Chapter 8 · Trust Infrastructure operationalized — policies and CRUDLEX
Chapter 5 described Trust Infrastructure as a set of five pillars — Governance, Auditing, Validation, Resilience, Transparency — that cuts across the four layers of the Agentive Architecture. The description was conceptual: it named the pillars, their canonical mechanisms, the properties they demand. This chapter closes the loop: it translates those concepts into concrete constructs that an implementer can take and build.
The distinction between concept and operationalization is critical to the success of an agentive system in production. A pillar is conceptual: “the organization must be able to govern what the agent does”. An operationalization is constructive: “the organization configures policies in YAML format that apply the CRUDLEX model, evaluated on every tool invocation, with a declarative catalog and explicit inheritance”. The distance between the two is exactly what separates a project that moves from pilot to production from one that swells the wave of cancellations Gartner forecasts (Chapter 2).
The pillars answer what trust is needed. The operationalizations answer how it is built.
This chapter develops the complete operationalization of Trust Infrastructure. Policy catalog, complete CRUDLEX model, append-only log format, human approval protocols, hallucination-detection rules, tokenization policy. Each component with the detail an architect needs to implement and an auditor needs to evaluate. The chapter is the most technical in the book, and it is so deliberately — operationalized Trust Infrastructure is where the architecture becomes real.
Policy catalog

Policies are declarative rules — not embedded code — that define what an agent may do and under what conditions. The distinction between declarative policy and imperative code matters. A declarative policy can be modified without redeploying the system, can be versioned independently, can be audited without requiring a code review, can be understood by non-technical people (compliance officers, lawyers, auditors). Imperative code entangled with policies confuses three distinct roles — developer, compliance officer, auditor — into a single surface, and that guarantees all three roles operate poorly.
The canonical operationalization defines a catalog with five categories of policies. The five categories are distinct, attack distinct problems, and a well-designed agentive system has active policies in all five. We develop them one by one.
Tool policies
Tool policies define which tools the agent may invoke, over which resources. They are the first control mechanism an agentive system needs: if the agent can invoke tools indiscriminately, no governance is possible. Tool policies establish the permitted scope of the agent’s invocations, with granularity by agent, by tool, by scope (the specific resources the tool operates over), and with special conditions (approval required, categorical prohibition).
policy:
type: tool-access
agent: agent-finance-001
tools:
- name: ledger.read
scope: ["company-A", "company-B"]
allow: true
- name: ledger.write
scope: ["company-A"]
allow: true
require_approval: true # human approval before executing
- name: bank.transfer
allow: false # categorically prohibitedA typical tool policy for a finance agent might permit reads of the ledger over two specific companies, permit writes over only one of them but requiring human approval, and categorically prohibit any bank-transfer operation. The granularity allows a balance between operational autonomy and risk control: the agent operates autonomously for low-impact operations, escalates to a human for medium operations, does not operate for high-impact operations.
Data policies
Data policies define which classes of data the agent may query or emit. They are complementary to tool policies — a tool may be permitted in general, but the specific data it returns may be restricted by class. Data policies classify data by sensitivity and apply distinct rules according to the class.
policy:
type: data-access
agent: agent-customer-support-001
data_classes:
- class: pii.name
allow: read
- class: pii.ssn
allow: read
require_tokenization: true # tokenized before invoking cognition
- class: pii.financial
allow: false
- class: internal.public
allow: read-writeA customer-support agent may read customer names (low-sensitivity PII), may read social security numbers but only tokenized (the cognition sees the token, not the real datum), may not access the customer’s financial data, and may read and write internal public information. Granularity by data class lets the agent operate productively with non-sensitive data without exposing sensitive data to external cognition providers.
Schedule and threshold policies
Schedule and threshold policies limit when, or with which thresholds, the agent acts. They capture the temporal and magnitude dimensions of operations — what time it is, how large the operation is, with what associated risk.
policy:
type: temporal-and-thresholds
agent: agent-trading-001
rules:
- condition: "amount > 100000"
require_approval: true
- condition: "amount > 1000000"
allow: false
- condition: "time NOT IN business_hours"
require_approval: trueA trading agent may operate autonomously for small amounts, requires approval for medium amounts, does not operate for large amounts, and requires approval for any operation outside business hours. The declarative construct allows thresholds to be adjusted without modifying code — a regulatory policy change that moves the approval threshold from one hundred thousand to fifty thousand dollars is executed as a configuration change, not as a software release.
Identity policies
Identity policies define which identities operate on behalf of the agent and how they authenticate. They capture the federated identity model typical of complex organizations, where an agent acts on behalf of a human user, authenticated by the corporate identity provider, with limited scope.
policy:
type: identity
agent: agent-finance-001
authentication:
method: oauth2
issuer: corporate-idp.example.com
delegation:
on_behalf_of: ["user-cfo", "user-controller"]
scope_limited_to: ["agent-finance-001"]The agent authenticates via OAuth2 against the corporate identity provider, operates on behalf of two specific users (CFO and Controller), and its scope is limited to the operations of the finance agent — it cannot act as another agent or assume a different identity. The identity policy is what ensures that the agent’s actions can be traced back to identifiable humans, a necessary condition for serious auditing.
Validation policies
Validation policies define which validations are applied before executing actions. They connect to the mechanisms of Pillar 3 (Validation) that Chapter 5 described, specifying them as concrete policies.
policy:
type: validation
agent: agent-customer-support-001
rules:
- validation: hallucination-check
threshold: 0.95 # minimum confidence
- validation: prompt-injection-check
action_on_detection: block-and-alert
- validation: dlp-scan
data_classes: ["pii.*", "financial.*"]
action_on_detection: tokenizeA customer-support agent requires hallucination validation with a confidence threshold of ninety-five percent — if the detection system detects less confidence, the response is not emitted. It detects prompt-injection attempts and, if it detects one, blocks the operation and alerts the security team. It applies a DLP scan over sensitive data classes — PII and financial data — and, if it detects data that requires tokenization, tokenizes it before the cognition processes it.
Policy composition
Policies compose hierarchically. The organization defines a root policy that applies to all agents; each area defines specific policies that inherit from the root; each team refines further; each agent has a specific policy that inherits from all the preceding ones.
The agent’s policy inherits the restrictions of those above it and can only add restrictions, not remove them. This prevents accidental privilege escalations. If the organization’s root policy prohibits bank transfers greater than one million, the agent’s policy cannot permit them — it can only add further restrictions (for example, prohibit transfers greater than one hundred thousand for the specific agent). Hierarchical composition with downward monotonicity is the structural property that sustains complex governance.
Complete CRUDLEX model
CRUDLEX is the canonical operationalization of granular permissions for agentive systems. The model extends the classic CRUD with two critical operations in agentive systems: List and Execute. The extension is not decoration — it reflects operational distinctions that the traditional CRUD model did not capture but that, in agentive systems, matter.
The six canonical operations are as follows. Create corresponds to creating a new resource — creating a ticket, adding a record. Read corresponds to reading a specific resource — querying a customer by ID. Update corresponds to modifying an existing resource — updating an order’s status. Delete corresponds to removing a resource — deleting a comment. List corresponds to enumerating resources with filters — listing open tickets. Execute corresponds to invoking an operation with a side effect — sending an email, executing a payment, triggering a workflow.
The distinction between Read (reading a specific resource) and List (enumerating resources by filter) is deliberate and critical. An agent may have Read permission over individual customers but not List over the whole base — to prevent it from extracting the complete customer catalog even while having permission to read each one individually. This distinction does not exist in classic CRUD, but in agentive systems it is where mass-exfiltration attacks materialize: an agent with Read but no List is safe; an agent with unrestricted List can dump the entire base with a single query.
The distinction between Update (modify) and Execute (operation with a side effect) is also deliberate. Update modifies a resource; Execute triggers a process that may touch multiple resources or have effects in the real world — sending an email, a bank transfer, executing an external workflow. The two operations have distinct risk profiles: an Update has contained impact; an Execute can have impact that propagates. CRUDLEX treats them distinctly so that policies can be applied with precision.
Applying CRUDLEX
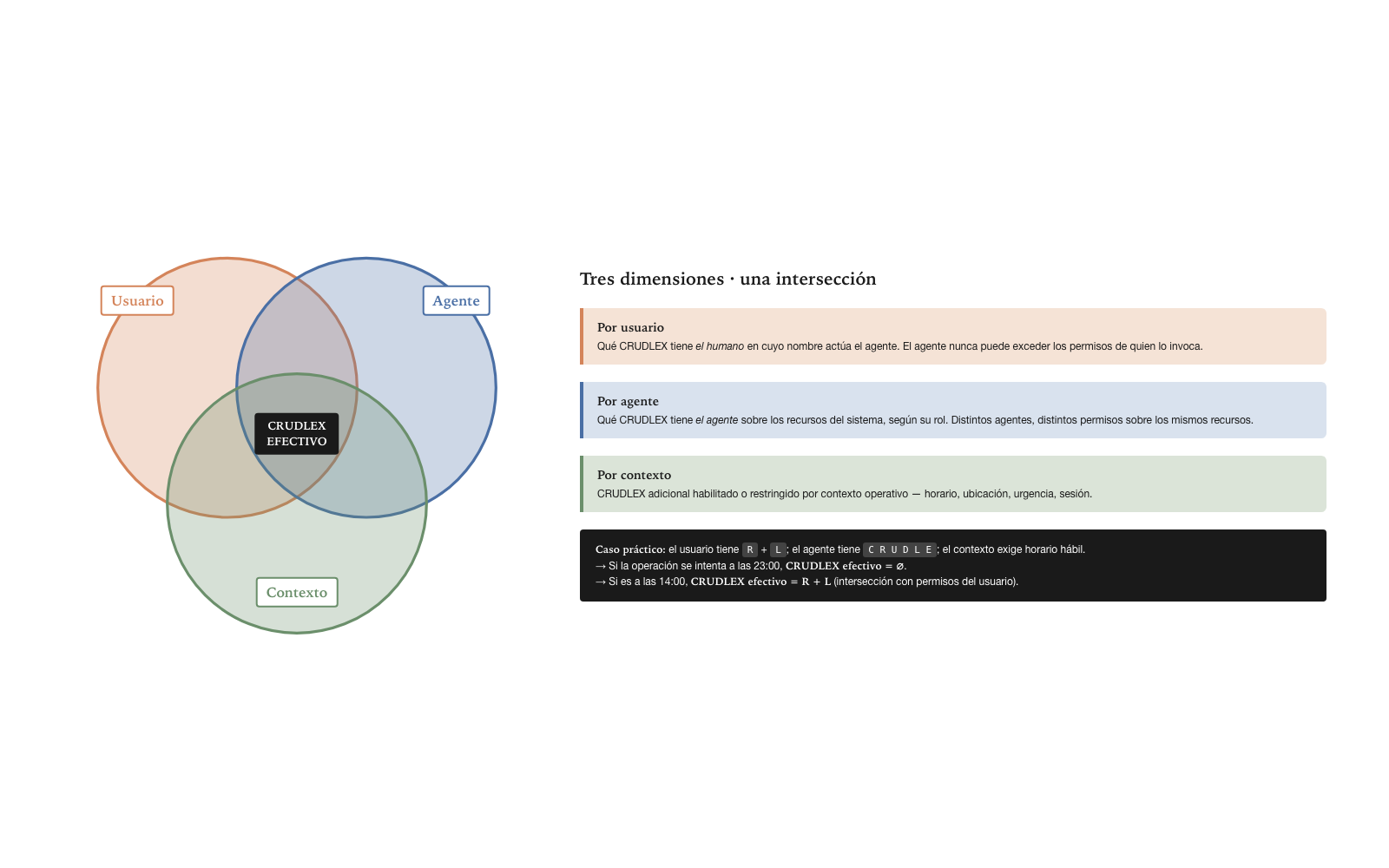
CRUDLEX is applied along three dimensions: user, agent, context. The three dimensions operate independently and compose to produce the effective permission of a particular operation.
The per-user dimension captures which CRUDLEX the human on whose behalf the agent acts holds. If the human user does not have Update over a certain resource, the agent acting on their behalf does not have it either — the agent cannot exceed the permissions of whoever invokes it. The per-agent dimension captures which CRUDLEX the agent holds over the system’s resources. Different agents may hold different permissions over the same resources according to their role. The per-context dimension captures additional CRUDLEX enabled or restricted by operational context — schedule, location, urgency.
The effective CRUDLEX of an operation is the intersection of the three dimensions. If the user has Read but not Write, and the agent has Read+Write, the effective operation is only Read — the agent cannot exceed the scope of the user on whose behalf it acts. The intersection as a composition mechanism is an important property: it guarantees that no dimension can escalate privileges beyond what the other dimensions permit.
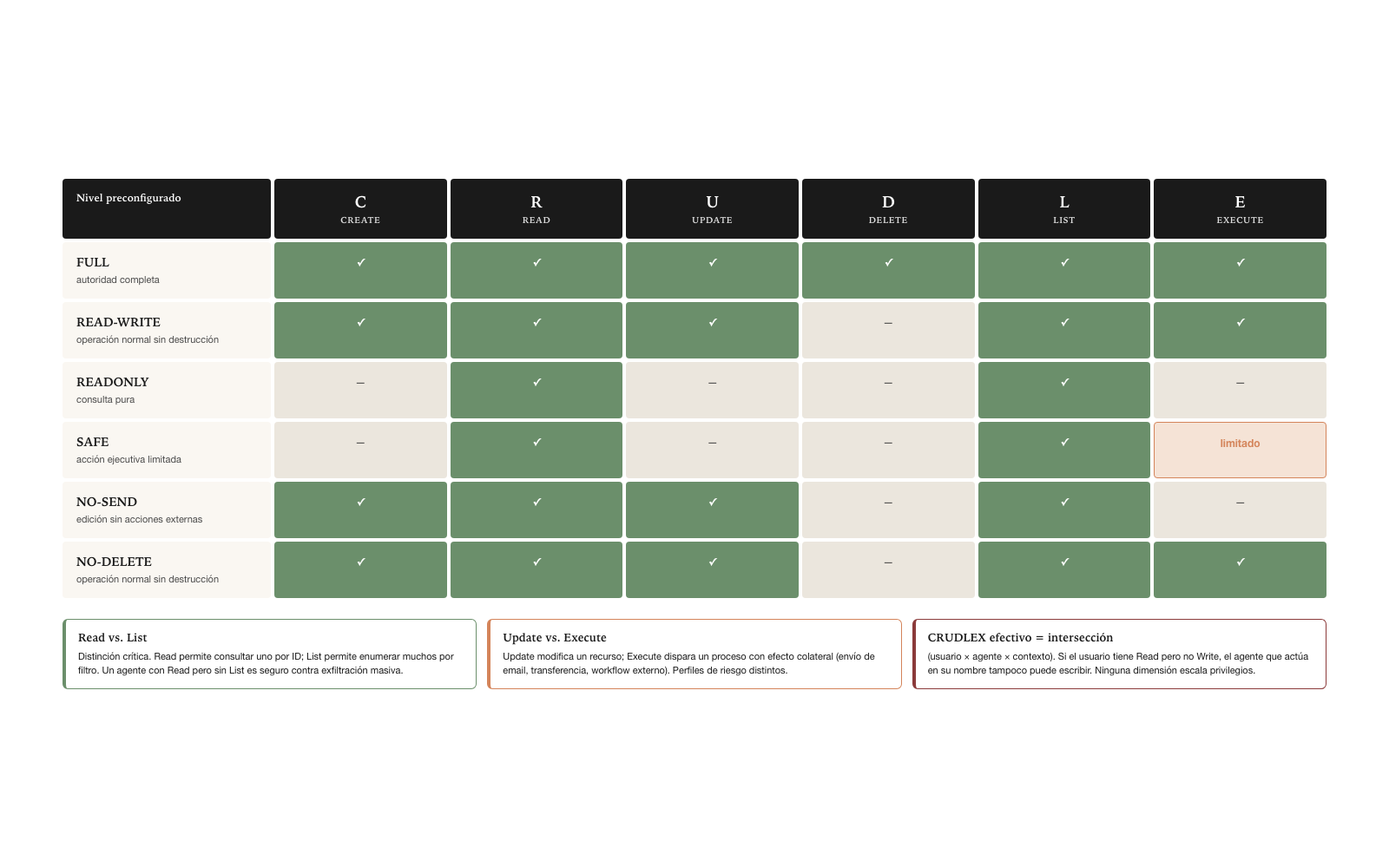
Preconfigured levels
To avoid ad hoc configurations for every case, the canonical specification defines preconfigured levels by convention. The levels cover the common cases; special cases are configured granularly.
| Level | CRUDLEX enabled | Typical use |
|---|---|---|
| FULL | C R U D L E | Agent with complete authority over the system |
| READ-WRITE | C R U D L (no E) | Full data write —including deletion— without triggering external actions |
| READONLY | R L | Pure query |
| SAFE | R L E (with E limited to reversible operations) | Limited executive action |
| NO-SEND | C R U L (no E) | Editing without triggering external actions |
| NO-DELETE | C R U L E (no D) | Normal operation without destruction |
The FULL and READONLY levels are extremes that are almost never used in production — FULL is too permissive, READONLY too restrictive. The intermediate levels — READ-WRITE, SAFE, NO-SEND, NO-DELETE — cover the typical cases. A customer-support agent typically operates in SAFE: it can query, list, execute reversible actions (such as reassigning a ticket), but cannot create or delete irreversibly. An operational back-office agent typically operates in NO-DELETE: it can create, read, update, list, execute — but cannot delete records, because auditing demands preservation.
Append-only log format
The append-only log is the central component of auditing. The canonical specification defines its format and properties in enough detail for an implementer to build a conformant log and an auditor to evaluate whether a particular log is conformant.
Record structure
Each log record contains a defined set of fields:
{
"log_id": "lr-2026-05-02T14:23:45.123Z-7f3a",
"timestamp": "2026-05-02T14:23:45.123Z",
"agent_id": "agent-finance-001",
"trace_id": "tr-2026-05-02-abc123",
"operation": {
"type": "tool_invocation",
"tool": "ledger.write",
"parameters_hash": "sha256:..."
},
"context": {
"user_id": "user-cfo",
"session_id": "sess-2026-05-02-xyz",
"capability_applied": "Finance/Treasury/cashflow-management"
},
"policy_evaluation": {
"policies_applied": ["policy-finance-001", "policy-trade-001"],
"decision": "allow",
"approval": {
"required": true,
"approver": "user-controller",
"approved_at": "2026-05-02T14:23:42.000Z"
}
},
"outcome": {
"status": "success",
"result_hash": "sha256:..."
},
"previous_log_hash": "sha256:..."
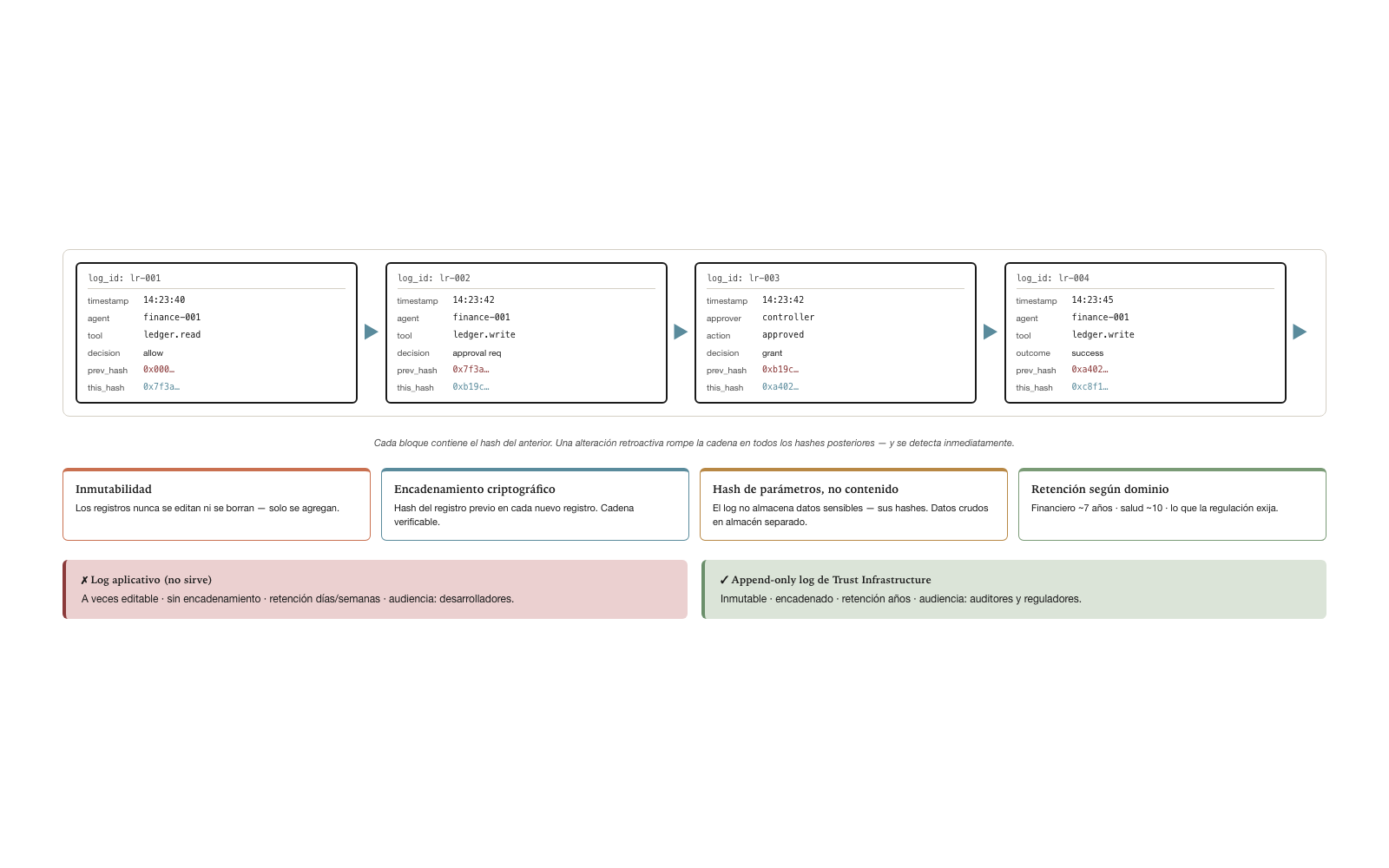
}Each field serves a specific purpose. log_id is the record’s unique identifier. timestamp is the moment of the operation with millisecond precision. agent_id identifies the agent. trace_id correlates with other events of the same trace (other operations that stem from the same original request). operation describes what was done. context captures who requested it, which Capability was applied. policy_evaluation records which policies were evaluated and with what decision, including human approval when it was required. outcome records the result of the operation. previous_log_hash is the hash of the preceding record — forming the cryptographic chain.
Properties demanded
The log must satisfy five non-negotiable properties. Immutability ensures that records are never edited or deleted — only appended. Cryptographic chaining ensures that each record contains the hash of the previous one, forming a verifiable chain; a retroactive alteration would be immediately detectable. Hashing of parameters and results, not content ensures that the log does not store sensitive data (parameters, full results), but their hashes — the raw data live in a separate store with specific retention policies. Configurable minimum retention ensures that the retention policy is defined per domain: finance typically seven years, health typically ten years, whatever the applicable regulation requires. Queryable format ensures that the log is queryable by filters — by agent, by user, by trace, by date range, by operation type.
Difference from application logs
The Trust Infrastructure append-only log is distinct from the application log (which records normal-operation events). The differences are substantive and the two systems should not be confused.
| Dimension | Application log | Trust append-only log |
|---|---|---|
| Purpose | Diagnosis, debug | Auditing, compliance |
| Mutability | Sometimes editable | Never |
| Cryptographic chaining | Rare | Mandatory |
| Retention | Days or weeks | Years (regulatory) |
| Audience | Developers | Auditors, regulators |
A serious organization maintains both and integrates them only where appropriate. The application log serves the operations team to diagnose problems; the Trust append-only log serves the organization to defend itself before audits and regulators. Confusing the two — using the application log for auditing, or adding audit weight to the application log — ends up serving both purposes poorly.
Human approval protocol
When an operation requires human approval before executing, the canonical specification defines the protocol with enough precision for the implementation to be verifiable.
Approval triggers
Three typical triggers activate the human-approval flow. The first is
by explicit policy: the agent’s policy declares
require_approval: true for the operation. It is the
simplest case — the policy is predefined and the system applies it
automatically. The second is by threshold: the
operation exceeds a configured threshold — amount, scope, severity. For
example, a payments agent that operates autonomously for small amounts
may require approval when the amount exceeds one hundred thousand
dollars. The third is by agent uncertainty: the agent
itself declares low confidence in its decision and requests validation.
It is the least common trigger but useful for cases where the agent
recognizes it is outside its comfort zone.
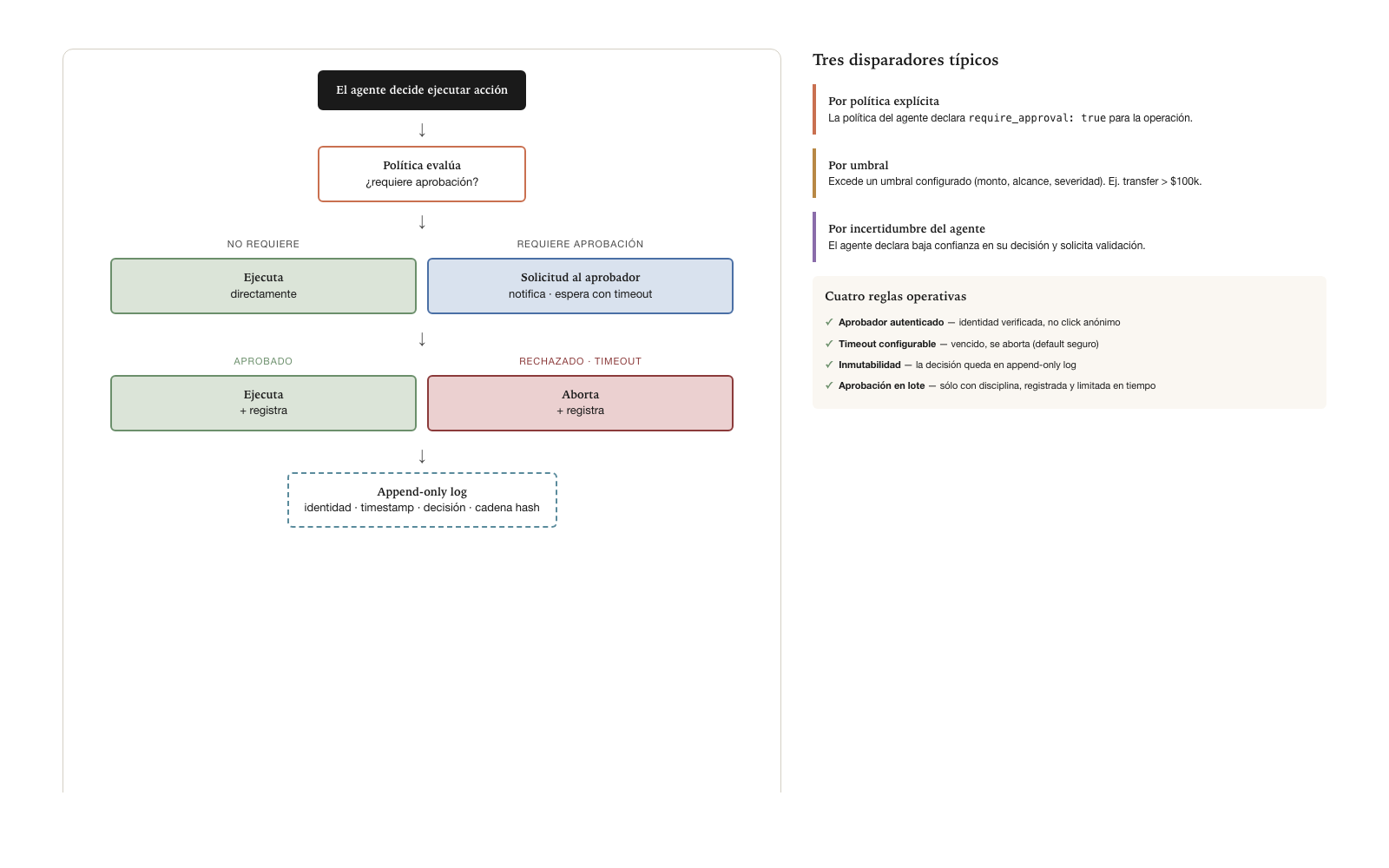
Canonical flow
When a trigger activates the need for approval, the canonical flow is as follows. The agent decides to execute an action. The policy evaluates whether it requires approval. If it does not, the agent executes and records. If it does, the system creates an approval request, notifies the configured approver or approvers, and waits for a response with a timeout. If the response is approval, it executes. If the response is rejection or the timeout expires, it aborts. In every case, it records the whole chain in the append-only log.
Approval rules
The approval has four operational rules that the specification demands.
The first rule: authenticated approver. The approval is tied to the approver’s verified identity, not to an anonymous click. If the approver is Juan Pérez with corporate credentials, the approval is recorded under a verified identity — not as a generic approval by “someone who had access to the system”. Without this rule, the approval loses regulatory value.
The second rule: configurable timeout. Each operation has a timeout for the approval. If it expires without approval, the operation is aborted — a safe default. In special cases (urgent critical operations), automatic escalation to a secondary approver may be configured, but the escalation itself is recorded and must be permitted by policy.
The third rule: immutability of the record. The approver’s decision remains in the append-only log with identity, timestamp and, optionally, a comment. Once recorded, it cannot be modified. This protects both the approver (their decision stays as they made it) and the organization (the chain of approvals is traceable).
The fourth rule: batch approval for repetitive cases. For repetitive, low-risk operations, pattern approval may be configured — “pre-approve all operations of type X for the next 4 hours”. But the pre-approval itself is an operation that is recorded, with the approver’s identity, the pattern’s scope, and its duration. Batch approval is operationally efficient but requires discipline so as not to become a generic approval that empties the model.
Hallucination-detection rules
Response validation — Pillar 3 of Trust Infrastructure — operates with a set of rules that we describe below. Each one attacks a distinct type of agent error.
The self-consistency rule works as follows: the agent formulates the same question in N distinct ways. If the N responses are consistent, confidence increases. If they differ, it alerts. The technique exploits a property of LLM models: when the model is certain, its responses are stable across small variations of the question; when it is hallucinating, the responses are unstable. Self-consistency is relatively cheap and useful for detecting flagrant hallucinations.
The retrieval-augmented verification rule works as follows: before asserting a fact, the agent searches for evidence in its corpus of trusted data. If it finds consistent evidence, it asserts with high confidence. If it finds no evidence, it responds with explicit uncertainty or abstains. This technique requires that the organization maintain a corpus of trusted data — curated knowledge bases, not unverified internet data.
The model-as-judge rule works as follows: a second model, ideally distinct from the first, evaluates the agent’s response and emits a quality score. If the score is below threshold, it alerts or re-asks. The technique is costly (it doubles the inference) but useful for critical cases where the cost of the error exceeds the cost of the validation.
The constraint validation rule works as follows: structured responses — JSON, tables, numbers — are validated against an explicit schema. If they do not comply, they are reformulated or escalated. This technique is practically free and should always be active for structured responses — not using it is waste.
The domain-specific guardrails rule works as follows: domain-specific rules operate as additional verification. In finance, validating that figures reconcile in control totals. In health, validating that diagnoses reference recognized clinical guidelines. In legal, validating that citations to laws exist. These rules are domain-specific and demand investment from the domain experts to build them.
The five rules are applied selectively according to context and cost. Not all are activated on every operation — they are activated according to the criticality of the decision. An agent answering casual questions about the weather does not need all five; an agent making investment decisions needs them all and possibly more.
Tokenization policy
Tokenization replaces sensitive data with tokens before they reach the cognition model. It is a critical mechanism when the organization handles sensitive data that cannot be exposed to the external cognition provider, but that the agent needs to be able to reason over in order to deliver value.
Typically tokenized data
Four categories of data typically require tokenization. PII (Personally Identifiable Information) — names, addresses, phone numbers, emails — for privacy and compliance reasons. Financial data — account numbers, credit cards, balances — for financial regulation. Health data — medical identifiers, diagnoses, conditions — for HIPAA and equivalents. Corporate secrets — API keys, passwords, classified data — for operational security.
Mechanism
The canonical mechanism operates as follows. The original datum arrives at the tokenization service, which returns an opaque token that replaces the datum. The service maintains an internal mapping between the token and the original datum, in a store with reinforced security. The opaque token is what the cognition receives — the model reasons over the token without knowing what it represents. When the agent makes a decision and emits a result, the result may contain the token; the result passes back through the tokenization service, which de-tokenizes only where required — for example, in the final delivery to the authorized human user or in the invocation of a tool that requires the real datum.
- The original datum arrives at the tokenization service.
- The service returns an opaque token and maintains the token↔︎datum mapping in a store with reinforced security.
- The cognition reasons over the token, without knowing what it represents.
- The agent emits its decision, which may contain the token.
- The result returns to the tokenization service, which de-tokenizes only where required — the final delivery to the authorized human or the invocation of a tool that needs the real datum.
The model never sees the original datum. De-tokenization occurs only at the point where the real datum is necessary.
Operational rules
Three operational rules demand discipline in implementation. The first: tokenization before external cognition. If the agent uses a third-party cognition provider — Claude, GPT, Gemini —, the sensitive data are tokenized before leaving the corporate perimeter. Without this rule, the data are exposed to the provider even if the organization wished to avoid it. The second: audited de-tokenization. Each de-tokenization is recorded in the append-only log. It allows reconstructing, afterward, where the original datum was exposed. The third: mapping in a separate store. The token-to-original-datum mapping lives in a store with reinforced security — typically an HSM (Hardware Security Module) or a dedicated tokenization service. Keeping the mapping in the same database as the operational data empties the tokenization guarantee.
Minimum viable catalog
An organization operating agents in production must have, as a minimum viable baseline, the following components operationalized. Below this minimum, operating agents leaves the organization exposed. Above it, there is progressive refinement according to the domain’s maturity and regulatory demands. Note that this catalog deliberately hardens some of the spec’s SHOULDs (Chapter 5 §4) into an operational floor — hallucination detection among them: what the spec leaves optional for minimal implementations, enterprise operation demands.
| Component | Minimum viable |
|---|---|
| Policy catalog | At least tool, data, schedule, identity, validation policies |
| CRUDLEX | Applied on all Layer 4 tools, with preconfigured levels |
| Append-only log | Immutable, chained, retention per domain |
| Human approval | Configurable per operation, with timeout and record |
| Hallucination detection | At least self-consistency + domain guardrails, plus constraint validation always active on structured responses |
| Tokenization | For PII and financial data if applicable |
| Agent inventory | Who operates, which Capabilities, which tools, who approved |
| Governance dashboard | Visualization of the inventory + operational metrics |
What is critical about this catalog is not the list itself — it is that it is built with the same discipline with which any serious organization builds its financial control system or its security system. Trust Infrastructure is not a byproduct of having agentive AI. It is specific discipline that the organization adopts when it decides to operate agents in production.
The tripartite deployment pattern — Cloud + Client + Local

Operationalizing Trust Infrastructure in an enterprise organization is not a purely technical exercise — it is an exercise in the separation of responsibilities among three planes that operate in physically distinct places. The pattern this operationalization adopts as canonical to solve this problem is the tripartite deployment: three coordinated components that live in three places with three differentiated functional roles.
The first component is the Cloud — the plane operated by the provider of the agentive infrastructure. Its role is control plane: license management, registry of available providers, integration with upstream cognition providers, aggregated telemetry with privacy preserved. It is where the provider keeps the platform alive and resolves the problems that require cross-client visibility — incidents that affect multiple tenants, updates to the canonical policy catalog, aggregated health monitoring of the system. The end client does not operate this component; it consumes it.
The second component is the Client — the plane deployed inside the client organization’s internal network. Its role is governance plane: definition and enforcement of corporate policies, integration with the client’s identity provider, central auditing of all the agent’s actions, connections to the internal systems the agent must access. This is where enterprise governance is exercised — because governance lives where the organization has direct control, not where an external provider promises it. The Client component is what allows the organization to exercise Trust Infrastructure on its own terms.
The third component is the Local — the plane deployed on each user’s device. Its role is execution plane: the app that connects the user’s agent (Claude Code, Cursor, Windsurf, any MCP client) with the Client component and with the local providers. This is where the operation actually occurs — where the user’s agent invokes tools, where the user’s credentials live encrypted locally, where the operation’s latency materializes.
The reason this pattern is structural and not arbitrary is that each of the three planes resolves a problem the other two cannot resolve well. The Cloud cannot exercise corporate governance because it does not live inside the company’s perimeter. The Client cannot keep the platform alive on its own because each company would replicate the common work. The Local cannot make governance decisions because it is under the individual user’s control, not the organization’s. The three planes cooperate, but none substitutes for the others.
Policy is defined where the company controls. The AI operates where the user works. The ecosystem is maintained where the provider can operate it.
This pattern is replicable by any actor operating enterprise agentive infrastructure. The spec demands that the three planes be clearly separated — mixing responsibilities among them produces systems the client cannot govern (when governance lives in the provider’s cloud) or that the provider cannot operate (when everything lives in the client’s network). The separation is the fundamental property.
The economics of operationalized Trust Infrastructure
Implementing Trust Infrastructure has a cost. It is worth being explicit about the cost because the decision to invest or not invest directly affects the viability of the agentive system in production.
The cost has three components. The initial construction is one-time: policy catalog, CRUDLEX model, append-only log with cryptographic chaining, validation mechanisms, integration with tokenization services. It is several months of work for a medium-sized organization. The operational maintenance is continuous: adding new policies as the system evolves, monitoring that the existing ones remain valid, adjusting thresholds according to learning, keeping the inventory up to date. It is continuous work for a dedicated team. The operating overhead is per operation: latency and compute to validate before acting, record afterward, evaluate policies on every invocation. It is a percentage on top of the normal operating cost — typically five to twenty percent depending on implementation.
The cost is real, but it is less than the cost of not having Trust Infrastructure. The Gartner cancellation projection that Chapter 2 documents hangs over this entire chapter — inadequate risk controls are its third cause — and the same chapter records the scale of risky behaviors organizations report from their agents. The cost of a cancelled project or of an incident — a data leak, an incorrect high-impact decision, a regulatory failure — is typically far greater than the cost of preventing it.
Trust Infrastructure is not an expense. It is insurance against the asymmetric cost of its absence.
The asymmetry of the cost is what justifies the investment. Implementing Trust Infrastructure costs a relatively predictable amount. Not implementing it exposes the organization to potentially catastrophic costs whose magnitude it cannot bound in advance. The balance, when calculated with discipline, favors the investment.
Operational continuity — operationalizing the second mechanism
Chapter 5 §4 formalizes the distinction between the two complementary continuity mechanisms — agentic fallback and operational business continuity — and it is assumed here as given. The first is already covered operationally by the spec of the Lets (Ch 5 §2 and §7) and the no-stop guarantee of the layer (Ch 4). The second needs its own operationalization — the section that follows delivers it.
Continuity protocol per physical site
Each operational physical site of an AgencyDomain with distributed Layer 3 must have a documented continuity protocol. The spec defines the document’s minimum content. Without that content, the site is not operable under the spec in continuity scenarios — not because the architecture fails, but because the human operation has no guidance when the computational components fall.
The minimum content comprises five elements:
- Operator role in continuity mode — who does what when the system falls. The definition must be nominal by position, not by person. “The cashier switches to continuity mode and records sales in the foliated backup notebook. The store supervisor validates each shift closed in continuity mode.”
- Physical backup records — pre-foliated notebooks, numbered receipt books, order tickets, official regulator forms when applicable. Each physical record is the temporary source of truth for the duration of the continuity; when the network returns, its content is entered into the system.
- Activation thresholds — at what duration of inactivity the site switches to continuity mode. Canonical recommendation: ten minutes for hospitality and retail, thirty seconds for card charges with online authorization, immediate for the issuance of a regulated receipt. The thresholds are the site’s policy, adjustable.
- Return procedure — how the physical records are entered retroactively into the system when the network returns. It must make explicit who enters them, in what order, how conflicts are reconciled with events that may have been partially processed before the cut.
- Drill frequency — how often the protocol is exercised. Canonical recommendation: quarterly with a scheduled network cut and a minimum duration of fifteen minutes. Without drills, the protocol exists only on paper and fails when it is seriously needed.
AgencyDomain degradation modes
An operation in production does not always operate in normal mode. The spec formalizes the four canonical degradation modes according to the failure scenario, and the organization must be able to identify at every moment which mode each site operates in. This identification is what allows operational expectations to be governed.
| Mode | Condition | Who sustains the operation? |
|---|---|---|
| Normal | All components active: cognition, central, edge, corporate network. | Full parallel topology. The operation chooses the Cognition Path or the Autonomy Path according to the pattern. |
| Cognition down | Layer 2 unreachable; central and edge active. | The Autonomy Path sustains it. Senior Botlets execute; junior and learning Botlets degrade to their last functional version. The cognition rescues failures when it returns. |
| Edge offline | Edge Botler with no connection to the central; cognition unreachable; physical site isolated. | Senior Botlets against the local DB + edge-resident Connectors. The event queue toward the central accumulates; when the network returns, it drains and reconciles. |
| Total operational continuity | Cognition + edge down due to an exogenous cause (power outage, destroyed hardware, catastrophically lost network). | The site’s manual protocol. The physical record is the temporary source of truth; retroactive entry into the system is the reconciliation. |
The transition between modes is automatic up to
Edge offline — the system detects the failure and
degrades on its own. The transition to Total operational
continuity is governed by the site’s protocol
— a human activates it explicitly when they recognize that no
computational component is operating. This difference matters: the first
three modes are the architecture’s responsibility; the fourth is the
client’s responsibility, executed by its operators.
Traceability of the transition to continuity mode
The append-only log must record the transitions between modes so that subsequent auditing can reconstruct what sustained the operation at each moment. The spec defines the canonical marks:
- Start of operational continuity — when the site
activates the manual protocol, it emits (when the network returns,
retroactively) a
mode-change: continuity-operationalevent with the timestamp of the cut and the estimated duration. - Physical records entered retroactively — each
transaction entered from a physical record carries the tag
provenance: manual-continuityandoriginal-timestamp: <physical time>distinct fromsystem-timestamp: <time of entry>. The distinction lets reports and reconciliations distinguish physical events from digital events. - Edge queue reconciliation — when an edge Botler
drains its queue toward the central after the network returns, the
events carry the tag
provenance: edge-queue-replaywith the site’s original timestamp. - Auditable distinction between agentic fallback and
operational continuity — the log distinguishes
agentic-fallbackevents (the cognition rescued the Let — executing on behalf of the Botlet or receiving the Agentlet’s escalation) fromoperational-continuityevents (a human sustained the operation). Subsequent auditing can separate the two cases without ambiguity. This distinction is what the organization presents when a regulator asks how it operated during an incident.
Operational properties demanded
| Property | Level |
|---|---|
| Explicit distinction in product documentation | MUST |
| Documented continuity protocol per physical site | MUST |
| Documented drills at a minimum quarterly frequency | SHOULD |
| Four degradation modes recognizable by the organization | MUST |
| Traceability of the transition to continuity mode in the append-only log | MUST |
| Auditable distinction between agentic fallback and operational continuity | MUST |
| Retroactive reconciliation of physical records into the system | MUST |
The complete operationalization of the second mechanism closes the loop opened in Ch 5 §4. The distinction between agentic fallback and operational continuity is no longer merely conceptual — it has a field protocol, canonical operation modes, and auditable traceability.
What comes next
With the operational block closed, the book closes with the reference implementation — Chapter 9 — and its epilogue. Anyone who has read the preceding chapters with the sense that each one leaves open questions will find there the explicit confirmation that this reading is correct: what follows is not a closure but the recognition that this specification is a formalized point of departure, not a final destination.