invocation is material at scale, and when there is tolerance for sporadic regeneration of the code without that affecting the operation.
It is not worth generating a Botlet when the task is unique or low-frequency, when the pattern is highly variable and each invocation requires fresh judgment, when the task demands deep reasoning a script cannot capture, when it is a prototype or exploration where flexibility matters more than efficiency, when total cost is irrelevant and continuous cognition is practical, or when changes in the environment are so constant that the Botlet would regenerate all the time, losing its benefit. There is an intermediate case that deserves a name of its own: the task recurrent in its form but interpretive in every instance — the pattern is stable, but each execution demands fresh judgment that no deterministic code captures. That task belongs neither to the Botlet nor to continuous cognition: it belongs to the Agentlet, the sibling primitive that §7 of this chapter formalizes.
The rule of thumb that synthesizes these criteria: if the task executes more than ten times and its logic is stable at its core, it is worth generating a Botlet. Below that threshold, cognition is more efficient. Above it, the economic difference begins to be material.
An important observation: the decision of when to generate a Botlet is not made by a human. It is made by cognition itself, assisted by Pattern Recognition, which detects the repetitive patterns. The human defines the general rules — what types of tasks are candidates, what frequency thresholds are relevant, what types of environments are sensitive — but the specific decision in each case emerges from the agent’s behavior. This is a property of the agentive system: the optimization decision is the agent’s own, not external to it.
Manifestation and temporality of the Botlet
A Botlet is muscle memory: a latent disposition, a stored know-how that is nothing until it is exercised. When the Botlet executes, that latent is actualized in the world. That actualization is its manifestation: the Botlet’s passage from potency to act, perceptible or not.
The word demands care. Manifestation is not appearance. The common term suggests “becoming visible”, and that would leave out legitimate cases: a Botlet that triggers a periodic ingestion manifests — it actualizes its latent, produces an effect — even though it leaves no visible artifact. That is why the canon defines it as actualization of the latent, not as appearance: the invisible effect counts as much as the artifact in view.

Manifestation is the abstract genus; each Botlet family specializes it, and each practice gives it its loaded name:
- the information family → its manifestation leaves
an Information Product (
PI), - the action family → an effect on the world, with no artifact,
- the decision family → named by its own practice.
The PI is not a primitive of the canon:
it is the manifestation of one family. The canon stops at
manifestation; the Information Product is a normed
term of this spec — not a primitive, but vocabulary with rules
— and its governance load is added here without contaminating the
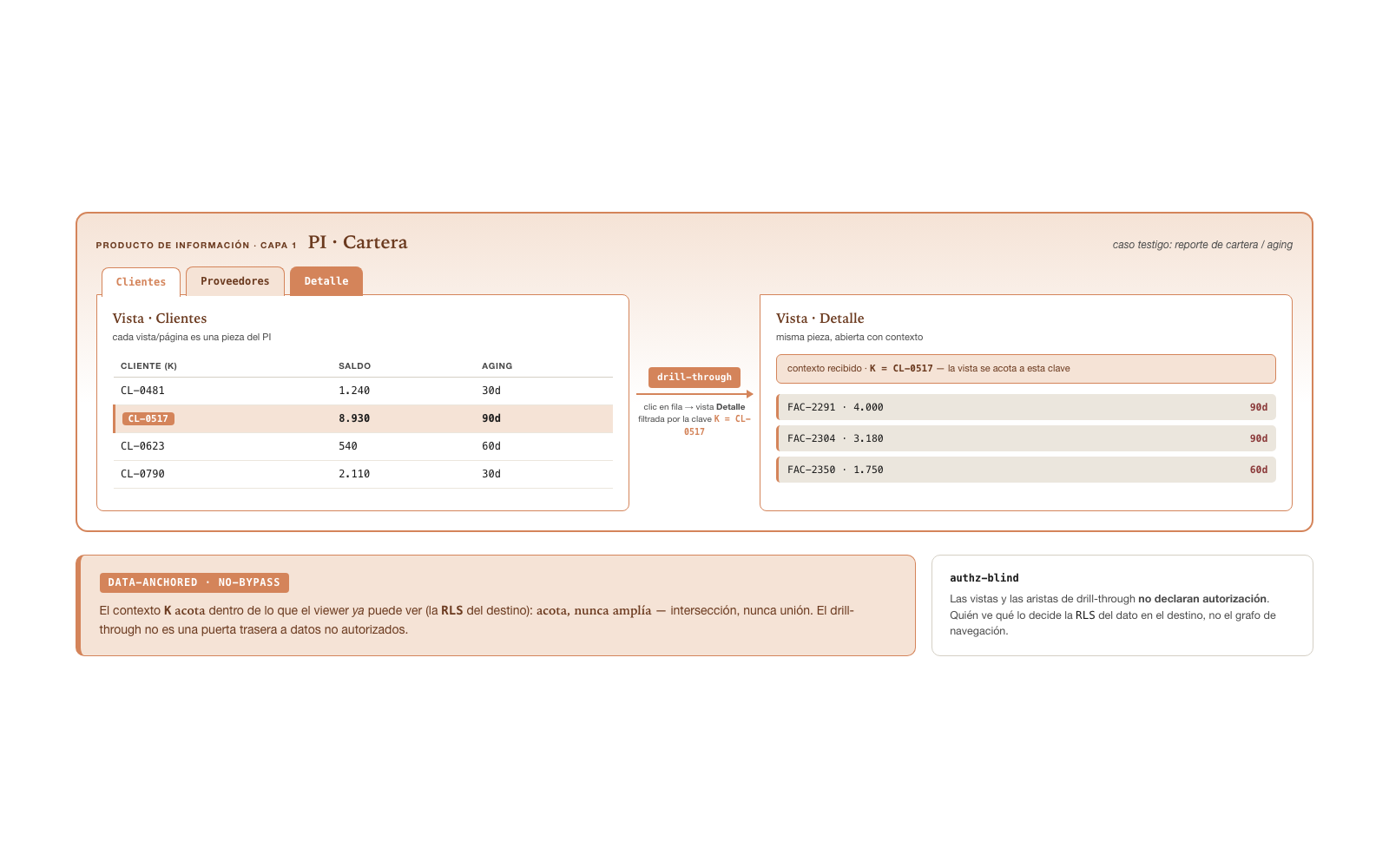
canonical level. This is its reference description:
Multi-view Information Product · drill-through. A
PI is not necessarily a single piece. It can be composed of
N named pieces: each view is one more
piece of the same PI, selectable from a picker, with a
default view (the first). The PI is
authz-blind — neither the views nor the edges that
connect them declare authorization; that policy lives in the policy
store, not in the composition.
The connection between views is the drill-through: a
navigation edge with context. A table declares “on
clicking a row, go to the destination view passing that row’s key”;
the destination view renders filtered by that key. The
critical property is data-anchored / no-bypass: the
context that travels with the edge narrows within what the
viewer can already see — the destination view applies its own
row policy (RLS, row-level security) over the
source, and the context enters as an additional filter, never as an
override of the policy (MUST). The drill
narrows, never widens — intersection with what is
authorized, never union. If the viewer does not reach the origin row,
they do not reach the edge; if they reach it, the destination is still
governed by its own policy.
A receivables / balance-aging report illustrates the pattern: named
views (Customers, Suppliers, Related parties, Detail) over the same
PI, a hierarchical Company→Partner table, and a
Partner→Detail drill-through edge that opens that partner’s documents —
filtered by the partner’s key and narrowed to what the viewer already
had the right to see. The multi-view composition is orthogonal to the
operation Botlet’s family: what changes is how many pieces compose the
manifestation, not its nature.
Temporality is the regime of the manifestation. It is a declared attribute of the Botlet, with two values:
| Temporality | How does it manifest? | Relation to the runtime |
|---|---|---|
discrete |
In pulses: wakes on schedule, trigger, or event, acts, rests | The Botler invokes or schedules; the Botlet does not live between pulses |
continuous |
Sustained: lives persistent and manifests without cease | The Botler sustains execution as long as the Botlet lives |
temporality: continuous is equivalent to the persistent
life of Layer 3: it obliges the Botler to sustain the Botlet’s execution
without restart for each manifestation. A conforming Botlet with
continuous temporality MUST be sustainable by the persistent runtime; a
Botlet with discrete temporality manifests via schedule, trigger, or
event.
The operational consequence is strong: real time is not
chosen in a delivery channel. It is not obtained by marking a
channel as push; it is obtained by giving the Botlet
continuous temporality, which in turn obliges the persistent runtime.
The delivery mode is the symptom; continuous temporality is the cause.
This relocates “real time” from the channel level to the Botlet level,
and connects with the distinction Online enterprise ≠ Real-time
enterprise: they are not two classes of information, but two points
on the continuum of temporality.
From here follows a runtime economy. A report — a snapshot at a point in time — and a live dashboard are not two distinct types of what: they are the same manifestation under different temporality. That is why a single runtime covers both: one builds the hardest case (continuous) and the simple cases are degenerate configurations of that case, not separate codepaths. The distinction holds precisely because temporality is orthogonal to what manifests.
Botler — the framework runner
Botler is the infrastructure that executes the Lets — the proper name of the genus of the packaged units of Layer 3 (Autonomy): the Botlets this section develops and the Agentlets that §7 formalizes as their sibling species. It is invisible to the user and to the agent; it is the responsibility of the AgencyDomain’s implementation. The canonical relation is simple and is stated over the genus: an AgencyDomain process contains a Botler, and the Botler manages N Lets that live within that process — 1 Process = 1 Botler + N Lets. In this section, where the Lets are Botlets, the relation instantiates as 1 Botler + N Botlets.
The Botler provides four critical functions. The first is execution isolation — sandboxing appropriate to the environment, which we detail in the next section. The second is management of the Botlet’s lifecycle: invocation when needed, monitoring during execution, failure detection, triggering regeneration when appropriate. The third is communication with cognition when the Botlet detects a failure or change in the environment that exceeds its capacity to handle. The fourth is traceability: every Botlet invocation, every result, every failure, every regeneration is recorded in the Trust Layer’s append-only log. This traceability is what allows reconstructing, auditably, what the agent did and why — and it is indispensable for governance.
The Botler as an abstraction matters because it decouples the isolation implementation from the agent that uses it. The agent does not know — nor does it need to know — whether its Botlet runs in a Docker container, a WASM sandbox, or a microVM. It requests execution from the Botler; the Botler executes under the isolation model the AgencyDomain’s implementation chose. This separation is what lets the spec be agnostic to isolation technology — different implementations choose different technologies according to their specific tradeoffs.
The Botler is generic by definition
The Botler does not understand the domain of the Botlets it executes. It manages the lifecycle, isolation, and execution of any Botlet without knowing what that Botlet does or what discipline it belongs to. All domain specialization lives in the Botlets and in their proto-Botlets, never in the runtime that hosts them. The architecture is flat: a generic runtime hosts self-contained specialist components.
From here follows a structural property: no Botler subtypes exist by family of operation. There is no “informational” Botler, no “transactional” one, no “for information artifacts” one — an informational-operation Botlet already carries its own freshness, its cache, its distribution, so a Botler subtype that duplicated it would contradict the runtime’s genericity without adding anything.
Botler subtypes are distinguished by deployment topology and role — central, edge, operational facade for Botlets invocable from Layer 1 — never by domain. Domain specialization lives entirely in the Botlets that the Botler executes.
The axes of topology and role are legitimate because they answer where the runtime runs and with what autonomy, not what domain it executes: a central Botler and an edge Botler differ in connectivity and offline operation, not in business knowledge. The normative note is the boundary: any Botler distinction that appeals to the family of operation it executes is ill-posed.
The Botler validates by orchestrating, not by executing
The registration of a Botlet requires its spec to be valid against the declared type before accepting it. This poses an apparent tension: if the Botler does not understand the domain, how does it validate a spec whose meaning is domain-specific? The answer distinguishes orchestrating the validation from executing it.
The Botler enforces the validation; it does not execute it with domain knowledge. At registration time it invokes the validation point the Botlet itself provides — or that its proto-Botlet provides in G1 — hands it the generic context it does control (the catalog of available Capabilities, the identity, the AgencyDomain’s policies), and acts on the verdict: it accepts, rejects, or records the result in the append-only log. The judgment of what makes a spec valid lives entirely in the Botlet; the Botler decides whether to admit it or not according to a verdict it did not produce. Thus no invalid spec gets in — the rejection happens before admitting the Botlet and remains traced — without the runtime ever interpreting the domain.
This pattern has a sibling in the invocation of Capabilities. The Botler is the only point through which a Botlet invokes Capabilities, and bypass through parallel channels is not forbidden by policy alone: it is made structurally impossible. On each invocation the Botler hands the Botlet a controlled handle — an object with access to Capabilities and to the log bound to the Botler itself — instead of letting the Botlet build accesses on its own. The Botlet can only act on the world through that handle. Both cases share the principle: the generic Botler exposes control points and the specialist plugs into them; the runtime stays thin without giving up the guarantees the contract requires.
The Layer 2 ↔︎ Layer 3
interface via MCP
The Botler is the only point of execution for Botlets, and that
includes the operation that cognition itself directs:
Cognition (the LLM agent, Layer 2)
commands the Botler (Layer 3 runtime, without agency) over an
internal interface whose natural transport is
MCP — the Botler exposes MCP servers and
Cognition is the client. This interface is not
A2A; the formal correction of the A2A
nomenclature and the Layer 2 ↔︎ Layer 3 interface are developed in
Chapter 5 §1.
Source code
vs spec · two surfaces · one Botlet per PI
The operation of a Botlet involves two things worth not confusing. One is the Botlet’s source code: its implementation. For a platform proto-Botlet, that source code is the engine, shared by all the Botlets instantiated from it. The other is the spec: what specializes the Botlet’s behavior to its instance. The spec is not the code; it configures it.
That separation projects onto two surfaces of management:
| Surface | What does it manage? | Granularity | Cadence |
|---|---|---|---|
| Source-code lifecycle | Install, version, load, and unload the engine | Botler-level | Releases (Product) |
| Operation | Specialize, manifest, consume, and control each Botlet | Per-Botlet | Fluid (Instance) |
Operation includes configuring the spec. For a
platform proto-Botlet, the spec is the operational input: there is no
“operating” without a spec. Hence a principle: configuring the
spec is operating. The agent evolves the spec by operating —
the specialize verb — fluidly; the crystallization of the
spec into a versioned registry follows, it does not
precede, and provenance is given by the append-log. The
operation API verbs are specialize, invoke,
and schedule (for discrete temporality), read
and subscribe (for continuous temporality), and
status, activate, deactivate,
retire.
From this follows the granularity rule: one Botlet per
PI over a shared engine. Each Information Product
is its own Botlet — its own service, with its own identity, temporality,
maturity, and fallback — specialized from the shared engine (the
platform proto-Botlet). It is not one Botlet with N configurations,
which would lose that independence; it is not N programs, because the
engine is one. It is the relation
1 Process = 1 Botler + N Botlets, with the Botlets as
specialized instances of the same proto-Botlet. The rationale is
RISC: many simple, focused Botlets — one per
PI — compose better than a monolith.
The subscribe consumption is the bridge to the
agentive north. Today a human consumes it — a browser
subscribed via SSE that receives the stream of
manifestations of a continuous Botlet — tomorrow Cognition consumes it,
feeding on that same stream to decide. Continuous temporality, the
persistent runtime, and the subscribe verb are, together,
the infrastructure of that north.
Isolation model — sandboxing
Botlets are code generated dynamically by an agent. This demands strict isolation. A badly written Botlet, or a Botlet generated by an agent that fell victim to prompt injection, could attempt malicious actions — exfiltrating data, modifying system files, opening unauthorized network connections. Isolation is what contains those risks.
The spec admits four sandboxing strategies, with their trade-offs:
Processes with seccomp offer low isolation and minimal overhead. This strategy is useful only in controlled environments where the risk of malicious code is low — for example, Botlets running inside the private perimeter of an organization with implicit trust in its own agents. It is not an adequate strategy for Botlets that touch sensitive data or that operate under a public regime.
Containers — Docker, Podman, equivalents — offer medium-high isolation with medium overhead. It is the most practical strategy for generic Botlets that need to invoke operating-system tools or networks. Containers have a mature ecosystem, reasonable portability, abundant operational tooling. They are a reasonable default for most cases.
WASM (WebAssembly) offers high isolation with low overhead, but the ecosystem is more limited. WASM is ideal for pure transformational Botlets — calculations, data transformations, algorithmic logic — that do not need access to the underlying operating system. The startup speed is very fast (milliseconds), which matters when an agent needs to invoke many Botlets simultaneously.
MicroVMs — Firecracker, Kata Containers — offer maximum isolation with high overhead. They are suitable for Botlets that handle highly sensitive data or that operate in shared multi-tenant environments where the risk of cross-tenant leakage is unacceptable. The overhead typically means tens of milliseconds of additional startup, which in some cases is prohibitive.
The canonical recommendation for reference implementations is hybrid: WASM for pure transformers (without system access), containers for generic Botlets that need to invoke operating-system tools, MicroVMs for Botlets that handle highly sensitive data or that operate in shared multi-tenant environments. The specific choice for each Botlet depends on its risk profile and its performance requirements.
Language of the Botlets
The spec is agnostic to the implementation language of the Botlets. Cognition can generate Botlets in any language as long as the Botler can execute them within the chosen sandbox. This agnosticism matters because the language landscape evolves — a system tied to a specific language can become obsolete when that language loses traction in the AI ecosystem.
The practical recommendations for reference implementations are:
Python is the first choice. The maturity of the ecosystem, the libraries for almost any integration, the highly reliable LLM generation — contemporary models generate Python correctly with very high frequency — make Python the reasonable default for generic Botlets.
JavaScript / TypeScript are suitable for Botlets that touch HTTP APIs or that automate browsers. The npm ecosystem has broad coverage, and LLM generation is also reliable.
Bash or shell are suitable for Botlets that orchestrate operating-system commands. LLM generation of bash is reliable for simple cases, less reliable for complex cases where bash syntax has quirks.
Rust or Go — compiled languages — are suitable for very-high-frequency Botlets where interpreter overhead matters. LLM generation is less reliable than Python, but the resulting Botlets execute faster. This combination makes sense when a Botlet is going to execute millions of times and the millisecond difference per invocation accumulates into material impact.
There is an important property: the Botlet is not editable by humans. It is regenerated by cognition. This matters because any manual improvement to the Botlet’s code — a human who opens the file and improves the logic — becomes debt the moment cognition regenerates it due to an environment change. Regeneration eliminates the human improvements. That is why the spec defines that Botlets are read-only for humans in production: if a human wants to improve the logic, they must improve cognition or the Capabilities, not the Botlet directly.
Pattern Recognition — the entry to the cycle

Botlets are not generated at random. Cognition decides to generate a Botlet when it recognizes a repetitive pattern in the agent’s activity. The component that detects those patterns is Pattern Recognition — an auxiliary primitive of Layer 2 that we already mentioned in Chapter 4.
Pattern Recognition operates on the trace of the agent’s activity: what tasks it did, with what frequency, with what similar inputs, with what results. When a pattern crosses a threshold — the same task repeated more than N times with bounded variability in its inputs, the results stable — cognition evaluates whether it is worth generating a Botlet.
The neurobiological inspiration we mentioned at the outset is reflected in the design of Pattern Recognition. The perirhinal cortex of the human brain implements rapid familiarity — the “have I seen this before?” that occurs in milliseconds, without conscious recollection. Agentive Pattern Recognition implements the analog: rapid detection of tasks similar to past tasks, without the need for deep reasoning. If the answer is yes, the system activates the next level.
The hippocampus implements recollection: the “what exactly did I do last time?”. Pattern Recognition retrieves the specific trace of past invocations, with their parameters, their results, their durations. This information is what cognition uses to decide whether generating a Botlet is worthwhile.
The prefrontal cortex implements conscious decision: the “should I automate this?”. Here cognition evaluates the criteria — frequency, pattern stability, cost of continuous cognition, regeneration risk — and decides. If it decides yes, it triggers the generation of the Botlet.
Three stages, three levels of processing. Pattern Recognition is not a single step — it is a hierarchical process that filters from “potentially interesting” down to “worth automating”. The specification of Pattern Recognition as a Layer 2 tool is out of scope for this book; it suffices to keep in mind that it is the auxiliary primitive that activates the Botlet cycle.
Botlets and the economy of autonomy under subscription

A critical operational property of the Botlet, which we already introduced in Chapter 4 §2 but which deserves development here, is its role in the economy of autonomy under fixed Subscription plans — Claude Pro, ChatGPT Plus, Copilot enterprise.
In these plans, the marginal cost of invoking cognition is zero up to the plan’s limit. The user pays a fixed monthly fee and can invoke the model as many times as they want, until the plan exhausts its quota. This economic structure is very different from pay-per-token models, where each invocation costs and the economy is calculated by real usage.
The problem is that the limit exists. An Autonomous Agent operating continuously in the background, without Botlets, would invoke cognition thousands of times a day — each decision, each validation, each action would consult the model. Under a fixed Subscription plan, the agent would exhaust the user’s quota in hours. Continuous autonomy would be economically impossible.
Botlets are the architectural mechanism for extending autonomy without saturating the plan. An agent that executes its everyday work via Botlets — and only invokes cognition when the environment changes — can operate in continuous background without exhausting the user’s quota. Cognition remains available for real reasoning, not for repetitive tasks that traditional code executes better.
Without Botlets, sustained autonomy under a fixed Subscription is economically impossible.
This is what makes the Botlet an economic lever, not merely a technical optimization. The difference between an agent that costs two hundred dollars a month to operate and one that costs twenty dollars a month to operate, with identical effective capability, is almost always the proportion of tasks it executes via Botlets versus via continuous cognition. An organization that adopts Botlets disciplinedly can operate agents at an order of magnitude less cost than an organization that invokes cognition for every operation.
The commercial consequence is direct: providers that deliver agents with good Botlets can offer competitive pricing and reasonable margins; providers that depend on continuous cognition for every operation face an economic dilemma — either they raise pricing to levels the market does not accept, or they operate with negative margins. This pressure is probably what will lead most serious providers to adopt Botlet architectures in the next two to three years.
Derivation chain and catalog of proto-Botlets
A system’s Botlets do not appear loose: they are derived from what the system needs to do, and they rest on pre-forged pieces from the catalog. The spec fixes that derivation chain as a structural relation:
- Documented use cases — each case requires…
- Necessary Botlets (zero, one, or several; some cases are resolved by cognition without a Botlet) — each Botlet is an instance of…
- Required proto-Botlets from the catalog.
The chain is structural, not methodological. A use case may require no Botlet at all — cognition resolves it directly — require one, or require several; each Botlet that does exist is an instance of some proto-Botlet from the catalog. From here a required property: every conforming Botlet MUST be traceable in this chain, and the append-only log MUST record the origin proto-Botlet of each instantiated Botlet. The method by which use cases are discovered and Botlets are derived does not enter the canon — it is one of several possible ones and lives in the complementary bodies of each implementer; what the canon fixes is the relation and its traceability.
The lower end of the chain — the proto-Botlets — accumulates in common catalogs that produce network effects. Each implementer that consumes a proto-Botlet contributes to its maturation: new variants, tested configurations, refinements. The more implementers consume it, the more cases it covers and the more reliable it becomes; implementer n+1 receives versions refined by implementers 1 through n. A proto-Botlet belongs to a catalog community under one of these modes:
| Membership mode | What is it? |
|---|---|
| Private contract | Closed catalog between client and provider |
| Proprietary codex | Private catalog that an implementer curates (ucodex is an exemplar) |
| Open public catalog | AgencyDomains.org: any implementer consumes and contributes |
| Sovereign agreement | AgencyDomains that adopt common standards without a direct commercial contract |
The modes coexist without tension: one and the same implementer can consume the open public catalog and, on top of it, curate a proprietary codex with its refinements from real cases. The derivation chain and the common catalog are, together, what makes proto-Botlets an economy and not a collection of isolated pieces.
Conformance
A Botlet implementation conforming to this specification must satisfy the following requirements:
| Requirement | Level |
|---|---|
| Code generated by cognition, not written by humans | MUST |
| Execution without invoking cognition in normal operation | MUST |
| Fallback guarantee to manual cognition on failure | MUST |
| Traceability: each invocation recorded in the append-only log | MUST |
| Isolation appropriate to the environment | MUST |
| Automatic regeneration on environment change | SHOULD |
| Pattern Recognition as the trigger of generation | SHOULD |
| Language-agnostic (not tied to a single language) | MUST |
| Recognition of maturity phases (junior, learning, senior) | SHOULD |
| Distinction between seed origin and emergent origin | SHOULD |
| Traceability of the maturity trajectory in the append-only log | MUST |
| Botlet traceable in the use-cases → Botlet → proto-Botlet chain | MUST |
| Origin proto-Botlet of each Botlet recorded in the append-only log | MUST |
| Generic Botler: no Botler subtypes by domain | MUST |
| Botler enforces spec validation without executing it with domain | MUST |
Support for both temporalities (discrete and
continuous) |
MUST |
| Persistent runtime that sustains continuous-temporality Botlets | MUST |
Capabilities
When an experienced finance consultant faces a new problem at a client, they do not start from scratch. They bring along an organized body of know-how that they apply to the particular case: accounting principles, regulatory frameworks, analytical frameworks, professional practices that the industry has consolidated over decades. When an operations consultant tackles a supply-chain problem, they do the same with their own body of knowledge: SCOR, Six Sigma, lean manufacturing, demand planning. Every professional discipline has its tree of know-how, and the consultant’s quality depends in good part on how deep and well organized that tree is in their head.
AI agents face the same problem. An agent operating in finance needs to know finance; an agent operating in legal needs to know legal; an agent operating in marketing needs to know marketing. But “knowing” in this context does not simply mean that the underlying model read finance documentation during training. It means that the agent has modular, composable access to an organized body of professional know-how that it can apply selectively according to the task. This organization is what the Agentive Architecture calls Capabilities.
This section develops the concept of Capability as the canonical primitive of Layer 2 (Cognition). What makes the Capability special with respect to other nearby concepts in the field is its hierarchical structure, its composability, and its explicit distinction from plugins and prompts. An agent without Capabilities has monolithic cognition that conflates domains; an agent with well-organized Capabilities operates with the discipline of a professional who knows the distinctions of their field.
Definition
A Capability is a unit of specialized know-how that an agent understands and applies. It encapsulates the procedural and declarative knowledge of a domain: what is known, how it is applied, what is decided, what is asked when data is missing. Capabilities reside in Layer 2 (Cognition) of the Agentive Architecture. Cognition selects and applies Capabilities according to the task — in the same way that an expert consultant selects and applies professional frameworks according to the problem in front of them.
The agent does not know what the model knows. It knows what its Capabilities allow it to know.
The quotation above distinguishes what Layer 2 knows from what the underlying model knows. The underlying model — Claude, GPT, Gemini — was trained on a massive amount of information that includes, among many other things, professional knowledge. But the agent that lives in Layer 2 does not operate directly with the model’s knowledge. It operates with the Capabilities assigned to it, which are specific curations of know-how applied to particular contexts. An agent that has the General Ledger Capability but not the Tax Capability answers with authority on general accounting but knows that it is not the right source for tax questions. An agent without specific Capabilities operates with the model’s diffuse knowledge, which may be correct in general but is rarely precise on the professional plane.
What is NOT a Capability?
To fix the definition with the precision the spec demands, we contrast the Capability with neighboring concepts that the industry uses carelessly. Each of these neighboring concepts has its legitimate role in AI systems, but none is a Capability, and conflating them leads to architectures that end up being poorly integrated collages.
The term Capability is reserved, in the strict sense, for the cognitive know-how of Layer 2 (Cognition): knowledge that interprets, decides, and reasons about a domain. This reservation matters because other agentive deliverables — connections to source systems, presentation makings — live in other layers, have a different nature, and are built with their own development schemes. Treating them all as Capabilities would force a qualifier onto the term at every use and dilute its value. The section Capability, Connector, and Template — three deliverables per layer fixes the proper terms for each layer.
A plugin lives in the context of a host application. It extends that application with a new function. It is tied to the host: the Excel plugin only operates within Excel, the Notion plugin only operates within Notion. A Capability is not tied to a host — it lives in the agent’s Capability tree and is invocable from any context where the agent operates.
A prompt is a specific linguistic formulation injected into the model on a particular invocation. Prompts are useful, but they are a transient artifact: they change from invocation to invocation, they do not encode persistent knowledge. The Capability can use prompts internally as one of its implementation mechanisms, but it does not reduce to a prompt. A well-designed Capability includes vocabulary, procedural knowledge, declarative knowledge, heuristics, and references to tools — the prompt is only one of the components.
A system prompt establishes the model’s general tone and behavior. It is configuration of the mode of operation, not modular know-how. Capabilities are not system prompts — they can coexist with one, but they capture something else: domain knowledge applicable according to the task, not the agent’s global configuration.
A tool lives in Layer 4 (Access). It is an executable action on the external world: invoking an API, reading a file, sending an email. The Capability decides which tool to invoke and how to interpret its result, but it is not the tool itself. The Capability is knowledge; the tool is action. A finance agent with the Treasury Capability knows when and how to invoke the tool that queries bank balances — but the tool itself is a separate component that lives in another layer.
A skill, in the field’s popular terminology, is a term the industry uses so carelessly that it has practically lost meaning. Various vendors call “skills” plugins, prompts, tools, configurations — without precise distinction. The Capability is not a skill in the generic sense, but the partial overlap of popular usage may confuse the reader. To avoid the confusion, this book reserves the term Capability with a precise definition and avoids using “skill” except when quoting sources that use it.
Three traits distinguish a genuine Capability. Modular: it can be activated or deactivated independently of the others. If an agent has Finance and Legal Capabilities and Legal is withdrawn, the agent keeps operating coherently with Finance alone. Composable: multiple Capabilities can coexist in a single agent and combine when the task crosses domains. An agent that has Finance and Operations can handle a logistics case with financial components without tripping in the transition. Knowledge, not action: the Capability knows; the tools (Layer 4) act. The Capability decides which tool to invoke and how to interpret its result.
Capability, Connector, and Template — three deliverables per layer
An agentive delivery project rarely delivers only a Capability. The cognitive Capability is the protagonist, but it usually comes accompanied by deliverables that live in other layers and are built with different schemes. The spec canonizes three terms, one per layer, so that each deliverable is named for what it is without qualifying the term Capability.

A Capability (strict sense) is cognitive know-how — interpretive, decisional. It lives in Layer 2 · Cognition. It is the project’s protagonist.
A Connector is knowing how to access source systems — a connection with execution power. It is not cognitive knowledge. It lives in Layer 4 · Access. The Connector is what the pre-agentive field knows as the technical integration that touches the external world. A legacy API, when brought into the Agentive World, becomes a Connector (Layer 4), not a Capability.
A Template is the client-specific making over a canonical instrument — a report or dashboard that the Capability produces — in a particular format or rule required by the client. It lives in Layer 1 · Interaction, alongside the Facet, the surface Botlet, and the view Botlet. Anonymized examples: a regulatory template of a basic interconnection offering over the canonical cost report; a managerial monthly financial-close format over the canonical profitability dashboard. The Template is not a Capability, not a Facet, and not a Botlet: the buyer already knows the term “template” from the pre-agentive vocabulary and does not need to learn a new one.
How is each deliverable developed?
Each term has its layer, its nature, and its own development scheme:
| Deliverable | Layer | Nature | Development scheme |
|---|---|---|---|
| Capability (protagonist) | Layer 2 · Cognition | Cognitive, interpretive, decisional know-how | Wingtraining 5 steps (SME workshop · creation · customization · ALPHA · BETA) |
| Connector (companion, if it requires access to source systems) | Layer 4 · Access | Knowing how to access systems; not cognitive knowledge | Integration scheme (survey · configure · test · certify) |
| Template (companion, if the delivery must conform to a presentation expectation) | Layer 1 · Interaction | Making of a canonical instrument in a client format or rule | Making scheme (survey the expectation · make over the canonical instrument · validate) |
Wingtraining, cited in the table, is the canonical development scheme for a Capability in five steps: workshop with the SME (subject-matter expert — the human expert whose knowledge is transferred to the agent), creation, customization, ALPHA (validation with the SME), and BETA (validation in real operation). Its development belongs to the delivery practice, not to this canon; the classification test below uses it as a criterion because it is the operational proof that a scope is a transfer of knowledge — and not an integration or a format.
What is the conceptual structure of an agentive delivery project?
An agentive delivery project is structured as a protagonist Capability (Layer 2) typically accompanied by one or more Connectors (Layer 4) and one or more Templates (Layer 1). In addition, the Capability itself produces, with no extra effort, its information instruments — canonical reports and dashboards —, which remain implicit in the delivery: they require no development scheme of their own because they emerge from the Capability and its interaction layer. The Template appears only when one of those instruments must conform to a specific client form.
Capability or deliverable of another layer? — the test
To decide whether a scope is a Capability in the strict sense, the following three tests must all be yes:
- Is it cognitive know-how? Does it interpret, decide, or reason about a domain — beyond merely connecting or merely formatting?
- Does it have an identifiable SME? Is there a human expert whose knowledge is transferred to the agent?
- Does it pass through the five Wingtraining steps without forcing? Does it make sense to apply SME workshop · creation · customization · ALPHA · BETA to it?
If one or more are no, the scope is not a Capability: it belongs to another layer — Connector or Template, per the mapping in the section Capability, Connector, and Template — or, if it is cognitive knowledge but subordinate to a larger Capability, it is a feature of that Capability (see the next section).
The hierarchical structure — the tree of knowledge

Capabilities are organized in a hierarchical tree. The structure is not decoration — it is the natural way professional knowledge is organized in any serious discipline. Financial analysts think hierarchically: finance has sub-disciplines (accounting, corporate finance, treasury, tax), each sub-discipline has areas (general ledger, accounts payable, reconciliation), each area has specific practices. The hierarchical organization reflects how the professional masters the field.
Below is an example of the canonical tree the spec proposes as a starting point. The tree is not exhaustive — it extends according to the needs of each implementation —, but it illustrates the structure (figure above).
Four structural rules govern the tree. The first: any node is a valid Capability. Both leaf nodes — Reconciliation, Demand generation, Quality — and intermediate nodes — Accounting, Sales & Marketing, Manufacturing — are valid Capabilities. Granularity is decided by context. An agent specialized in daily accounting operation adopts leaf nodes with high specificity; an orchestrator agent that coordinates several specialists adopts intermediate nodes with a panoramic view; a multi-specialist agent combines several roots.
The second rule: it is composable. Capabilities can be shared across agents. A Customer success Capability can live in a commercial team’s agent and simultaneously in a support team’s agent, without duplication. This is operationally critical — the organization does not need to re-build the knowledge for each new agent, but rather assigns already-built Capabilities according to the agent’s role.
The third rule: it is scalable. New branches are added without breaking the existing ones. The Telecom Capability can rise in sophistication — adding sub-branches Network APIs, 5G core, Customer experience — without the other branches of the tree changing. This property is what allows the tree to grow with the organization: each time the organization enters a new domain, it adds branches; each time it deepens an existing domain, it extends branches. The tree never needs a complete rewrite.
The fourth rule: it is inheritable. A Capability inherits context and vocabulary from its ancestors. A General Ledger Capability does not need to re-explain what Accounting or Finance is — that contextualization comes from the tree. This matters in implementation because it allows leaf Capabilities to be more concise: they only need to describe what is specific to their node, not what is already implicit in the tree path.
Anatomy of a Capability
The canonical specification of a Capability includes nine components, which we lay out one by one. Components one and nine are metadata; components two through seven are the body of the know-how; component eight is the binding with the action layer.
The first component is identity: canonical name plus position in the tree. Identity is what makes the Capability referenceable — agents invoke it by name, policies are applied to specific Capabilities, logs record which Capability was invoked.
The second component is vocabulary: technical terms of the domain that the agent must recognize and use correctly. An agent with the General Ledger Capability must distinguish debit from credit without hesitation, must know the difference between manual and automatic entries, must use the concept of fiscal period correctly. Vocabulary is what allows the agent to converse with domain professionals without sounding amateur.
The third component is procedural knowledge: how the typical tasks of the domain are done. How an account is reconciled. How an invoice is validated. How a monthly close is prepared. Procedural knowledge is sequential and operational — it describes steps, not just concepts.
The fourth component is declarative knowledge: verifiable facts and rules of the domain. That accounts payable have due dates. That revenue is recognized when certain criteria are met. That bank reconciliation must occur monthly. Declarative knowledge is factual and permanent — it describes what is true of the domain.
The fifth component is heuristics: professional decision rules of the domain. When an invoice deviates more than five percent from the typical amount, escalate. When a reconciliation has more than ten unmatched transactions, suspend the process and escalate. When a supplier has three claims in six months, flag for review. Heuristics are professional judgment encoded — they capture not what is true of the domain, but what decision a professional would make in each situation.
The sixth component is the associated tools: Layer 4 tools that the Capability typically invokes. The General Ledger Capability invokes tools that query the accounting database, that post entries, that generate reports. The Capability declares which tools it uses so that the agent knows what it needs available when it exercises that Capability.
The seventh component is the parent Capabilities: the hierarchical position from which the Capability inherits context. A General Ledger Capability declares that it is a child of Accounting, which in turn is a child of Finance. The declaration of parents is what enables the inheritance described in the previous section.
The eighth component is the maturity state: Draft / Active / Deprecated. The maturity state is operational metadata — it lets the organization manage the lifecycle of its Capabilities. A Capability in Draft is still being validated; an Active one is approved for productive use; a Deprecated one is legacy that is kept for compatibility but should not be used in new agents.
The ninth component is version: traceability of evolution. Capabilities change over time — professional practices evolve, regulations change, accumulated knowledge is refined. Versions let the organization track the evolution of knowledge and let different agents operate with different versions according to their requirements.
Components two through five — vocabulary, procedural, declarative, heuristics — are what deeply differentiates a well-built Capability from an elaborate prompt. A prompt gives the model context transiently, for a single conversation. A Capability encodes professional knowledge with persistence and modularity. The difference is structural: the agent can consult the General Ledger Capability without the accounting knowledge flooding all its other conversations — it can at the same time have the Marketing Capability without marketing frameworks contaminating the accounting rigor. This separation is what allows agents to operate with the discipline of a professional who switches frameworks according to the task.
Features of a Capability
A Capability exposes internal operations. The spec canonizes the term feature to name them — the practical equivalent of what other vocabularies call feature, operation, skill, or method. A feature is an internal operation that the Capability exposes; it shares with the containing Capability its data model, its SME, its installation, and its runtime. A single costing Capability, for example, exposes as features cost allocation, profitability, and pricing: three dimensions of a single know-how, not three Capabilities.
Capability or internal feature? — the test
A scope is treated as its own Capability if and only if the following three tests are yes:
- Operational independence? Can it be installed and operate without the other capability?
- Cognitive identity? Does it have a data model and SME distinct from the other capability?
- Reusability? Does it have value for more than one consumer or context outside this case?
If one or more are no, the scope is a feature of the containing Capability, not its own Capability.
ID convention
An implementation MAY adopt an identifier convention to trace the
tree of deliverables: the Capability (or deliverable) carries the ID
E<n> —E1, E2—; the feature
carries the composite ID F<n>.<m>
—F1.1, F1.2— where <n> is
the ID of the containing Capability. The convention is optional; what is
canonical is that the feature construct has a name.
What pathologies does the test prevent?
Distinguishing feature from Capability prevents two pathologies observed in real projects:
- Inflation of the deliverable codomain — dimensions of a single Capability are documented as separate Capabilities, multiplying the inventory and diluting portability. The costing example already cited —allocation, profitability, and pricing treated as three Capabilities when they are features of a single one— is the typical case.
- Hiding lock-in — scopes that really are their own Capabilities, with independent lifecycle, data model, and reusability, end up embedded as “sub-capabilities” of another, hiding that they could be installed and ported separately.
The two tests are applied in order: the first decides whether the scope is cognitive at all; only then does the second decide its granularity within Layer 2. If the scope is not cognitive, it is classified directly as Connector or Template by its layer, without running the feature test.
How does cognition operate over Capabilities?
Given an agent with a set of active Capabilities, when the agent receives a request, the processing follows a canonical seven-step flow.
Step one: the user’s request reaches the agent. The agent receives it in natural language — “reconcile last month’s revenue account”, for example.
Step two: cognition classifies the domain of the request. This operation is semantic routing — the agent identifies that the request is about accounting, specifically reconciliation. This identification is based on the vocabulary that the active Capabilities provide to the agent.
Step three: cognition selects the relevant Capabilities. In the example’s case, Finance/Accounting/Reconciliation is the most specific applicable Capability. Cognition selects it together with its ancestors — Accounting, Finance — to have all the inherited context.
Step four: cognition applies the procedural and declarative knowledge of the selected Capabilities. It knows what steps make up a reconciliation, what rules it must follow, what typical errors it may encounter.
Step five: cognition invokes the tools the Capability indicates. It queries the accounting database for last month’s entries, queries the bank statement, runs the matching process.
Step six: cognition composes the response using the domain’s vocabulary and the Capability’s heuristics. It reports the matches found, the unmatched items, the recommendations on how to proceed with the discrepancies. It uses terminology that an accounting professional would recognize as correct.
Step seven: if the request is repetitive — the agent has already done similar reconciliations in the past —, Pattern Recognition suggests generating a Botlet that automates the cycle one through six for future similar requests. Cognition evaluates the suggestion and, if conditions are appropriate (high frequency, stable pattern), generates the Botlet.
An important observation: the Capability does not execute — it is executed by cognition. This matters structurally: the same Capability can be applied with different depth — fast and superficial, or slow and exhaustive — according to the agent’s cognitive model and mode of operation. An agent with sophisticated cognition can apply the General Ledger Capability with all the rigor of an experienced controller; an agent with more limited cognition can apply the same Capability with the depth of a junior. The Capability defines the know-how; cognition defines how deeply it is applied.
Industry verticals as root Capabilities
The tree includes a root dedicated to industry verticals — Telecom, Healthcare, Retail, Banking, Public sector. This is deliberate: each vertical has its own vocabulary, its own regulations, its own canonical processes. The existence of a vertical root separate from the functional roots (Finance, Sales, Operations) reflects a structural property of professional knowledge: verticals and functions are orthogonal.
A generalist finance consultant has functional knowledge — Finance — but no specific vertical knowledge. A finance consultant for telecom has both: Finance (the function) and Telecom (the vertical). The telecom consultant can apply generalist financial frameworks, but also knows the particularities of the sector — the revenue-assurance models specific to telecom, the regulations of the sector’s regulator, the operational systems typical of a carrier. Vertical knowledge is additional, not a substitute, to functional knowledge.
The Capability tree reflects this orthogonality. An agent can simultaneously have Finance/Treasury and Industry verticals/Telecom Capabilities — and the combination produces an agent that operates with functional and vertical knowledge at the same time, exactly like the sector’s expert consultant.
This architecture has two important consequences. The first: vertical specialization is not a prompt — it is a Capability. A “legal agent” or “medical agent” or “telco agent” is not a sophisticated prompt of the general model. It is an agent that loads the corresponding vertical Capability, with its own vocabulary, heuristics, and normative knowledge. This distinguishes Capabilities from generic System Prompts: vertical knowledge is modular, persistent, and composes with other non-vertical Capabilities without contamination.
The second consequence is commercial. This architecture explains the commercial success of the vertical specialists of today’s market: Cursor (coding), Harvey (legal), Jasper (marketing), Fin (customer support). What these products sell is not “a specialized GPT” in their vertical — it is a robust vertical Capability that cognition applies with confidence. The difference from a generic GPT is not marketing; it is structural. The user who tries Cursor for programming does not notice that the difference is the Coding Capability the tool loads; they notice that the answers are correct more often than with a generic GPT, and that is exactly what the well-built Capability produces.
The vertical Capability is the difference between a useful agent and an agent serious about the domain.
Capabilities Marketplace
An emergent property of the architecture is that Capabilities admit a market. A well-built Capability can be distributed across AgencyDomains, versioned and maintained by a specialized provider distinct from the AgencyDomain operator, charged by subscription or license, and audited by third parties as to its correctness and completeness.
This gives shape to a Capabilities economy analogous to the open-source software package economy. Whoever builds and maintains expert Capabilities — for example General Ledger IFRS-compliant, or Telecom 5G core — can operate as a specialized provider without building agents or AgencyDomains of their own. Their product is the Capability itself. Their business model is license or subscription of the Capability. Their clients are organizations that operate AgencyDomains and need verified professional know-how.
The emergent economy has clear precedents. The software industry has had similar economies of specialized components for decades: compiled libraries sold or licensed, certified modules for specific frameworks, best-practice configurations that consultancies sell as assets. The Capabilities economy would be the natural evolution of those models to the agentive field.
The normative specification of the Capabilities Marketplace protocol — package format, versioning model, signature system, charging model — is open work in version 1.0 of this book. Contemporary implementations may adopt ad-hoc packages; consolidation as an industry standard is pending. When consensus arrives, a future version of the book will incorporate it as normative spec.
Locality and availability — operational classification of Connectors
The canonical description above treats know-how as applicable in any context. The operational reality of systems with multiple physical presence — restaurants with locations, bank branches, retail stores, industrial plants — requires an additional classification that the spec formalizes explicitly: locality and offline availability. The classification belongs to the Connectors — the Layer 4 face of the pair that accompanies the Capability —, because what resides somewhere and needs (or doesn’t need) a network is the access, never the knowledge: the Capability that decides when and how to invoke has no locality. It is documented in this chapter because the Capability–Connector pair is delivered and reasoned about together. Without this classification, decisions about what can be invoked from an edge Botlet in offline mode are made in the dark.
The classification operates over two orthogonal axes:
Locality axis
Where the Connector’s components physically reside:
Cloud-resident — the Connector lives in a remote service. Canonical examples: Connector
DTE-SII(Chile’s SII service for issuing electronic receipts and invoices),Transbank-Onepay(bank gateway),Stripe-Connect(payment processing). The agent invokes them over the network; without network there is no access.Edge-resident — the Connector lives at the physical site, associated with local hardware or systems. Canonical examples: Connector
ESC/POS-Printer(thermal printer for tickets and receipts with the ESC/POS protocol connected by USB or serial),Cash-Drawer(the cash drawer of the till),Local-Pinpad(card pinpad connected to the POS),Sensor-Temperatura(cold-room sensor connected by GPIO). The agent invokes them against the site’s hardware; they need no network to operate.Hybrid — the Connector has a local component and a cloud component. Canonical examples: Connector
Client-DTE(signs the document locally, queues it if there is no network, sends it to the SII when the network returns),Client-Pinpad-Deferred-Processing(authorizes locally with PIN and batch, sends to the acquirer when the network returns). The local part operates offline; the cloud part synchronizes when there is network.
Offline availability axis
Whether the Connector can execute without network:
Online-only — requires network to execute. Without network, the invocation fails. Cloud-resident Connectors are typically online-only in the strict sense, although some have variants with a local client that turn them hybrid.
Offline-capable — executes without network. If its external contract eventually requires cloud communication (a voucher that must reach the SII, a transaction that must consolidate at headquarters), it queues and emits outward when the network returns. Edge-resident Connectors are typically offline-capable; hybrid Connectors are too, by design.
Canonical classification matrix
Each conformant Connector explicitly declares its position in the matrix:
| Online-only | Offline-capable | |
|---|---|---|
| Cloud-resident | DTE-SII (without local client) · Transbank Onepay · weather API | (unusual combination; typically migrates to hybrid) |
| Edge-resident | (unusual combination) | ESC/POS-Printer · Cash-Drawer · Sensor-Temperatura · Local-Pinpad |
| Hybrid | (unusual combination) | Client-DTE · Client-Pinpad-Deferred-Processing · Sync-Inventario |
Connection with distributed Layer 3
The classification is structurally necessary when Layer 3 is distributed (Chapter 5 §1). An edge Botler must know which Connectors it can invoke offline. If it does not know, its edge Botlets will attempt to invoke cloud-resident Connectors without network and will fail catastrophically — without network, not even the agentic fallback applies, because cognition lives in the cloud.
The operational rule the classification enables is direct: a senior edge Botlet, at a physical site without network, operates by invoking exclusively edge-resident Connectors and the local part of hybrid Connectors. The cloud-resident ones and the cloud part of the hybrids remain temporarily inaccessible; the deferred effects (sending to the SII, consolidation with headquarters) are queued; when the network returns, the queues drain.
Required properties
| Property | Level | Description |
|---|---|---|
| Explicit declaration of the Connector’s locality | MUST | Cloud-resident, edge-resident, or hybrid. |
| Explicit declaration of offline availability | MUST | Online-only or offline-capable. |
| Specification of offline behavior for offline-capable | MUST | What it does when there is no network, what it queues, how it drains. |
| Deterministic resolution of which component runs in hybrids | MUST | Under what conditions the local component runs; under which it invokes the cloud. |
Capability portability
The previous section classifies where the Connector that accompanies the Capability physically resides — cloud, edge, or hybrid. A distinct property, which the spec formalizes explicitly, is Capability portability: a conformant Capability can be installed and run on any conformant AgencyDomain, without rewriting. This portability is what makes the Capability real property of the client — not of the AgencyDomain that hosts it, nor of the hosting that sustains that AgencyDomain.
The argument is the same no-lock-in one the canon makes for the AgencyDomain, applied one level lower. Just as a conformant AgencyDomain migrates to another conformant hosting platform without being held captive by it, a conformant Capability migrates to another conformant AgencyDomain without being held captive by it. The client who acquires a Capability acquires a portable asset, not a rental tied to a platform.
The two portabilities?
It is worth not confusing two portabilities that operate at different levels:
| Portability | What migrates? | To where? |
|---|---|---|
| AgencyDomain portability | The complete AgencyDomain | To another conformant hosting platform |
| Capability portability | A single Capability | To another conformant AgencyDomain |
What is the Capability ↔︎ AgencyDomain relation?
The relation is asymmetric and explicit: an AgencyDomain hosts and runs Capabilities; a Capability runs on a host AgencyDomain. The Capability is a first-order inhabitant of the AgencyDomain’s Layer 2 — the know-how that gives cognition to its agents —, not a support resource. This is the reason the canonical definition of AgencyDomain names Capabilities among what the AgencyDomain hosts and runs, on a par with autonomous agents and Botlets.
Regulatory certification resides in the certified component, not in the Botlet
A structural property that appears with force in productive agentive systems in regulated industries — gastronomy, health, finance, retail with DTE, pharmacy, telecommunications — and which the spec needs to formalize explicitly: the regulatory certification of operations resides in the certified component the Botlet invokes — the certified Connector, with the regulated Capability that carries its normative knowledge —, never in the Botlet that orchestrates. The separation is necessary because the generated nature of the Botlet makes it impossible to certify a priori, and certifying it a posteriori contradicts its regenerable nature.
The problem
The book defines that cognition generates the Botlet’s code (Chapter 5 §2). But some operations a Botlet executes are regulated: issuance of DTE under SII norm, card payment under PCI-DSS, pharmaceutical dispensing under sanitary registration, financial communication under the corresponding regulator’s norm. For these operations, the regulation requires certification of the component that executes the operation. A system that issues an electronic receipt without SII certification is not legal; a system that charges a card without PCI certification cannot operate.
If certification resided in the Botlet, each Botlet that executes a
regulated operation would have to be certified individually. But a
Botlet is code generated by cognition that regenerates
when the environment changes. Each regeneration would produce a
technically distinct Botlet that would require re-certification.
Regulatory certification over Botlets turns the 95/4/1
cycle into an operational impossibility: each 1% change would require a
regulatory process.
The canonical solution
The spec resolves the tension by separating responsibilities with discipline, and the division respects the chapter’s layer doctrine:
- The Botlet orchestrates. It knows the process flow, validates operational pre-conditions (are there products?, is the table open?, does the customer have their tax ID registered?), captures the event, formats the request according to the certified component’s contract.
- The certified Connector executes the regulated
operation. It receives the request from the Botlet, executes
under all applicable norms, returns the voucher. The
DTE-SIIConnector receives the sale’s detail, signs with the tax certificate, transmits to the SII, receives the folio and electronic stamp, returns the voucher to the Botlet. It is certifiable precisely because it is stable access, not generated knowledge. - The regulated Capability carries the normative knowledge. What the norm demands, how it is interpreted, when a receipt applies and when an invoice, what to do upon a regulator’s rejection — the cognitive knowledge with which cognition decides and validates. It lives in Layer 2, is developed with an SME of the regulatory domain, and accompanies the Connector as its pair.
The separation has three structural consequences:
First, certification is of the certifiable
component. The DTE-SII Connector can be formally
certified — its code is stable, its contract with the SII is explicit,
its behavior is auditable. Certification is one-time work; it holds for
all the Botlets that invoke it.
Second, generated Botlets coexist naturally with regulatory
compliance. A Charge-Table-9 Botlet that
regenerates when the kitchen changes its menu does not break the tax
certification — it keeps invoking the same certified
DTE-SII Connector. The Botlet’s regeneration affects
orchestration logic, not the regulated operation.
Third, the audit boundary becomes sharp. When the regulator audits, the AgencyDomain exposes: the Botlet (business logic, mutable, regenerable) and the certified component (regulated operation, frozen, auditable). The regulatory inspection concentrates on the certified Connector — where the certification resides —, while the business logic is governed with the Trust mechanisms of Chapter 5 §4 without contradicting the regulation.
Canonical pattern
The pattern applies to any regulated industry:
| Industry | Botlet (orchestrates) | Certified component (executes the regulated operation) |
|---|---|---|
| Gastronomy | Charge-Table |
Connector DTE-SII (electronic receipt or invoice) |
| Banking | Process-Payment |
Connector Gateway-PCI-DSS (tokenization +
authorization) |
| Pharmacy | Dispense-Prescription |
Connector Sanitary-Registry (validation and
registration of dispensing) |
| Telecom | Activate-Service |
Connector Subtel-Registry (regulatory registration of
activation) |
| Health | Issue-Prescription |
Connector MINSAL-E-Prescription (certified medical
signature) |
The pattern is uniform: the Botlet contains the mutable business logic; the certified component contains the frozen regulated operation; the regulated Capability supplies the normative knowledge with which cognition governs the whole. The boundary between them is the boundary between what the organization can freely regenerate and what it must keep under certification.
Required properties
| Property | Level | Description |
|---|---|---|
| Regulated components declare their regulatory regime | MUST | Which norm it complies with, before which regulator, with what certification number. |
| Certified Connectors are immutable between audits | MUST | The certified Connector’s code does not regenerate; it changes only under a regulatory process. |
| Botlets may invoke certified components without restriction | MUST | The component’s contract is stable; the Botlet invokes it like any other. |
| Auditability of the boundary | MUST | The log clearly distinguishes Botlet operations (business logic) from certified-component operations (regulated operation). |
Capabilities and Botlets — the relation
Capabilities and Botlets live in different layers and solve different problems, but they interact in a structured way. The Capability lives in Layer 2 (Cognition). It is know-how. The Botlet lives in Layer 3 (Autonomy). It is learned doing. The Capability has the form of vocabulary plus procedures plus heuristics plus tools. The Botlet has the form of traditional executable code. The Capability is persistent and versioned. The Botlet is self-regenerable and ephemeral. The Capability is applied when the agent recognizes its domain. The Botlet is invoked when the agent recognizes the pattern. The Capability is created by human experts or by specialized providers. The Botlet is created by the agent’s cognition, automatically.
The canonical interaction is the following: a Capability can give rise to multiple Botlets. The agent that applies General Ledger repeatedly for a specific company begins to generate Botlets that automate the routine steps of the process — classifying transactions, reconciling accounts, generating monthly reports — without invoking cognition. The Capability remains the same; the Botlets are the efficient residue of its repeated application in a particular context.
This relation is what allows the agentive system to scale economically. Capabilities are the stable knowledge that the organization acquires, maintains, evolves. Botlets are the efficient residue that cognition generates by applying Capabilities repeatedly in specific contexts. The organization invests in Capabilities; the Botlets emerge from use. The investment in knowledge generates savings in operation.
Conformance
An implementation of Capabilities conformant to this specification must satisfy the following requirements:
| Requirement | Level |
|---|---|
| Hierarchical tree structure | MUST |
| Any node is a valid Capability | MUST |
| Composability across Capabilities | MUST |
| Anatomy with vocabulary + procedural + declarative + heuristics | MUST |
| Explicit versioning | MUST |
| Declared maturity state (Draft / Active / Deprecated) | MUST |
| Selection by cognition, not direct execution | MUST |
| Verticals as a dedicated root | SHOULD |
| Open marketplace | MAY (when the normative spec exists) |
| Explicit declaration of the companion Connector’s locality (cloud / edge / hybrid) | MUST |
| Explicit declaration of offline availability | MUST |
| Portability across conformant AgencyDomains | MUST |
| Regulated components (normative Capability + certified Connector): regime declared | MUST |
| Certified Connectors: immutability between audits | MUST |
Evolution frontier
Three active areas of evolution of the Capability primitive deserve mention.
The Capabilities marketplace is the first. The normative protocol is not yet consolidated; when it is, version 2.0 of this book will incorporate it.
Cross-vertical Capabilities are the second. How a Capability can be combined with multiple verticals without contradictions — an agent operating in finance for banking and for telecom simultaneously, for example — requires refinement of the inheritance mechanisms that version 1.0 of the spec describes.
Capability auditing is the third. How to certify that a Capability does what it says it does — that an IFRS Compliance Capability effectively reflects IFRS and not its informal approximation — is a governance problem that the field has not yet solved. The likely solutions will come from the side of traditional professional auditing adapted to the agentive context.
Trust Infrastructure
There is an operational asymmetry that any organization which has tried to bring agentive AI to production recognizes with discomfort: what works in a pilot rarely works in enterprise production. A controlled pilot, with a handful of sophisticated users, closely supervised by the team that built it, can run successfully without explicit governance. Pilots demonstrate technical capability, not operational fitness. The distance between the two is exactly what this section develops.
The figure that most worries the field in 2026 is Gartner’s projection: more than forty percent of agentive AI projects will be cancelled before the end of 2027. The reasons Gartner identifies are three: unforeseen costs, unclear business value, and inadequate risk controls. The third reason — inadequate risk controls — is the one that connects directly with the content of this section. Organizations cancel projects not because the technology does not work, but because the organization cannot defend what the technology does when something goes wrong. The difference between a successful pilot and a cancelled project is typically the maturity of the trust infrastructure.
Trust Infrastructure is the set of cross-cutting properties that allow an organization to trust that its agents operate with autonomy without losing control. It is not an additional layer of the Agentive Architecture — it is a property that cuts across the four existing layers (Interaction, Cognition, Autonomy, Access) and is exercised at different points depending on the specific pillar. This section develops the five pillars with the detail the architect reader needs to design and the executive reader needs to evaluate.
Trust Infrastructure is not what you add after the agent works. It is what separates pilots from production.
The urgency of Trust Infrastructure is no longer only architectural. It is regulatory. Singapore’s IMDA published in January 2026 the first state framework for governance specifically targeting agentive AI. The European Union does the same with the EU AI Act. NIST with its AI Risk Management Framework. ISO/IEC with standard 42001. The question is no longer whether regulators will demand trust infrastructure — it is whether the organization can demonstrate it auditably when asked. Organizations that do not have it operational will face, over the horizon of the next twenty-four months, a binary decision: invest at speed to reach conformity, or suspend agentive operations in regulated markets.
The five pillars
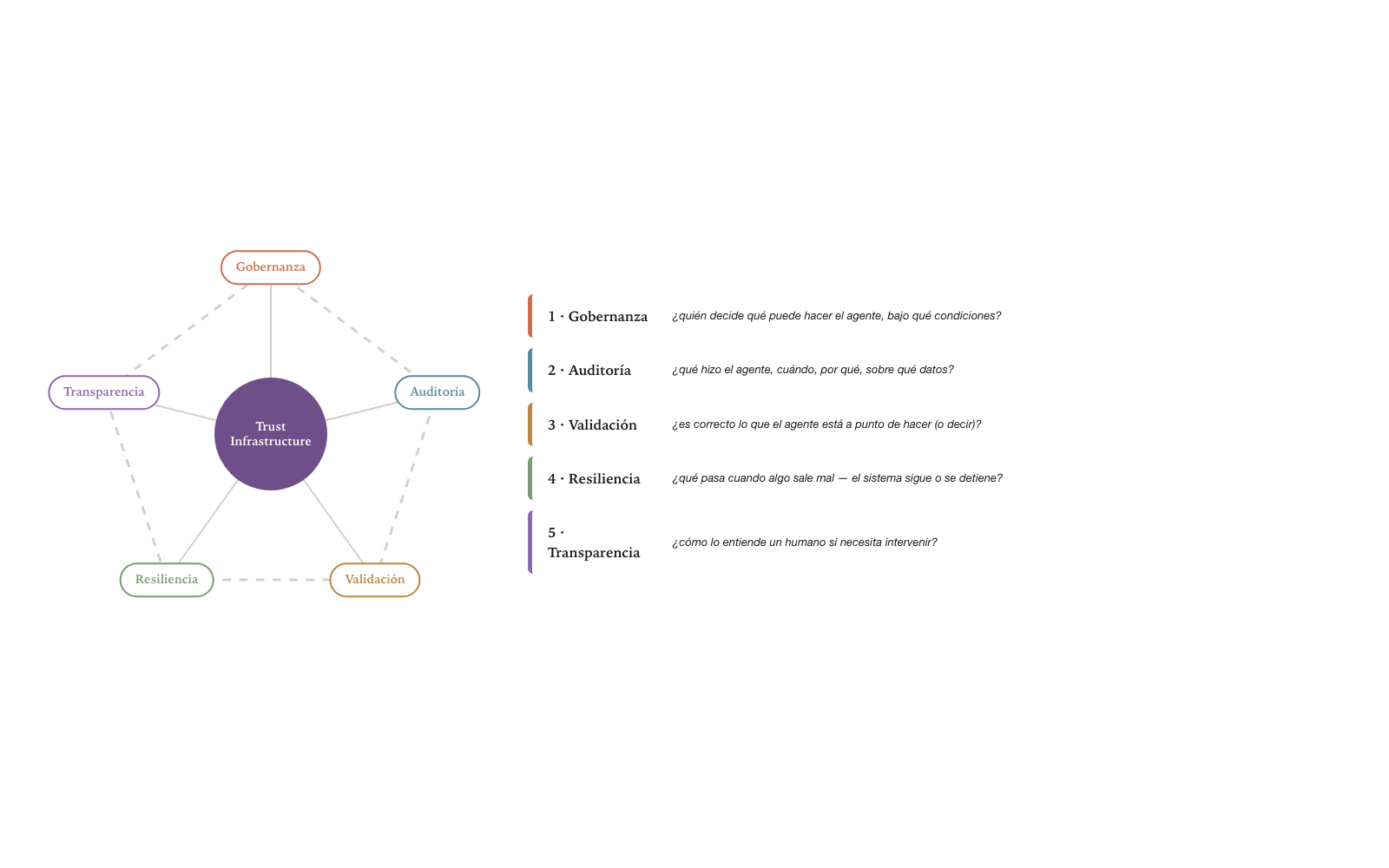
Five pillars constitute Trust Infrastructure. Each answers a specific operational question the organization needs to be able to answer when someone — an auditor, a regulator, a client — questions it.
| Pillar | Question it answers |
|---|---|
| Governance | Who decides what the agent may do, under what conditions? |
| Audit | What did the agent do, when, why, over what data? |
| Validation | Is what the agent is about to do (or say) correct? |
| Resilience | What happens when something goes wrong — does the system stop or continue? |
| Transparency | How does a human understand it if intervention is needed? |
Each pillar is exercised in one or more layers and is materialized with concrete mechanisms. The next five subsections develop each pillar in detail. Afterward we show the cross-cutting map — which pillar operates mainly in which layer — and we close with the regulatory reading of the field.
Pillar 1 — Governance
The Governance pillar defines the set of mechanisms by which the organization establishes what the agent may do, under what conditions, and with what level of supervision. It is the most visible pillar to someone coming from the traditional IT world, because it has the most direct equivalent in known mechanisms — IAM, SSO, RBAC. But agentive Governance is structurally distinct from traditional governance, and conflating the two is a recurrent source of failed projects.
Traditional Governance asks “who can see what data?”. The subject of control is a human with a stable identity; the object is a discrete resource. The question is static: permissions rarely change, and when they change it is by explicit human event (someone was hired, someone was promoted, someone left the company). Agentive Governance asks “what can an agent do, under what conditions?”. The subject is an agent acting autonomously; the object is a sequence of actions the agent can execute with varying degrees of impact. The question is dynamic: conditions change with context, with the moment, with the state of the system. Traditional Governance tools — IAM, SSO, RBAC — are insufficient for this model. They work well for human subjects with stable identity; they do not work for agents that act continuously with varying degrees of autonomy.
The canonical mechanisms of agentive Governance are four. Configurable policies are declarative rules — not embedded code — that define which tools the agent may invoke, over what data, at what times, with what impact thresholds. The separation between policy (declarative) and code (imperative) matters: policies must be changeable without a system redeploy, must be versionable independently of the code, must be auditable without requiring a code review. CRUDLEX permissions — Create, Read, Update, Delete, List, Execute — are a granular model of permissions over tools and data, applicable by user, agent, or context. The full operationalization of CRUDLEX lives in Chapter 8. Human approval for critical operations establishes that the agent may execute low-impact operations autonomously, but high-impact ones stop and request approval. The definition of “high impact” is policy, not technical — the organization decides which thresholds trigger approval. The AI registry is a formal inventory of which agents are active, which Capabilities apply, which tools they are authorized for, who approved them. It is what a regulator will see when auditing, and what the organization must keep updated and accessible.
The field data regarding Governance is raw — Chapter 2 documents it. The story they tell is consistent: most organizations know the problem exists but have not invested enough to solve it, and regulators are on their way to forcing the investment.
Pillar 2 — Audit
The Audit pillar defines the capacity to reconstruct, after the fact, what the agent did, when, why, and over what data — with enough fidelity for forensic analysis, regulatory compliance, or contractual dispute. It is the pillar the organization needs when something goes wrong: if an agent made a decision that produced a bad outcome, or executed an action a client questions, or carried out an operation the regulator wants to examine, the organization needs to be able to reconstruct auditably what happened.
The canonical mechanisms of Audit are four. The immutable append-only log is the central component: every agent action is recorded in a log that admits no retroactive modification. It is only appended to — never edited nor deleted. The log is typically chained cryptographically: each record contains the hash of the previous one, forming a verifiable chain where a retroactive alteration would be immediately detectable. The trace of each action records the agent’s identity, the capability invoked, the tool executed, parameters, result, timestamp, context. Each action generates a complete record that reconstructs the state of the system at the moment of the decision. The decision lineage is the causal chain of reasoning that led to a particular action: what information the agent consulted, what Capabilities it applied, what heuristics it used, what cognition it evaluated. Without lineage, an action appears as an isolated event; with lineage, it appears as the result of a reconstructible reasoning process. Per-action identity tagging ensures that each action is unequivocally attributable to an identifiable agent, not to “the system” or to “the AI”. The distinction matters for accountability: when something goes wrong, it must be possible to identify which specific agent was responsible, and by extension, who configured it, who approved its capabilities, what policy covered its operation.
ISACA — the professional association for audit — notes that agentive AI presents a growing challenge for audit functions because its decision processes lack clear traceability when the system was not designed with audit in mind. The observation is important because it captures a structural property: an agent that combines probabilistic cognition (LLM) with deterministic tools makes decisions whose path is hard to reconstruct if the log is not designed to do so. A log that only records “the agent executed X tool with Y parameters” is not enough — it also needs to record “because the cognition evaluated Z reasoning based on W context”. Agentive Audit demands explicit design from the start. It does not emerge naturally from an agentive architecture — it is built with discipline from the start.
Agentive audit demands explicit design. It does not emerge naturally from an agentive architecture — it is built with discipline from the start.
Pillar 3 — Validation
The Validation pillar defines the capacity to verify that the agent’s response or action is correct before it affects the world. It is the most recent pillar to mature as a category — the AI validation industry is of the last three years — and, simultaneously, the most critical for use cases where the cost of error is high.
The difference from traditional validation is important. Traditional validation verifies formats: is the JSON valid? does the date have the correct format? is the amount a number? Agentive validation verifies semantics: is the agent telling the truth? is it acting within the reasonable limits of the domain? is it exposing data it should not? Traditional validation operates over structure; agentive validation operates over meaning.
The canonical mechanisms of Validation are five. Hallucination detection verifies that the agent’s factual claims are consistent with the sources consulted. It is an active area of research; contemporary mechanisms include self-consistency (asking the same thing in several ways and comparing responses), retrieval-augmented verification (consulting authoritative sources before asserting), and model-as-judge (a second model evaluates the first’s response). Structured-response validation verifies that outputs with a schema — JSON, XML, tables — comply with the expected contract before being emitted. It is the most direct validation, equivalent to traditional validation but applied over outputs the model generated. Prompt injection prevention detects manipulation attempts through malicious inputs disguised as legitimate data. A user who tries to inject instructions into a comments field so the agent executes them as if they were legitimate instructions is a common attack that validation must detect. Products such as Lakera and Lasso Security productize precisely this mechanism. DLP — Data Loss Prevention — automatically detects personal data (PII), sensitive financial information, or classified material in places where it should not appear. If an agent is about to include a social security number in a response to an external user, DLP detects and blocks it. Tokenization replaces sensitive data with tokens before they reach the model. It allows the agent to reason over the data without exposing it to the external cognition provider. The organization keeps the token-to-data mapping in a hardened store — typically an HSM (Hardware Security Module) or dedicated service.
Informatica formulates with precision the transition that Validation represents: “Because agents act without human approval loops, the data they use must be fully trusted, verified, and monitored.” The phrase captures something important. In traditional systems, a human supervises each important operation before executing it — it is the last loop of validation, made of flesh. In agentive systems, that human loop does not exist on every operation — only on critical operations that escalate. Validation has to stand in for the human loop for all the other operations, ensuring that what the agent is about to do is correct before doing it. Without that substitution, the system falls short: either it executes incorrect actions, or it requires human supervision on every operation, nullifying the agent’s productivity.
The validation of a specialist component’s spec admits a structural pattern that deserves note: validation by delegation. The generic Layer 3 runtime (the Botler) enforces the validation of a Botlet’s spec without understanding its domain — it orchestrates the validation point the Botlet or its proto-Botlet provides, hands it the generic context it controls (Capability catalog, identity, AgencyDomain policies), and audits the verdict in the append-only log. The judgment of what makes the spec valid lives in the specialist; the runtime demands and records the validation without executing it with domain knowledge. The development of this pattern lives in the Botlets chapter; here we only link the principle to the Validation pillar.
With the Agentlets (Chapter 5 §7), the Validation
pillar also gains a seat in Layer 3: the bounded
inference of every Agentlet passes through the
cognition_call control point of the Botler’s handle, and
there the mechanisms of this pillar apply — hallucination detection over
its verdicts, structured-output validation against the charter’s
contract, DLP and tokenization over what enters and leaves the model.
The statistical correction that Agentlets introduce into the
muscle-memory layer thus stays confined to declared, auditable Lets —
the thinness discipline the Bounded Concerns Architecture teaches,
exercised inside the Agentive World.
Pillar 4 — Resilience
The Resilience pillar defines the guarantee that the system keeps operating — and the organization retains control — when something goes wrong. It is the pillar closest to traditional software engineering practices — the field of DevOps and SRE has developed resilience patterns for fifteen years — but adapted to the particularities of the agentive system.
The canonical mechanisms are five. The fallback guarantee is the fundamental property we already described in Chapter 5 §2 (Botlets) and that §7 extends to the Agentlet: if a Botlet fails catastrophically, the cognition executes the task manually; if an Agentlet cannot resolve within its charter, it escalates to full Cognition; if the cognition fails, the operation escalates to the human. This guarantee is what distinguishes the agentive system conforming to this spec from any fragile “AI automation”. Structured error handling ensures that errors are typed, actionable, propagated with enough context for the next level to decide. An error that says “something failed” is not structured handling; an error that says “API X returned code Y, parameter Z, in operation W of agent V” is structured handling. Sandboxing ensures execution isolation of the Layer 3 units and of generated code, with strict limits on what they can touch. Detail in the Botlets section. Circuit breakers stop and notify when an agent or Botlet fails repeatedly, before continuing to consume resources. It is a classic resilience pattern adapted to the agentive context: if a Botlet has failed N consecutive times, its automatic execution is stopped and the matter escalates to the human for review. Rate limiting establishes configurable limits on the frequency of invocations, both to the cognition (controlling cost) and to external tools (protecting downstream systems). Without rate limiting, an agent with a badly designed loop can exhaust the system’s resources in hours.
The non-stopping principle the spec guarantees — declared in Chapter 5 §2 — is what allows the organization to delegate operation to agents with the confidence that an isolated failure does not stop the business. Resilience is what makes that confidence reasonable.
Operational business continuity vs agentic fallback guarantee
The fallback guarantee that Pillar 4 describes assumes cognition available: when the Botlet fails due to an environment change, the cognition rescues. This assumption holds in most scenarios — the cognition lives in a highly available cloud and Botlets fail occasionally due to minor changes the cognition resolves effortlessly. But in physical productive systems — premises without network, downed hardware, cut power — the cognition is not available either, and operational continuity needs an additional protocol that the agentic fallback guarantee does not cover.
The spec therefore distinguishes two complementary mechanisms that resolve distinct scenarios:
Agentic fallback guarantee — the cognition executes when the Botlet fails due to environment changes. It is a property of the Agentive Architecture, codified in the Botlet’s spec (§2). It covers the vast majority of failures: the environment changes, the Botlet detects the change, the cognition rescues. This is the property that produces the Botlet’s maturity trajectory from junior to senior.
Operational business continuity — documented manual protocols for when the senior Botlet goes down by exogenous causes and the cognition is not available either. It is an operational property, equivalent to the one any traditional business already has when its system goes down (power cut, downed hardware, catastrophic network, critical provider down). It does not depend on the agentive spec — it depends on the client’s protocol.
The two are not mutually exclusive: they complement each other. The first resolves the Botlet’s learning and most operational failures. The second covers the catastrophic exogenous residue that no system prevents completely.
Connection with the Botlet’s maturity
The connection between the two mechanisms and the Botlet’s maturity trajectory (§2) deserves explicit treatment because it reveals a structural property of the agentive system:
The agentic fallback guarantee is what produces maturity. Every time the Botlet fails due to an environment change, the cognition rescues, regenerates, and returns operation — and that regeneration is precisely what produces the progressive incorporation of variants until reaching senior maturity. Without agentic fallback, the Botlet would be trapped in its initial version, with no way to learn. Without agentic fallback, the Botlet does not mature.
Operational continuity, by contrast, does not bear on maturity. It operates over already-mature Botlets that go down by exogenous causes, not by pending learning. When a senior Botlet goes down because the premises suffered a power cut, it is not a learning problem — it is an operational problem the continuity protocol must resolve (manual till, paper records, later reconciliation).
| Mechanism | When does it operate? | What does it resolve? | Who provides it? |
|---|---|---|---|
| Agentic fallback guarantee | Junior, learning, or senior Botlet with a new variant | Environment changes the Botlet did not anticipate | The agentive spec (Layer 2 + Layer 3) |
| Operational business continuity | Senior Botlet down by exogenous cause, no cognition available | Operational continuity when no computational component operates | Client’s protocol (documented manual procedure) |
Why does the distinction matter?
Without the distinction, operational continuity plans get confused with the agentic promise. A client reads “fallback guarantee” in the product documentation and assumes it covers any failure, including power cuts. When the cut occurs and they discover the system does not operate, they attribute the failure to the agentive architecture — and conclude that “the system fails”.
Recognizing the two properties as separate but complementary mechanisms reduces anxiety about offline and makes clear what the architecture resolves and what the client’s operational protocol resolves. The conversation with the client changes: it is no longer promised that “nothing ever happens”; it is promised that “learning failures are handled by the architecture, exogenous failures are handled by the continuity protocol — and both are documented”.
The conceptual distinction between agentic fallback and operational continuity is the seat of this section. Its operationalization — the per-site field protocol, the degradation modes, and the log marks with which the transition to continuity is recorded — lives in Chapter 8, where the operational requirements are developed (almost all of them MUST, including the traceability of the transition to continuity mode).
Pillar 5 — Transparency
The Transparency pillar defines the human’s capacity to understand, in real time, what the agent is doing and why — with enough detail to intervene if necessary. It is the pillar that connects the other four: Governance defines what it may do, Audit records what it did, Validation verifies what it is about to do, Resilience ensures it keeps operating — Transparency ensures a human can understand all of the above.
The canonical mechanisms are five. Full observability delivers end-to-end tracing of each operation, metrics of latency, cost, quality, and structured events. It is the agentive equivalent of traditional observability systems (Datadog, New Relic, Splunk) adapted to the particularities of the agentive system. Operational metrics measure the success rate of Botlets, regeneration frequency, cognition latency, token consumption, errors per layer. These metrics are what an operations team consults daily to understand the health of the system. Human-consultable traces ensure that the trace of a decision is readable by a technical human, not only by another machine. This matters for reactive audit: when something went wrong and a human needs to reconstruct what happened, they must be able to read the traces directly, not depend on an intermediate automated analysis system. Proactive alerts notify when the agent detects that it is near a limit, failing with unusual frequency, or making high-impact decisions. Proactivity matters: the system does not wait for the human to consult in order to report problems; it reports before they become critical. Governance dashboards give the human in charge a view: which agents are operational, what they do, with what success, over what resources. It is the control interface for the person who governs the system.
AI observability is a mature market category. Products such as Langfuse, LangSmith, Helicone, Arize AI, Braintrust, Weights & Biases cover distinct layers. Agentive transparency does not demand building these products from scratch — it demands integrating them coherently with the other pillars of Trust Infrastructure. The organization adopts the products that best fit its stack and integrates them with the rest of the infrastructure.
Declarative quality contract
The Resilience and Audit pillars are exercised best when what the organization must audit and sustain is declared, not buried in code. The declarative quality contract is the mechanism that enables it: any conforming Botlet MAY declare its quality attributes as structured properties, not as embedded code. Trust Infrastructure reads them uniformly — without coupling to each Botlet’s implementation.
The canonical attributes of the contract are five.
Freshness declares the maximum admissible age of the
data the Botlet consumes. The SLA declares the expected
end-to-end latency, expressed as percentiles (p50,
p99). The degradation policy declares the
behavior on failure — refuse (rejects and delivers
nothing), warn_and_show (warns and shows anyway),
show_last_valid (delivers the last known valid result),
agentic_fallback (escalates to the cognition).
Audience declares the applicable
RLS/CRUDLEX policy for who may consume the
manifestation. The refresh policy declares how it is
renewed — on-demand, scheduled, or
push.
Declared this way, these attributes become cross-cutting mechanisms
that serve two pillars at once. For Resilience, the
degradation policy and the refresh policy are auditable configuration
and not fragile logic scattered through the implementation: the runtime
knows what to do on failure and when to renew without reading the
Botlet’s body, and Freshness and SLA give explicit thresholds against
which to measure whether a result is still trustworthy. For
Audit, the five attributes allow Trust Infrastructure
to audit them uniformly, run them through the AgencyDomain’s
global policies (a policy can harden the minimum
Freshness or veto warn_and_show for a class of operation),
and report them as comparable standard metrics across
Botlets. The organization does not invent a format per Botlet; it
declares against a common vocabulary that the append-only log and the
governance dashboards already understand.
Cross-cutting map — which pillar operates in which layer?
The five pillars are exercised in different layers of the Agentive Architecture, as the figure above synthesizes.
Three readings of the map are useful. The first: Layer 4 concentrates the greatest load. Governance, Audit, and final Validation operate mainly in Layer 4. It is coherent with its nature: Layer 4 is where cognition becomes real action, and therefore where control is exercised. The decisions of what may be done, what is about to be done, and what was done all pass through Layer 4. The second: Resilience lives in Layer 3. Operational continuity rests on the agent’s persistent autonomy, its Botler, its Botlets with fallback. When the agentive system “keeps working” despite some component having failed, that continuity is ensured by Layer 3. The third: Transparency is a cross-cutting property. It does not live in a specific layer — it cuts across all. This demands explicit design of instrumentation in each layer, not added at the end as an additional layer. Each layer emits events, each layer has metrics, each layer contributes to the audit log.
Trust Infrastructure and the regulators
Trust infrastructure is not an architectural decision alone. It is a decision of regulatory conformity before a growing framework of regulation specific to agentive AI. The main frameworks the field faces at the start of 2026 are:
The EU AI Act of the European Union, in force with gradual application between 2024 and 2026. The NIST AI Risk Management Framework of the United States, in force as a voluntary framework but adopted by regulated industries. ISO/IEC 42001, published in 2023 with voluntary certification but growing enterprise adoption. The MGF — Model AI Governance Framework for Generative AI of Singapore’s IMDA, published in January 2026 and notable for being the first state framework specifically for agentive AI (the name keeps generative AI; the body governs agents). The World Economic Forum guidelines on agent onboarding and governance. The NACD guides — National Association of Corporate Directors — for corporate boards.
A common pattern: all these frameworks demand — in formally distinct but functionally equivalent terms — the five pillars described in this section. It is no coincidence. The list of pillars emerges from a functional analysis of the problem, not from imitation of a particular regulator. Any serious regulator that analyzes the risks of the agentive system arrives at a similar list: governance, audit, validation, resilience, transparency. The equation is structural.
The operational consequence for the organization is that investing in Trust Infrastructure is not only an architectural decision — it is a regulatory investment. An organization that adopts the five pillars correctly positions itself to satisfy the four main frameworks simultaneously — EU AI Act, NIST AI RMF, ISO/IEC 42001, IMDA MGF — because they converge on similar functional requirements. An organization that neglects them is left exposed to all four at once, with no structural defense.
Conformance
An implementation of Trust Infrastructure conforming to this specification must satisfy:
| Requirement | Level |
|---|---|
| The five pillars exercised in some layer | MUST |
| Immutable append-only log of every action | MUST |
| Granular CRUDLEX permissions per user / agent / context | MUST |
| Fallback guarantee on failure | MUST |
| Human-consultable traceability | MUST |
| Hallucination detection | SHOULD |
| Prompt injection prevention | SHOULD |
| DLP / tokenization of sensitive data | SHOULD |
| Configurable human approval for critical operations | MUST |
| Conformity with at least one recognized regulatory framework | SHOULD |
| Explicit distinction between agentic fallback and operational continuity | MUST |
| Documented operational continuity protocol for systems with a physical presence | MUST |
Evolution frontier
Three active areas of evolution of Trust Infrastructure deserve mention at the close.
Auditable audit is the first. Cryptographically verifiable protocols that allow an external auditor to verify the log without access to the system. It sits at the intersection with confidential computing technologies and zero-knowledge proofs. When it matures, it will allow external audit without exposing operational data to the auditor.
Agent trust scoring is the second. Composite reliability metrics that evolve with the agent’s behavior, similar to a credit score. It would allow the organization to adopt agents with confidence modulated by their trust score: agents with a high score receive more autonomy; agents with a low score require more supervision.
Trust Infrastructure federation is the third. When two AgencyDomains collaborate (federation, see section 1 of this chapter), how their respective Trust Infrastructures recognize and compose. Does AgencyDomain A’s policy also apply to AgencyDomain B’s invocations? How are contradictory policies reconciled? It is a problem without a general solution in version 1.0 of the spec.
Assistant vs Autonomous Agent

The industry talks about “AI agents” as if they were a single thing. They are not. Beneath that generic term coexist two distinct operating modes, with distinct purposes, distinct economic models, distinct governance models. Conflating the two is probably the most recurrent source of agentive projects that fail in the move from pilot to production.
The two modes are the Assistant and the Autonomous Agent. This section develops the distinction with the detail it deserves, because the practical consequences of maintaining it — or of ignoring it — are enormous.
The distinction
The Assistant lives in Layer 2 (Cognition). It is reactive: it responds when asked, it waits for input, it maintains no Botlets of its own, it has no persistent life between sessions. The user speaks to the Assistant, the Assistant responds, the conversation ends. When the user returns later, the Assistant resumes as if it were the first time — with no memory of the prior exchange except when it is explicitly injected as context. Paradigmatic examples of the Assistant are Claude, ChatGPT, conversational Copilot. They are mass-market and useful products, but structurally they are Assistants — they wait for someone to speak to them.
The Autonomous Agent lives in Layer 3 (Autonomy). It is proactive: it acts on its own initiative, it pursues objectives, it maintains Botlets, it regenerates them when the environment changes, it lives in a continuous background. The user does not speak to it — the Autonomous Agent operates. When the user queries the Autonomous Agent, it is not because the conversation is just beginning, but because the Agent has been operating for hours or days and the user wants to know its status. Paradigmatic examples of the Autonomous Agent are the bots that monitor anomalies on a network, the processes that run nightly reconciliations, the agents that watch SLAs and escalate when they approach violation. They are less visible than Assistants — they do not appear in consumer applications — but structurally they are where most of the agentive system’s economic value is generated.
The Assistant waits. The Agent pursues.
The canonical phrase captures the operational difference well. The Assistant is a shift worker: it shows up when called, it responds, it leaves. The Autonomous Agent is a permanent worker: it lives in the system, it monitors continuously, it executes when warranted, it escalates when necessary.
The distinction is not hierarchical. An Autonomous Agent is not an upgraded Assistant. They are distinct roles with distinct purposes. A mature agentive system contains both modes and composes them. The organization that operates only Assistants falls short because its agents cannot operate in the background; the organization that operates only Autonomous Agents falls short because it cannot handle conversational human requests. Serious systems need both.
The umbrella term Agent covers a third member beyond these two modes: the Agentlet — the packaged agent of bounded charter, living as a catalog unit in Layer 3 alongside the Botlet. It is not a third mode on the same axis — the modes describe how the full agent operates; the Agentlet is a piece the full agent engenders and maintains. Its formalization, and the border that separates it from the Autonomous Agent, live in §7 of this chapter.
Why does the distinction matter?
Three concrete operational reasons justify the attention this section devotes to the distinction.
The first reason is that they are designed differently. The Assistant is designed for conversation. Latency must be perceptible to the human — seconds, typically —, the interface is textual or by voice, the mode is turn-response. When the human closes the conversation, the Assistant ends. The Autonomous Agent is designed for persistent life. Latency is operational — minutes or hours if useful —, with no direct interface to the human except when it escalates, and continuous monitoring of environment events. When the human disconnects, the Agent continues.
An architecture that mixes both modes without distinction produces confused systems: Assistants with Botlets the human does not understand, or Autonomous Agents that require constant human attention to operate. An Assistant that, in the middle of a conversation, launches a Botlet in the background without notifying the user breaks the user’s expectation. An Autonomous Agent that cannot execute anything until the human opens the application loses the point of its autonomy. The explicit distinction in the architecture prevents these confusions.
The second reason is that they are billed differently. The Assistant typically lives under a user subscription model — the human pays for their Claude Pro, their ChatGPT Plus, their Copilot. Cognition is invoked during conversations. For the agentive system, this means that every Assistant operating under the user’s subscription has available quota the system does not pay for directly. The Autonomous Agent typically lives under the AgencyDomain’s centralized tokens model — the organization pays the aggregate consumption of the agents operating on its behalf. For the agentive system, this means predictable but material costs: every decision, every validation, every action of the Autonomous Agent consumes tokens the organization must pay for.
This economic difference determines when each mode is preferable. If the use case allows the human to be in the loop, the Assistant under the user’s subscription is typically cheaper — the cost is absorbed by the user’s plan. If the use case requires continuous autonomy with no human present, the Autonomous Agent under tokens is the only viable option, but with a predictable cost the organization must budget for. Conflating the modes leads to economic errors: Autonomous Agents accidentally operating in subscription mode that exhaust the user’s quota in hours, or Assistants accidentally operating in tokens mode that bill the system for what should run against the user’s subscription.
The third reason is that they are governed differently. The Assistant operates under the human’s immediate control. Validation is conversational: the human reads the response before acting, judges whether it is correct, decides what to do with it. Governance is light — basic permissions suffice. If the Assistant makes a mistake, the human notices it immediately and corrects it. The Autonomous Agent operates without the human’s immediate control. Validation must be systemic: the organization trusts that the agent acts correctly when no one is watching. Governance is robust — it requires the five pillars of Trust Infrastructure operationalized with discipline. If the Autonomous Agent makes a mistake, the human discovers it when they see the log or when the consequence materializes, not in the moment.
Selling an Autonomous Agent with the governance of an Assistant is selling a risk dressed up as a product.
This is the structural reason why products that promise “autonomous agents” but Assistant governance fail in enterprise production. The organization buys expecting autonomy; it receives products that need constant human supervision. The resulting frustration is what feeds the wave of cancellations Chapter 2 documents.
Operational anatomy
We lay out the operational flow of each mode to make the distinction concrete.
The Assistant
The Assistant’s flow is linear and conversational. The human formulates a request. Cognition — Layer 2 — receives it. Cognition applies the relevant Capabilities to understand the domain of the request. If it needs additional information, it invokes tools. It composes the response. It returns it to the human. The human keeps conversing or closes the session. When the human leaves, the Assistant does not persist — unless the system implements explicit memory (which is a feature, not default behavior).
What is characteristic of the Assistant is that it does not operate when the human is not present. Cognition is available on demand; when there is no demand, there is no activity. This is efficient for conversational use cases but is a severe limitation for cases where the work needs to run at predictable moments or in response to external events.
The Autonomous Agent
The Autonomous Agent’s flow is continuous and proactive. The agent lives in the background. It detects stimuli from the environment — changes in data, alerts, events. When a stimulus triggers a response, it applies the relevant Botlets. If the Botlet executes successfully, the operation ends. If the Botlet fails or the case is new, the agent invokes cognition to resolve it. It executes the corresponding action — it invokes a Layer 4 tool. It records everything in the append-only log. If the operation crosses impact thresholds defined by policy, it escalates to the human. It returns to waiting for the next stimulus.
What is characteristic of the Autonomous Agent is that it lives persistently. Its life is independent of any human session. The agent operates while the organization operates, not only when someone speaks to it. This demands supporting infrastructure — state persistence, continuous monitoring, active governance — but it produces operational capacity the Assistant cannot deliver.
How do they cooperate in a mature system?
A mature agentive system contains both modes and composes them. The typical composition works like this: the Autonomous Agent operates continuously in the background executing objectives; the Assistant handles human requests that typically query the Autonomous Agent’s status or request adjustments to its operation.
When a CFO asks their Assistant “what is the cashflow status this week?”, the Assistant recalculates nothing — it queries the status the financial Autonomous Agent has been continuously maintaining. The conversation is fast because the heavy work was already done in the background. The Assistant serves as the human interface to the status the Agent maintains.
When the same CFO adjusts the cashflow thresholds — “from now on, escalate to me when the projected balance falls below X” —, the Assistant communicates the adjustment to the Autonomous Agent, which incorporates it into its continuous logic. The human interaction is momentary; the effect operates persistently.
This composition is not optional for serious systems. An organization that operates only Assistants has a limited agentive system: humans must actively ask for each thing. An organization that operates only Autonomous Agents has an intransigent agentive system: humans cannot converse with the system, only receive alerts or query logs. Mature systems need both modes cooperating.
Recurrent anti-patterns
Three recurrent anti-patterns produce the failures the industry documents.
Anti-pattern A: selling an Assistant as an Autonomous Agent
A product that requires the human to invoke it every time is an Assistant, even if its marketing says “autonomous agent”. The operational criterion is direct: if the system stops doing work when the human disconnects, it is not an Autonomous Agent. It is an Assistant. The consequence of this anti-pattern is that the client buys expecting autonomy and receives assistance with inflated vocabulary. The ensuing frustration is predictable: the client compares what was promised with what was received, discovers the gap, cancels.
Anti-pattern B: building an Autonomous Agent with Assistant architecture
A system that aims to be autonomous but operates by invoking cognition on every action. It works in pilot. It fails in production on cost and on speed. The economics behind this anti-pattern — why Botlets are the architectural answer that avoids collapse at scale — is developed in Chapter 5 §2 (Botlets). Here it suffices to retain the symptom: if the system stops working economically when volume moves from pilot to production, it is incurring this anti-pattern.
Anti-pattern C: governing an Autonomous Agent with Assistant policies
Assuming that basic permissions over data suffice when the agent operates autonomously. This is a grave error. The Autonomous Agent operates without immediate human supervision; it needs the robust governance described above — the five pillars of Trust Infrastructure —, not just access controls. The consequence: the agent acts outside reasonable bounds without anyone noticing until the incident. It is the typical cause of the risky behaviors that Chapter 2 documents as predominant in the field.
The difference between Assistant governance and Autonomous Agent governance is categorical. For the Assistant, the human who reads the response before acting closes the validation loop; it suffices that the system not allow obviously prohibited actions. For the Autonomous Agent, the human is not in the loop — validation, audit, impact limits, traceability, everything must be systemic (the Validation pillar that supplies that human loop is developed in Chapter 5 §4). Applying Assistant governance to an Autonomous Agent is building a system with no safety net under the trapeze.
The cooperative evolution
As the agentive system matures, the proportion of work executed by Autonomous Agents grows relative to that executed by Assistants. This progression is an observable property of the field, and it reflects the organization’s transition across the Nadella Line.
In the early stages, typically ninety percent of agentive work operates in Assistant mode: the human stays at the helm, the Assistant helps with each task, the Autonomous Agent is marginal. In the adoption stages, the proportion shifts to seventy percent Assistant and thirty percent Autonomous Agent: the first functions — typically repetitive operational ones — move to autonomous operation. In the maturity stages, the proportion balances around fifty percent of each mode: the Autonomous Agent operates complete functions while the Assistant handles human queries. In the advanced stages, the proportion inverts — the Autonomous Agent executes seventy percent of the work and the human intervenes mainly to define rules, supervise, handle exceptions.
The Nadella Line separates the world where Assistants dominate from the world where Autonomous Agents dominate.
This progression is what Chapter 2 described as the transition from the online enterprise to the real-time enterprise. An organization that lives with ninety percent Assistants is an online enterprise — humans assisted by AI that wait to be invoked. An organization that lives with seventy percent Autonomous Agents is a real-time enterprise — systems that operate autonomously with humans governing the whole.
How to identify the right mode?
For a given task, is an Assistant or an Autonomous Agent preferable? Four criteria help decide.
The first criterion: must the human see every decision?. If the answer is yes — because the decision requires human judgment, because regulatory responsibility demands supervision, because the cost of error is very high —, an Assistant is preferable. If the answer is no — because the decision is repetitive with clear criteria, because the volume is too high for human supervision, because speed demands it —, an Autonomous Agent is preferable.
The second criterion: is the task triggered by the human or by the environment?. If the human triggers it — the human formulates the question, the human requests the operation —, an Assistant is preferable. If the environment triggers it — an external event, a change in data, a monitoring alert —, an Autonomous Agent is preferable.
The third criterion: is the task sporadic or continuous?. If it is sporadic or variable — it happens a few times a day, at unpredictable moments —, an Assistant is preferable. If it is continuous or repetitive — it happens many times, with regularity —, an Autonomous Agent is preferable.
The fourth criterion: does conversational latency matter?. If the human waits for a response — the conversation has a turn-response dynamic —, an Assistant is preferable. If the operation runs in the background with no immediate latency pressure, an Autonomous Agent is preferable.
The rule of thumb that synthesizes the four criteria: if all four point to Assistant, use an Assistant. If all four point to Autonomous Agent, use an Autonomous Agent. If the mix is ambiguous, design both modes cooperating: an Assistant that queries the status maintained by an Autonomous Agent in the background. This composition is the one mature systems operate.
Conformance
An implementation that offers both modes conformant with this specification must satisfy:
| Requirement | Level |
|---|---|
| Explicitly distinguish Assistant from Autonomous Agent in API and documentation | MUST |
| Assistant lives in Layer 2; does not require Layer 3 | MUST |
| Autonomous Agent lives in Layer 3; persists state between sessions | MUST |
| Autonomous Agent exercises the five pillars of Trust Infrastructure | MUST |
| Composability: Assistant can query the Autonomous Agent’s status | SHOULD |
| Distinction of billing model between the two modes | SHOULD |
| Prevention of the three anti-patterns | MUST |
Facets
The primitives the five preceding sections described — AgencyDomain, Botlet, Capability, Trust Infrastructure, Assistant vs Autonomous Agent — live mainly in Layers 2, 3, and 4 of the Agentive Architecture. Layer 1 (Interaction) had been left without a primitive of its own: only described as generation regimes (Chapter 4 §1) and as composition of presentation Botlets (shell, view, operation). What was missing was a name for the atomic piece out of which those surfaces are built.
This section formalizes the Facet as the sixth canonical primitive — the minimal unit of Layer 1, an instrument the agent invokes during conversation or assembles into presentation Botlets.
The Botlet is the agent’s muscle memory. The Facet is an instrument the agent picks up while it thinks.
Definition
A Facet is an atomic, reusable component of Layer 1 (Interaction) that offers the user a specific form of non-conversational interaction: a freehand drawing board, a catalog-picker, a color matrix, a calendar, a clickable map, a slider, a drag-and-drop ordering, a file picker, a configurable canvas view. One of the many faces that interaction with the user can take at a given moment.
The Facet is an instrument, not a process. It lives and operates in Layer 1. It is invoked by cognition during active interactions or assembled by Layer 1 Botlets (shells and views) as a piece of their internal composition.

Facet vs Botlet — the canonical distinction
The Facet and the Botlet are two of the agent’s software primitives. They are easily confused because both are pieces with an identity of their own that the agent uses to do things. The canonical distinction:
| Axis | Facet | Botlet |
|---|---|---|
| Layer | Layer 1 (Interaction) | Layer 3 (Autonomy) |
| Nature | Interaction instrument | Agent’s muscle memory |
| When does it operate? | During active conversation | In the background, with no cognition present |
| Activation | Cognition invokes it explicitly | Pattern Recognition or external call |
| Fallback guarantee | NO — if it fails, the agent reverts to text | YES — cognition executes manually |
| Life cycle | Ephemeral (lives as long as the task) | Persistent across sessions |
| Regeneration | No regeneration cycle | 95/4/1 cycle with regeneration |
| Maturity phases | Not applicable | Junior · learning · senior |
| Reuse | Flat instrument catalog | Catalog by capability and domain |
The ontological difference matters: the Botlet automates; the Facet interacts. A Botlet executes consolidated know-how without immediate human participation. A Facet opens a visual-manipulative channel of communication with a human who is active in the conversation.
Two canonical uses
Use 1 · Direct invocation by cognition
The agent, during a conversation, decides that the information it needs from the user can be obtained faster through a Facet than by continuing the verbal dialogue. It composes an ephemeral surface with one or several Facets, presents it to the user, receives the information, and the conversation continues. The ephemeral surface is not a Botlet and does not persist — it lives as long as the immediate task.
This use directly realizes the GUI generated on-the-fly regime of Chapter 4 §1. The Facet is the piece that materializes that regime.
Use 2 · Composition in presentation Botlets
The shell and view Botlets (Chapter 4 §1, Composition of Layer 1) assemble Facets as internal pieces of their construction. The “order detail” view uses the “product matrix” Facet + the “calendar” Facet + the “customer picker” Facet. The view Botlet defines the orchestration, the layout, the data flow between pieces; the Facets are the individual instruments the Botlet puts on the screen.
This use lets persistent surfaces (regime 3 of Chapter 4 §1) be built by reusing a Facet catalog, without each view Botlet having to reinvent every atomic component.
Declared bounded interaction
A piece of information already materialized — a self-contained snapshot the agent forged in its Engineering time — can carry interaction over its own data without ceasing to be a reproducible piece. But not all interaction is of the same kind. Declared bounded interaction is the category that separates what a piece can offer from what belongs to another primitive.
The distinction is drawn between two interactivities:
- Free exploration launches new and arbitrary queries
against the source (ad-hoc drill or pivot), operates over an open space,
loses reproducibility, exceeds
G1(the Botlet generations, Chapter 5 §2), and lives outside the information proto-Botlet — in another Botlet or in cognition itself. A piece of information MUST NOT absorb it. - Declared bounded interaction operates over the
already-materialized snapshot, within a declared space (dimensions and
values bounded in advance), preserves reproducibility, is
G1—configuration, not code— and lives in the piece itself, realized via a Facet.
| What distinguishes them? | Free exploration | Declared bounded interaction |
|---|---|---|
| New query against the source | yes, arbitrary (ad-hoc drill/pivot) | no — operates over the already-materialized snapshot |
| Interaction space | open | declared (bounded dimensions and values) |
| Reproducibility | lost | preserved (same config + data → same artifact + same set of controls) |
| Generation | exceeds G1 |
G1 (it is configuration, not code) |
| Where does it live? | another Botlet / cognition (Layer 2 + Layer 1) | in the piece itself, via a Facet |
Embedded Facet
The mechanism that realizes declared bounded interaction is already
canonical: it is the composition of Facets (Use 2), applied inward into
a materialized piece. It is the piece that composes the
Facet — not the Facet that composes others —; the Facet remains atomic.
An embedded Facet is a Facet bounded to a declared
dimension of the piece’s own data — a filter, a segmenter, an appearance
selector. When it is activated, the piece’s data-bound elements
—KPIs and measures as declared aggregations (sum,
ratio, and the like) over the embedded dataset,
distributions, traffic lights— are recomputed
client-side over the filtered subset: the aggregation is
declared once and re-evaluated when the subset changes. Cognition does
not explore; the Facet filters the snapshot.
The witness case is an attendance dashboard with a filter by area: the user selects one or several areas and the piece recomputes its KPIs and its traffic light over the subset.
This recognizes a third use of the Facet — an extension of Use 2 toward the materialized piece —: the Facet vs Botlet distinction admits this third use without altering the nature of the Facet, which remains ephemeral and without a fallback guarantee. What is new is that the piece can compose it for bounded interaction, in addition to invocation by cognition during conversation.
Associated agentive behavior
The existence of the Facet as a canonical primitive enables a specific agentive behavior: the agent, during a conversation, estimates in real time whether the information it needs is best obtained verbally or visually. When it estimates that the visual path wins, it offers an appropriate Facet.
The calculation is the agent’s own cognitive act, not a pre-programmed feature of the product. The Facet as a primitive enables the decision; the heuristic exercises it.
Canonical heuristics for invocation
| Nature of the information | Recommended modality |
|---|---|
| Low dimensionality + well structured (a yes/no, a date, a number) | Conversation |
| High dimensionality (multiple related fields) | Form or composition Facet |
| Hard to verbalize (color, position, shape, gesture) | Specialized Facet (color matrix, map, drawing) |
| The user already has it in spatial or visual form (a layout, a map, a drawing on paper) | Facet that receives that form directly |
| Comparison among multiple options | Catalog-picker Facet with comparative view |
| Configuration with many independent dimensions | Panel Facet with sliders and toggles |
| Open creative work (not an answer to a closed question) | Canvas or easel Facet |
Anti-heuristics (when NOT to offer a Facet)
- When the question is genuinely closed and verbal — offering a Facet adds friction, it does not reduce it.
- When the user is on a channel with no graphical capability (pure voice, IVR, SMS) — the Facet is not invocable.
- When the cost of loading the Facet exceeds the benefit of the visual interaction (single-step interactions, trivial data).
- When the conversation is in flow and the Facet interrupts it inappropriately.
The agent that learns to calibrate these decisions — when to offer, when not to — operates in a full Layer 1. The one that only converses stays at the middle of the possible interactive range.
When a Facet is composed inside a materialized piece (declared bounded interaction), the decision ceases to be conversational and becomes part of the piece’s configuration: the agent declares the space of controls at Engineering time, preserving the reproducibility —a MUST property of the information artifact— already established above.
Anatomy of the Facet
The canonical specification of a Facet includes six components:
- Identity — canonical name (e.g.:
pizarra-dibujo,matriz-colores,calendario-rango) plus version. - Interaction modality — what kind of input it accepts (touch, mouse, keyboard, gesture), what kind of output it produces.
- Input schema — the data the invoker (cognition or view Botlet) passes to it when instantiating it.
- Output schema — the data it returns when the user completes their interaction.
- Internal state — what it keeps while active (intermediate selections, partial edits, undo stack).
- Channel compatibility — which Layer 1 channels support it (web, mobile, kiosk, not supported on voice).
Facets are published in a flat catalog: there is no hierarchy of Facets because each one is atomic. What there is is a growing set of available instruments, indexed by modality and by application domain.
Emergent catalog
The industry converges gradually toward a canonical set of reusable Facets — the equivalent of the UI component catalog of the pre-agentive eras (Material, Bootstrap, Ant Design), but with the ontological difference that these components are invocable by cognition and do not serve solely to build humanly programmed applications.
Some emergent canonical Facets:
pizarra-dibujo— freehand drawing surface.catalogo-selector— view of items with selection.matriz-colores— palette or individual color picker.calendario-rango— date or date-range picker.mapa-clickeable— map with selectable points.slider-multi— one or several related sliders.dragdrop-orden— reordering of items.formulario-dinamico— form with fields generated on the fly.lienzo-creativo— open canvas for artifact production.selector-archivo— invocation of the client’s file system.
The spec does not close the catalog: new Facets are coined as the industry identifies canonical modalities that justify a primitive of their own.
Conformance
A Facet implementation conformant to this specification must satisfy:
| Requirement | Level |
|---|---|
| Identity and version declared | MUST |
| Explicit input and output schema | MUST |
| Channel compatibility declared | MUST |
| Atomicity — does not internally compose other Facets | MUST |
| Explicit Facet vs Botlet distinction in documentation | MUST |
| Direct invocability by cognition during conversation | MUST |
| Composability within shell and view Botlets | MUST |
| Composed in a materialized piece as declared bounded interaction (declared space of controls, no new queries) | MAY |
| Preservation of the piece’s reproducibility when composed as an embedded Facet (client-side recomputation, no Capability invocation) | MUST |
| Public catalog of Facets available to the AgencyDomain | SHOULD |
| Invocation heuristics documented for cognition | SHOULD |
Evolution frontier
Three active areas of evolution of the Facet as a primitive deserve mention.
The catalog standardization is the first. The industry has not yet consolidated a universal canonical set of Facets. Each agentive platform defines its own, with partial intersections. The emergence of a common catalog with stable identities would let agents operate over any conformant AgencyDomain.
The federation of Facets is the second. When two AgencyDomains collaborate (federation, Chapter 5 §1), the Facets one exposes must be invocable from the other. The spec does not yet define a formal protocol for federated Facet invocation — it is open work.
The channel negotiation is the third. A Facet declares which channels it supports. Cognition must negotiate — if the user is on voice, it cannot offer the Facet; it must degrade to conversation. Without this explicit negotiation, surfaces fail on unexpected channels. The spec requires declaration but does not yet formalize the degradation protocol.
Agentlets
At the entrance of an emergency room there is a triage nurse. Her task is the same all day: receive the patient, assess them, classify them — red, yellow, green — and route them. The task is repetitive in its form; no repetition is identical to the previous one. Every patient arrives with different symptoms, different histories, signals that appear in no manual exactly as they present. The nurse cannot do her job on muscle memory — every classification demands fresh judgment —, but neither does she need the chief of internal medicine for every patient: her judgment operates within a bounded protocol, and when the case exceeds the protocol, she escalates. The triage nurse is neither a reflex nor the hospital’s full deliberation. She is a third thing: routine judgment, packaged into a role.
Agentive systems are full of work with that shape. Classifying the emails that arrive at an operational inbox. Triaging monitoring alerts. Summarizing every new document that enters a case file. Extracting the entities from an invoice never seen before. Judging whether a message warrants immediate interruption or can wait for the morning briefing. These are tasks recurrent in their form but fresh in every instance: the pattern is stable, the execution demands interpretation. They do not mature toward determinism — not for lack of regenerations, but by nature.
The canon, up to this point, gave them two homes and neither was the right one. The first home is the Botlet: but the Botlet is non-LLM code by definition, and forcing an interpretive task into deterministic code produces exactly the fragility the architecture exists to avoid. The second home is the full Cognition of Layer 2: it works, but at the cost of the system’s most expensive path — deliberative, conversational, sized for the genuinely new — applied to a pattern that repeats a hundred times a day. Between muscle memory and full deliberation, the middle rung was missing.
This section formalizes the Agentlet as the eighth canonical primitive — the Botlet’s sibling unit whose execution body invokes bounded inference. The Agentlet is the home of routine judgment: packaged pattern on the outside, bounded judgment on the inside.
The Botlet is muscle memory. The Agentlet is packaged routine judgment. Cognition is reserved for the genuinely new.
Definition
An Agentlet is a packaged unit of Layer 3 (Autonomy), sibling of the Botlet, whose execution body invokes bounded inference: a model sized to the task, applied within a charter the spec declares. Like the Botlet, it is a configured instance of a pre-forged piece — the proto-Agentlet —, it is hosted by the Botler, and it is engendered and maintained by the agent. Unlike the Botlet, each of its executions exercises judgment: it interprets the concrete instance in front of it rather than executing deterministic code.
The phrase that fixes the sibling doctrine: an Agentlet is a
Botlet with judgment inside — no more, no less. It lives
exactly like its sibling. It inherits by structure, not by exception,
the entire apparatus of the Lets — the packaged units of Layer 3 —: the
proto-/instance pattern, the catalogs and their network effects, the
source-code vs spec separation, manifestation and
temporality
(discrete/continuous), the declarative quality
contract, the derivation chain, the append-only log, and the operation
API verbs (specialize ·
invoke/schedule ·
read/subscribe ·
status/activate/deactivate/retire).
What changes is a single attribute — the body invokes inference — and
from that attribute follow, in cascade, the differences the rest of this
section develops.
Four properties define the conformant Agentlet. The first is that its charter is declared in the spec: what task it resolves, over what inputs, with what outputs, within what limits. The Agentlet does not choose what to do — its inference is spent on how to do its own work, never on deciding what its work is. The second is that its inference is bounded: the spec declares the model (sized to the task, not the frontier model of Cognition), the Capabilities it may consult, and the budget per execution. The third is that all of its inference passes through the Botler: the controlled handle the Botler hands it includes the cognition control point, so that every model call is metered, budgeted, validated and audited — bypass is structurally impossible, not merely forbidden. The fourth is that it carries a fallback guarantee toward full Cognition: when its bounded inference cannot resolve the case — the charter does not reach, the verdict’s confidence falls below threshold, the input resembles nothing anticipated —, the Agentlet escalates and Layer 2 Cognition rescues. The process never stops.
The smuggling rule
The border between the Botlet and the Agentlet is a binary attribute, and the spec protects it in both directions:
- If there is inference in the body, it is an Agentlet. A Botlet with a model call hidden in its code is non-conformant — it smuggles cost and non-determinism into a unit whose guarantees (near-zero marginal cost, converging maturity, senior offline operation) depend on having neither.
- If there is no inference in the body, it is a Botlet. An Agentlet whose charter turned out to be resolvable with deterministic code is a misclassified Botlet — and a misbudgeted one: it pays tokens for work muscle memory would do for free. Cognition, upon detecting it, crystallizes it: it generates the Botlet that replaces it.
The second direction of the rule also describes a natural trajectory: there are tasks that enter the system as Agentlets — because at first every instance seemed to demand judgment — and that, with accumulated operation, reveal a crystallizable core. Cognition extracts that core into a Botlet and leaves the Agentlet only the genuinely interpretive residue, or retires it altogether. The mature system migrates work down the cost ladder: from Cognition to Agentlets, from Agentlets to Botlets.
Agentlet vs Botlet — the canonical distinction
| Axis | Botlet | Agentlet |
|---|---|---|
| Execution body | Non-LLM code; zero inference | Invokes bounded inference, via the Botler’s handle |
| Metaphor | Muscle memory | Packaged routine judgment |
| Natural task | Recurrent and crystallizable into code | Recurrent in form, interpretive in every instance |
| Determinism | Converges with maturity | Does not converge — correctness is statistical by nature |
| Marginal cost | ~0 (traditional compute) | Tokens per execution, budgeted in the spec |
| Maturity | Junior → senior; senior = exogenous-only failures | Its own semantics: stabilized spec, decreasing escalation rate |
| Offline | Senior reliably operable offline | Only with an edge-resident model, declared in the spec |
| Fallback | Cognition executes manually | Escalates to full Cognition |
What the table does not contain matters as much as what it does: proto-/instance, catalogs, spec, manifestation, temporality, quality contract, derivation chain, log, operation verbs, hosting by the Botler, genesis by the agent — all of that is identical, because it is predicated of the genus and not of the species. The spec calls the genus by its proper name: the Lets — the Botler hosts Lets; the Botlet and the Agentlet are its two species. The name derives from the family’s own morphology and is, like Botler, normed vocabulary of the canon — not a ninth primitive. The canonical runtime relation is stated in its general form — 1 Process = 1 Botler + N Lets — and each context instantiates it to the species at hand.
Agentlet vs Agent — agenda vs charter
The primitive’s name claims membership in the Agent family, and the spec grants it: the umbrella term Agent covers, from this version of the canon onward, three members — the Assistant (Layer 2, reactive), the Autonomous Agent (Layer 3, proactive, an inhabitant) and the Agentlet (Layer 3, packaged). The concession is honest — the creature genuinely reasons, with a genuine model — but it demands drawing the border with the Autonomous Agent with the same rigor with which the canon drew Facet vs Botlet, because the two live in the same layer and both use inference.
The border fits in one line: the Agent has an agenda; the Agentlet has a charter. The Autonomous Agent pursues goals — it decides what to do, when, with what means, and engenders the units it needs. The Agentlet executes the task its spec declares — its judgment operates within the charter, never over the charter.
| Axis | Autonomous Agent | Agentlet |
|---|---|---|
| Nature | Inhabitant of the AgencyDomain | Catalog piece — instance of a proto |
| Born through | Provisioning (six-phase lifecycle, first-order identity) | specialize over a proto-Agentlet |
| Agenda | Pursues goals; decides what to do and when | Fixed charter declared in the spec |
| Cognition | Full: its own bindings, complete Capability tree, multi-LLM | Bounded: sized model, the Capabilities the spec declares |
| Engenders | Generates and regenerates Botlets and Agentlets | Engenders nothing; it is maintained |
| Fallback | Is the fallback — above it, only the human | Escalates to Cognition via the Botler |
| Governance | Exercises the five Trust Infrastructure pillars (MUST) | Governed through the control points of the Botler’s handle |
The border test protects the category from bleeding upward. Three questions; any answer on the side of autonomy means the piece is an Agent, not an Agentlet:
- Does it choose its own goals, or does it receive them declared in the spec?
- Can it alter its own process or engender other Lets?
- Is its identity that of an inhabitant (provisioning) or of an
instance (
specialize)?
An Agentlet with a fat charter, an internal loop and its own criteria about what to pursue is not an advanced Agentlet: it is an Autonomous Agent in disguise, operating without the governance its nature demands — the agentive version of anti-pattern C in §5.
The Botler as guardian — same runtime, one more control point
The Agentlet brings no runtime of its own. It is hosted by
the same Botler that hosts the Botlets, and this
decision is one of principle, not convenience. The Botler is generic by
definition: it manages lifecycle, isolation and execution of any unit
without understanding its domain — and calling a model is not domain; it
is a runtime service. The extension follows the pattern the Botler
already practices: alongside capability_call and
log, the controlled handle the Botler delivers on each
invocation exposes a third control point —
cognition_call —, the only path by which
the Agentlet’s body reaches a model.
The governance consequence is the entire argument: because all of the Agentlet’s inference passes through the handle, Trust Infrastructure sees it whole. Every model call is metered (tokens, latency), budgeted (against the limit the spec declares), validated (the Pillar 3 mechanisms — hallucination detection, DLP, tokenization — apply at the control point) and audited (in the same append-only log, under the same identity, under the same governance as the rest of the AgencyDomain). A parallel runtime for Agentlets would have to duplicate all of that machinery — a second sandbox, a second handle scheme, a second escalation chain, a second presence in the distributed Layer 3 — only to end up delivering the same guarantees. The Botler’s flat architecture already delivers them.
The legitimate concern that might push toward a separate runtime — the resource profile: model latency, per-token cost, eventual hardware acceleration — is a deployment matter, and the canon already holds the door open: Botler subtypes are distinguished by topology and deployment role, never by domain. A segregated execution pool for inference-heavy Lets is exactly a deployment-role distinction: one conceptual Botler, N processes if the operation calls for it.
It is worth making explicit the two relations that sustain the Lets, because they operate on different floors and both cover both species equally:
| Relation | Who exercises it | Over Botlets | Over Agentlets |
|---|---|---|---|
| Hosting / execution — runtime without agency: lifecycle, isolation, controlled handle, log | The Botler | Yes | Yes (same handle, plus cognition_call) |
| Genesis / maintenance — deciding it exists, specializing it, regenerating it, answering for it | The agent (cognition) | Yes | Yes |
The agent is the parent of both species; the Botler is the butler of both. No Let gets a separate house.
Agentlet maturity — stabilization, not convergence
The Botlet’s junior → senior trajectory converges because each regeneration crystallizes variants into code: the senior is deterministic and that is why its only failures are exogenous. The Agentlet does not walk that trajectory — its correctness is statistical by nature and no amount of operation makes it deterministic. Pretending that an Agentlet “matures to senior” in the Botlet’s sense is a category error with operational consequences: it can never be promised the offline reliability of the senior Botlet on the same basis.
The spec defines for the Agentlet a maturity semantics of its own, observable in the same append-only log that already tracks Botlets:
- Spec stabilization — the charter, the operating
prompt and the configuration stop changing between revisions;
specializeedits grow sparse. - Decreasing escalation rate — the fraction of
executions the Agentlet resolves within its charter without escalating
to full Cognition grows and stabilizes. It is the functional analogue of
95/4/1: the proportion between bounded judgment that suffices and full judgment that rescues. - Sustained quality under the declarative contract — its declared quality attributes (freshness, SLA, degradation) hold within threshold over a sustained period.
The Agentlet’s offline behavior demands explicit declaration, not inheritance from its sibling. A senior Botlet operates offline because it needs no model at all; an Agentlet operates offline only if its model resides on the edge. The spec of every conformant Agentlet MUST declare the locality of its bounded cognition — cloud-resident, edge-resident or hybrid, with the same vocabulary the spec already uses for Connectors — and its behavior without a network. Without that declaration, the “trivially explainable offline mode” consequence of the parallel topology breaks silently: the site that counted on its Autonomy Path discovers, with the network down, that half of its units needed a model on the other end of the wire.
proto-Agentlet — the pre-forged piece of judgment
Like its sibling, the Agentlet rarely springs from nothing: it springs from a proto-Agentlet — the pre-forged piece the agent configures in its Engineering time to instantiate an Agentlet specific to the case. The proto-Agentlet contains the body (the scaffolding of the interpretive task: the charter’s structure, the skeleton of the operating prompt, the input and output contracts, the escalation thresholds); the Agentlet is the configured instance. The proto-Botlet’s two classes apply unchanged: a tempered proto-Agentlet resolves one interpretive function and is configured through bounded parametrization (an operational email classifier, an invoice field extractor); a platform proto-Agentlet is a generic judgment engine whose specialization lives in compositional configuration and covers N functions of its domain.
The derivation chain extends without friction: documented use cases require Lets — zero, one or several, of either species —, and each Let is an instance of some proto in the catalog. Every conformant Agentlet MUST be traceable in that chain, and the append-only log MUST record the proto-Agentlet of origin of each instance. The common catalogs — public and open at AgencyDomains.org, proprietary codices, private contracts, sovereign agreements — accumulate proto-Agentlets with the same network effects with which they accumulate proto-Botlets: implementer n+1 receives charters, operating prompts and thresholds refined by implementers 1 through n.
The generations
(G1/G2/G3) apply with a natural
reading: in G1 the agent configures the proto-Agentlet —
fills in the charter, adjusts the operating prompt within the
scaffolding, sets thresholds — without writing its body. The
G1/G2 edge is the same as the Botlet’s:
configuration that a well-defined Capability evaluates is
G1; extension of the proto’s internal logic is
G2.
The economics of the three rungs
With the Agentlet, the agentive system’s economic ladder is complete. Chapter 4 presented two paths — costly Cognition, cheap Autonomy —; the fine-grained view distinguishes three rungs of per-execution cost:
| Rung | Unit | Inference | Marginal cost |
|---|---|---|---|
| 1 | Botlet | Zero | ~0 — traditional compute |
| 2 | Agentlet | Bounded: sized model, declared budget | Low and budgetable per Let |
| 3 | Cognition | Full: deliberative, frontier model, complete tree | High — reserved for the new |
The middle rung is the one that was missing. Without it, every recurrent interpretive task paid rung-3 prices — or was forced, fragile, onto rung 1. With it, the organization assigns each pattern to its natural cost, and the mature system migrates work down the ladder: Cognition cedes interpretive routines to Agentlets; Agentlets cede crystallizable cores to Botlets.
The Agentlet’s arrival qualifies, but does not break, the economic promise of the Autonomy Path. The path remains the cheap one — but it stops being uniformly free: it contains Lets of ~0 marginal cost and Lets of bounded cost, and the mix is declared per Let, not averaged away. Under fixed Subscription plans, the argument of Chapter 5 §2 refines in the same direction: Botlets remain the mechanism that makes sustained autonomy possible without exhausting the quota, and Agentlets consume quota — bounded, budgeted, visible in the log — so their share of the mix is an explicit economic decision of the organization, exactly as the decision of which patterns to consolidate into Botlets is.
There is a second cross-cutting consequence: the Validation
pillar gains a seat in Layer 3. Until this version of the
canon, Validation was exercised in Layer 2 (partial) and Layer 4
(principal), because Layer 3 contained only deterministic code. With
Agentlets, statistical correction enters the muscle-memory zone —
exactly the volatility the Bounded Concerns Architecture (Chapter 3)
teaches to confine —, and the Pillar 3 mechanisms (hallucination
detection, structured-output validation, DLP, tokenization) apply at the
Botler’s cognition_call control point, over every execution
of every Agentlet. The thinness of the domain is preserved: statistical
judgment stays confined to declared, governed, auditable Lets — never
scattered through the runtime.
When to use an Agentlet — and when not?
The decision among the three homes — Botlet, Agentlet, Cognition — resolves with two questions in cascade:
First: is the task recurrent? If not — if it is one-off, exploratory, or its pattern has not yet stabilized —, it belongs to Cognition. The practical ten-invocations rule of §2 applies to both unit species alike.
Second: does each instance demand judgment? If not — if the logic is crystallizable into deterministic code —, Botlet, always: it is the cheapest rung and the only one that matures toward reliable offline operation. If yes — if the pattern is stable but each execution interprets a new instance —, Agentlet.
Three signals confirm that a task is Agentlet territory: the input is natural language or unstructured content (emails, documents, transcripts, free-form descriptions); the output requires classifying, summarizing, extracting or judging rather than computing or transporting; and attempts to solve it with rules produce exception lists that grow without converging. And two anti-signals return the task to its neighbors: if the “judgment” turned out to be a stable decision table, it is a Botlet not yet crystallized; if the charter cannot be declared — the task requires deciding what to do, not merely how —, it is Agent work, with Agent governance.
Conformance
An Agentlet implementation conformant with this specification must satisfy:
| Requirement | Level |
|---|---|
| Charter declared in the spec: task, inputs, outputs, limits | MUST |
| Bounded inference declared: model, accessible Capabilities, per-execution budget | MUST |
All inference routed through the cognition_call control
point of the Botler’s handle |
MUST |
| Fallback guarantee: escalation to full Cognition on out-of-charter cases or sub-threshold confidence | MUST |
| Zero inference outside the handle (the smuggling rule, Botlet→Agentlet direction) | MUST |
| Hosting by the generic Botler — no parallel runtime per species | MUST |
| Traceability: every execution and every inference call in the append-only log | MUST |
| Traceable in the use-cases → Lets → protos chain; proto-Agentlet of origin recorded | MUST |
| Declared locality of the bounded cognition (cloud / edge / hybrid) and offline behavior | MUST |
| Pillar 3 Validation applied at the cognition control point | MUST |
| Explicit Agentlet vs Autonomous Agent distinction in API and documentation (the border test) | MUST |
| Maturity metrics of its own: spec stabilization and escalation rate | SHOULD |
| Crystallization: detection of deterministic cores and extraction into Botlets | SHOULD |
| Execution pool segregated by resource profile (deployment role) | MAY |
Evolution frontier
Three active areas of evolution of the Agentlet deserve mention in closing.
Edge models for bounded judgment are the first. The viability of the offline Agentlet depends on small models running at the physical site with sufficient quality for bounded charters. The state of the art advances quickly; the spec already provides the declaration vocabulary (locality of the bounded cognition) so implementations can adopt edge models without a contract change.
Confidence calibration is the second. The Agentlet’s escalation to full Cognition depends on the Agentlet itself estimating when its verdict does not reach the threshold — an open problem of statistical calibration. While it matures, conservative implementations compensate with low thresholds: over-escalating costs tokens; under-escalating costs trust.
Assisted crystallization is the third. The automatic detection of deterministic cores inside Agentlet charters — the Agentlet → Botlet trajectory of the smuggling rule — is today a judgment of cognition in its Preparation time. Its formalization as an inverse Pattern Recognition mechanism (detecting what stopped needing judgment) is open work.
With the Agentlet, the roster of formal constructions of this chapter closes — eight canonical primitives: AgencyDomain, Botlet, proto-Botlet, Agentlet, Capability, Trust Infrastructure, the Assistant vs Autonomous Agent distinction, and the Facet. Whoever has followed Chapters 4 and 5 holds the complete constructive vocabulary with which the agentive category can be reasoned about and built — from the computational space that contains it all to the three-rung ladder by which work finds its natural cost.
Chapter 6 shifts the gaze from the individual system to the market. It allows whoever builds or invests to answer with discipline the question of where each actor — one’s own or someone else’s — competes, and why the same link in the chain can be a hotly contested zone or still-open territory.