Capítulo 8 · Trust Infrastructure operacionalizada — políticas y CRUDLEX
El Capítulo 5 describió Trust Infrastructure como conjunto de cinco pilares — Gobernanza, Auditoría, Validación, Resiliencia, Transparencia — que atraviesa las cuatro capas de la Arquitectura Agentiva. La descripción era conceptual: nombró los pilares, sus mecanismos canónicos, sus propiedades exigidas. Este capítulo cierra el círculo: traduce esos conceptos en construcciones concretas que un implementador puede tomar y construir.
La distinción entre concepto y operacionalización es crítica para el éxito de un sistema agentivo en producción. Un pilar es conceptual: “la organización debe poder gobernar lo que el agente hace”. Una operacionalización es constructiva: “la organización configura políticas en formato YAML que aplican modelo CRUDLEX, evaluadas en cada invocación de tool, con catálogo declarativo y herencia explícita”. La distancia entre las dos es exactamente lo que separa un proyecto que pasa de piloto a producción del que engrosa la ola de cancelaciones que Gartner pronostica (Capítulo 2).
Los pilares responden qué confianza se necesita. Las operacionalizaciones responden cómo se construye.
Este capítulo desarrolla la operacionalización completa de Trust Infrastructure. Catálogo de políticas, modelo CRUDLEX completo, formato del append-only log, protocolos de aprobación humana, reglas de detección de alucinaciones, política de tokenización. Cada componente con el detalle que un arquitecto necesita para implementar y un auditor necesita para evaluar. El capítulo es el más técnico del libro, y lo es deliberadamente — la Trust Infrastructure operacionalizada es donde la arquitectura se vuelve real.
Catálogo de políticas

Las políticas son reglas declarativas — no código embebido — que definen qué puede hacer un agente y bajo qué condiciones. La distinción entre política declarativa y código imperativo es importante. Una política declarativa puede modificarse sin redeploy del sistema, puede versionarse independientemente, puede ser auditada sin requerir review de código, puede ser comprendida por personas no-técnicas (compliance officers, lawyers, auditores). Un código imperativo enredado con políticas confunde tres roles distintos — desarrollador, compliance officer, auditor — en una sola superficie, y eso garantiza que los tres roles operen mal.
La operacionalización canónica define un catálogo con cinco categorías de políticas. Las cinco categorías son distintas, atacan problemas distintos, y un sistema agentivo bien diseñado tiene políticas activas en las cinco. Las desarrollamos una por una.
Políticas de tools
Las políticas de tools definen qué tools puede invocar el agente, sobre qué recursos. Son el primer mecanismo de control que un sistema agentivo necesita: si el agente puede invocar tools indiscriminadamente, no hay gobernanza posible. Las políticas de tools establecen el alcance permitido de las invocaciones del agente, con granularidad por agente, por tool, por scope (recursos específicos sobre los cuales el tool opera), y con condiciones especiales (aprobación requerida, prohibición categórica).
policy:
type: tool-access
agent: agent-finance-001
tools:
- name: ledger.read
scope: ["company-A", "company-B"]
allow: true
- name: ledger.write
scope: ["company-A"]
allow: true
require_approval: true # aprobación humana antes de ejecutar
- name: bank.transfer
allow: false # prohibido categóricamenteUna política de tools típica para un agente financiero podría permitir lectura del ledger sobre dos empresas específicas, permitir escritura solo sobre una de ellas pero requiriendo aprobación humana, y prohibir categóricamente cualquier operación de transferencia bancaria. La granularidad permite balance entre autonomía operativa y control de riesgo: el agente opera autónomamente para operaciones de bajo impacto, escala al humano para operaciones medias, no opera para operaciones de alto impacto.
Políticas de datos
Las políticas de datos definen qué clases de datos puede consultar o emitir el agente. Son complementarias a las políticas de tools — un tool puede estar permitido en general pero los datos específicos que devuelve pueden estar restringidos por clase. Las políticas de datos clasifican los datos por sensibilidad y aplican reglas distintas según la clase.
policy:
type: data-access
agent: agent-customer-support-001
data_classes:
- class: pii.name
allow: read
- class: pii.ssn
allow: read
require_tokenization: true # se tokeniza antes de invocar cognición
- class: pii.financial
allow: false
- class: internal.public
allow: read-writeUn agente de customer support puede leer nombres de clientes (PII de baja sensibilidad), puede leer números de seguridad social pero solo tokenizados (la cognición ve el token, no el dato real), no puede acceder a datos financieros del cliente, y puede leer y escribir información interna pública. La granularidad por clase de dato permite que el agente opere productivamente con datos no sensibles sin exponer datos sensibles a los proveedores de cognición externos.
Políticas de horarios y umbrales
Las políticas de horarios y umbrales limitan cuándo o con qué umbrales el agente actúa. Capturan la dimensión temporal y de magnitud de las operaciones — qué hora es, cuán grande es la operación, con qué riesgo asociado.
policy:
type: temporal-and-thresholds
agent: agent-trading-001
rules:
- condition: "amount > 100000"
require_approval: true
- condition: "amount > 1000000"
allow: false
- condition: "time NOT IN business_hours"
require_approval: trueUn agente de trading puede operar autónomamente para montos pequeños, requiere aprobación para montos medianos, no opera para montos grandes, y requiere aprobación para cualquier operación fuera de horario hábil. La construcción declarativa permite ajustar los umbrales sin modificar código — un cambio de política regulatoria que mueve el umbral de aprobación de cien mil a cincuenta mil dólares se ejecuta como cambio de configuración, no como release de software.
Políticas de identidad
Las políticas de identidad definen qué identidades operan en nombre del agente y cómo se autentican. Capturan el modelo de identidad federada típico de organizaciones complejas, donde un agente actúa en nombre de un usuario humano, autenticado por el identity provider corporativo, con scope limitado.
policy:
type: identity
agent: agent-finance-001
authentication:
method: oauth2
issuer: corporate-idp.example.com
delegation:
on_behalf_of: ["user-cfo", "user-controller"]
scope_limited_to: ["agent-finance-001"]El agente se autentica vía OAuth2 contra el identity provider corporativo, opera en nombre de dos usuarios específicos (CFO y Controller), y su scope está limitado a las operaciones del agente financiero — no puede actuar como otro agente o asumir identidad distinta. La política de identidad es lo que asegura que las acciones del agente puedan rastrearse de regreso a humanos identificables, condición necesaria para auditoría seria.
Políticas de validación
Las políticas de validación definen qué validaciones se aplican antes de ejecutar acciones. Conectan con los mecanismos del Pilar 3 (Validación) que el Capítulo 5 describió, especificándolos en políticas concretas.
policy:
type: validation
agent: agent-customer-support-001
rules:
- validation: hallucination-check
threshold: 0.95 # confianza mínima
- validation: prompt-injection-check
action_on_detection: block-and-alert
- validation: dlp-scan
data_classes: ["pii.*", "financial.*"]
action_on_detection: tokenizeUn agente de customer support requiere validación de alucinaciones con umbral de confianza del noventa y cinco por ciento — si el sistema de detección detecta menos confianza, la respuesta no se emite. Detecta intentos de prompt injection y, si detecta uno, bloquea la operación y alerta al equipo de seguridad. Aplica DLP scan sobre clases de datos sensibles — PII y datos financieros — y, si detecta datos que requieren tokenización, los tokeniza antes de que la cognición los procese.
Composición de políticas
Las políticas se componen jerárquicamente. La organización define una política raíz que aplica a todos los agentes; cada área define políticas específicas que heredan de la raíz; cada equipo refina aún más; cada agente tiene política específica que hereda de todas las anteriores.
La política del agente hereda las restricciones de las superiores y solo puede agregar restricciones, no removerlas. Esto previene escalamientos accidentales de privilegios. Si la política raíz de la organización prohíbe transferencias bancarias mayores a un millón, la política del agente no puede permitirlas — solo puede agregar restricciones adicionales (por ejemplo, prohibir transferencias mayores a cien mil para el agente específico). La composición jerárquica con monotonía descendente es la propiedad estructural que sostiene la gobernanza compleja.
Modelo CRUDLEX completo
CRUDLEX es la operacionalización canónica de permisos granulares para sistemas agentivos. El modelo extiende el clásico CRUD con dos operaciones críticas en sistemas agentivos: List y Execute. La extensión no es decoración — refleja distinciones operativas que el modelo CRUD tradicional no capturaba pero que en sistemas agentivos importan.
Las seis operaciones canónicas son las siguientes. Create corresponde a crear un nuevo recurso — crear un ticket, agregar un registro. Read corresponde a leer un recurso específico — consultar un cliente por ID. Update corresponde a modificar un recurso existente — actualizar el estado de una orden. Delete corresponde a eliminar un recurso — borrar un comentario. List corresponde a enumerar recursos con filtros — listar tickets abiertos. Execute corresponde a invocar una operación con efecto colateral — enviar email, ejecutar pago, disparar workflow.
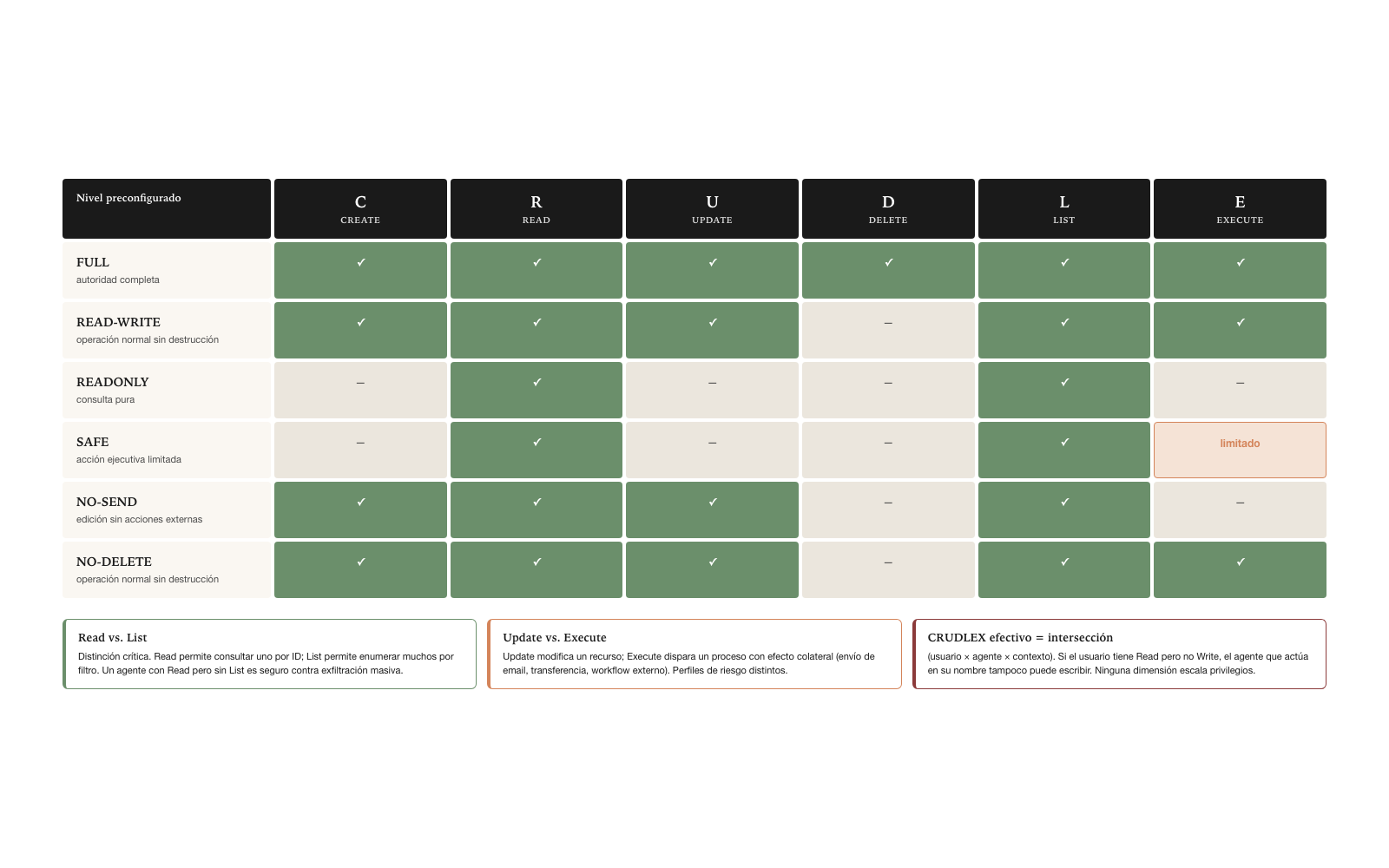
La distinción entre Read (leer un recurso específico) y List (enumerar recursos según filtro) es deliberada y crítica. Un agente puede tener permiso de Read sobre clientes individuales pero no de List sobre toda la base — para evitar que extraiga el catálogo completo de clientes incluso teniendo permiso de leer cada uno individualmente. Esta distinción no existe en CRUD clásico, pero en sistemas agentivos es donde se materializan ataques de exfiltración masiva: un agente con Read sin List es seguro; un agente con List sin restricciones puede dump la base entera con una sola consulta.
La distinción entre Update (modificar) y Execute (operación con efecto colateral) también es deliberada. Update modifica un recurso; Execute dispara un proceso que puede tocar múltiples recursos o tener efectos en el mundo real — envío de email, transferencia bancaria, ejecución de workflow externo. Las dos operaciones tienen perfiles de riesgo distintos: un Update tiene impacto contenido; un Execute puede tener impacto que se propaga. CRUDLEX las trata diferenciadamente para que las políticas puedan aplicarse con precisión.
Aplicación de CRUDLEX
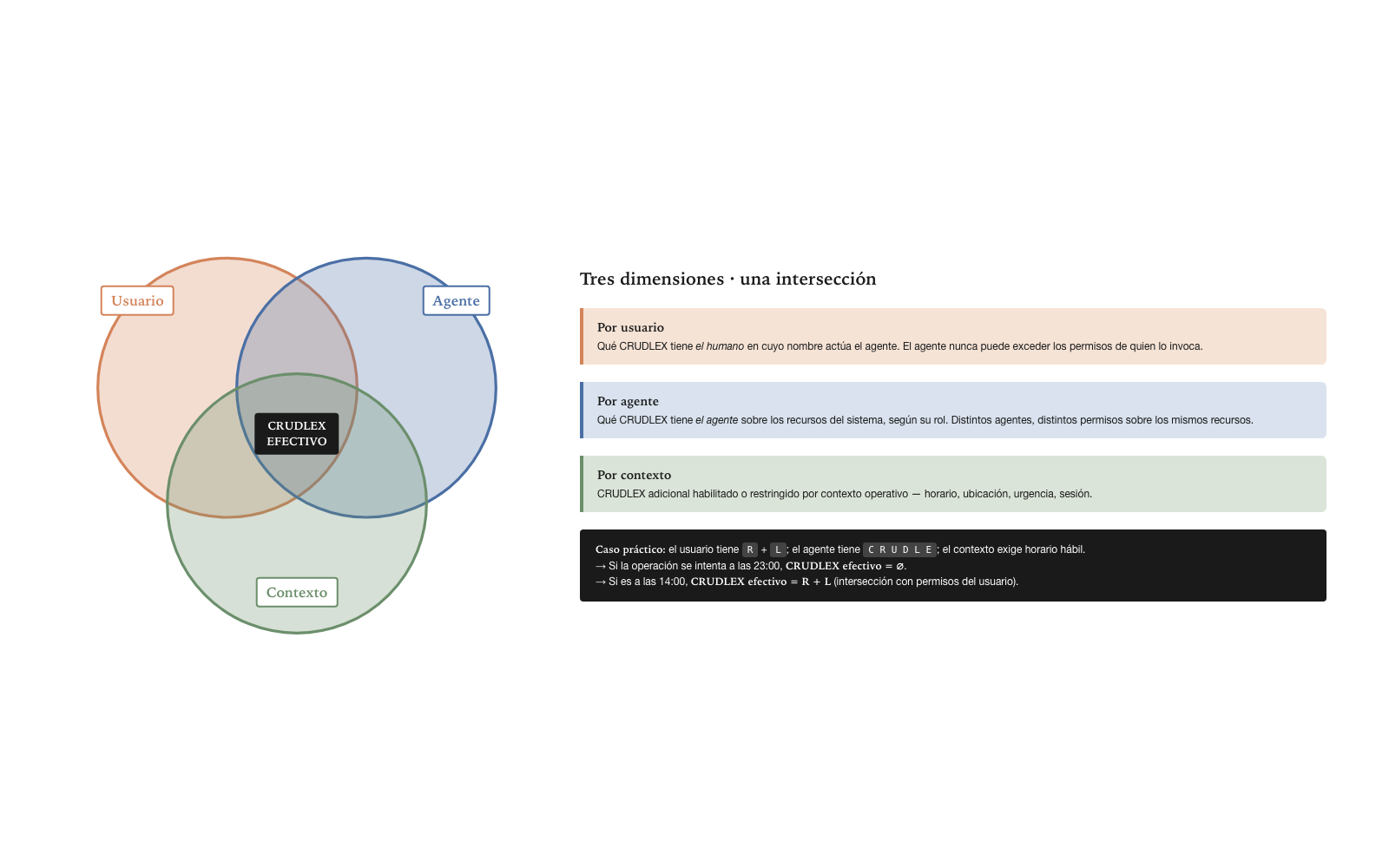
CRUDLEX se aplica por tres dimensiones: usuario, agente, contexto. Las tres dimensiones operan independientemente y se componen para producir el permiso efectivo de una operación particular.
La dimensión por usuario captura qué CRUDLEX tiene el humano en cuyo nombre actúa el agente. Si el usuario humano no tiene Update sobre cierto recurso, el agente que actúa en su nombre tampoco lo tiene — el agente no puede exceder los permisos de quien lo invoca. La dimensión por agente captura qué CRUDLEX tiene el agente sobre los recursos del sistema. Distintos agentes pueden tener distintos permisos sobre los mismos recursos según su rol. La dimensión por contexto captura CRUDLEX adicional habilitado o restringido por contexto operativo — horario, ubicación, urgencia.
El CRUDLEX efectivo de una operación es la intersección de las tres dimensiones. Si el usuario tiene Read pero no Write, y el agente tiene Read+Write, la operación efectiva es solo Read — el agente no puede exceder el alcance del usuario en cuyo nombre actúa. La intersección como mecanismo de composición es propiedad importante: garantiza que ninguna dimensión puede escalar privilegios más allá de lo que las otras dimensiones permiten.
Niveles preconfigurados
Para evitar configuraciones ad hoc para cada caso, la especificación canónica define niveles preconfigurados por convención. Los niveles cubren los casos comunes; casos especiales se configuran granularmente.
| Nivel | CRUDLEX habilitado | Uso típico |
|---|---|---|
| FULL | C R U D L E | Agente con autoridad completa sobre el sistema |
| READ-WRITE | C R U D L (no E) | Escritura total de datos —incluido borrado— sin disparar acciones externas |
| READONLY | R L | Consulta pura |
| SAFE | R L E (con E limitado a operaciones reversibles) | Acción ejecutiva limitada |
| NO-SEND | C R U L (no E) | Edición sin disparar acciones externas |
| NO-DELETE | C R U L E (no D) | Operación normal sin destrucción |
Los niveles FULL y READONLY son extremos que casi nunca se usan en producción — FULL es demasiado permisivo, READONLY es demasiado restrictivo. Los niveles intermedios — READ-WRITE, SAFE, NO-SEND, NO-DELETE — cubren los casos típicos. Un agente de soporte al cliente típicamente opera en SAFE: puede consultar, listar, ejecutar acciones reversibles (como reasignar un ticket), pero no puede crear ni borrar irreversiblemente. Un agente de back-office operativo típicamente opera en NO-DELETE: puede crear, leer, actualizar, listar, ejecutar — pero no puede borrar registros, porque la auditoría exige preservación.
Formato del append-only log
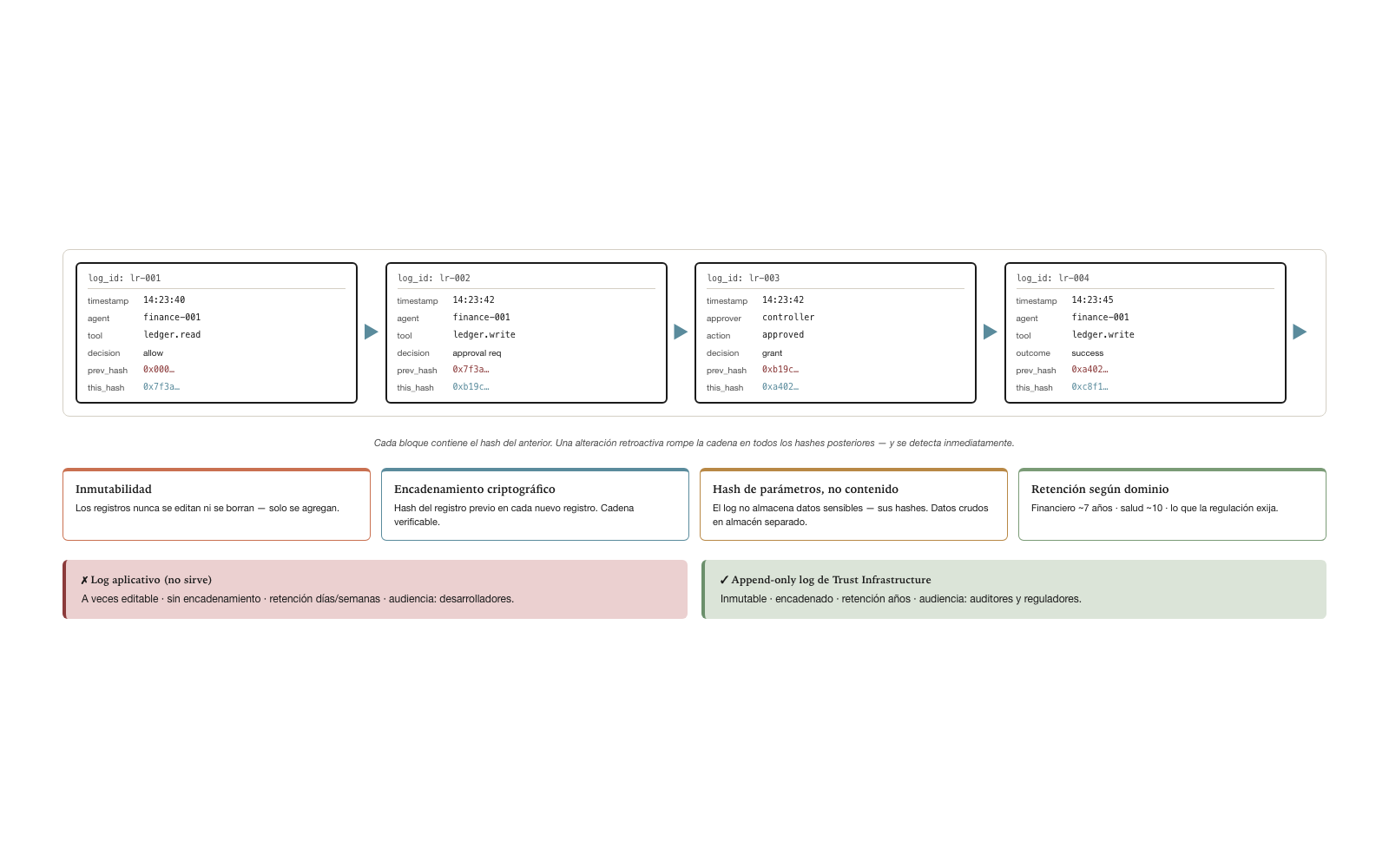
El append-only log es el componente central de la auditoría. La especificación canónica define formato y propiedades con detalle suficiente para que un implementador construya un log conforme y un auditor evalúe si un log particular es conforme.
Estructura del registro
Cada registro del log contiene un conjunto definido de campos:
{
"log_id": "lr-2026-05-02T14:23:45.123Z-7f3a",
"timestamp": "2026-05-02T14:23:45.123Z",
"agent_id": "agent-finance-001",
"trace_id": "tr-2026-05-02-abc123",
"operation": {
"type": "tool_invocation",
"tool": "ledger.write",
"parameters_hash": "sha256:..."
},
"context": {
"user_id": "user-cfo",
"session_id": "sess-2026-05-02-xyz",
"capability_applied": "Finance/Treasury/cashflow-management"
},
"policy_evaluation": {
"policies_applied": ["policy-finance-001", "policy-trade-001"],
"decision": "allow",
"approval": {
"required": true,
"approver": "user-controller",
"approved_at": "2026-05-02T14:23:42.000Z"
}
},
"outcome": {
"status": "success",
"result_hash": "sha256:..."
},
"previous_log_hash": "sha256:..."
}Cada campo cumple un propósito específico. log_id es identificador único del registro. timestamp es momento de la operación con precisión milisegundo. agent_id identifica al agente. trace_id correlaciona con otros eventos del mismo trace (otras operaciones que parten de la misma solicitud original). operation describe qué se hizo. context captura quién pidió, qué Capability se aplicó. policy_evaluation registra qué políticas se evaluaron y con qué decisión, incluyendo aprobación humana cuando se requirió. outcome registra el resultado de la operación. previous_log_hash es el hash del registro anterior — formando la cadena criptográfica.
Propiedades exigidas
El log debe satisfacer cinco propiedades innegociables. La inmutabilidad asegura que registros nunca se editan ni se borran — solo se agregan. El encadenamiento criptográfico asegura que cada registro contiene el hash del anterior, formando una cadena verificable; una alteración retroactiva sería detectable inmediatamente. El hash de parámetros y resultados, no contenido asegura que el log no almacena los datos sensibles (parámetros, resultados completos), sino sus hashes — los datos crudos viven en almacén separado con políticas de retención específicas. La retención mínima configurable asegura que la política de retención se define por dominio: financiero típicamente siete años, salud típicamente diez años, lo que la regulación aplicable exija. El formato consultable asegura que el log es consultable por filtros — por agente, por usuario, por trace, por rango de fechas, por tipo de operación.
Diferencia con logs aplicativos
El append-only log de Trust Infrastructure es distinto del log aplicativo (que registra eventos de operación normal). Las diferencias son sustantivas y los dos sistemas no deben confundirse.
| Dimensión | Log aplicativo | Append-only log de Trust |
|---|---|---|
| Propósito | Diagnóstico, debug | Auditoría, conformidad |
| Mutabilidad | A veces editable | Nunca |
| Encadenamiento criptográfico | Raro | Obligatorio |
| Retención | Días o semanas | Años (regulatorio) |
| Audiencia | Desarrolladores | Auditores, reguladores |
Una organización seria mantiene ambos y los integra solo donde corresponde. El log aplicativo sirve al equipo de operaciones para diagnosticar problemas; el append-only log de Trust sirve a la organización para defenderse ante auditorías y reguladores. Confundir los dos — usar log aplicativo para auditoría, o agregar peso de auditoría al log aplicativo — termina sirviendo mal a ambos propósitos.
Protocolo de aprobación humana
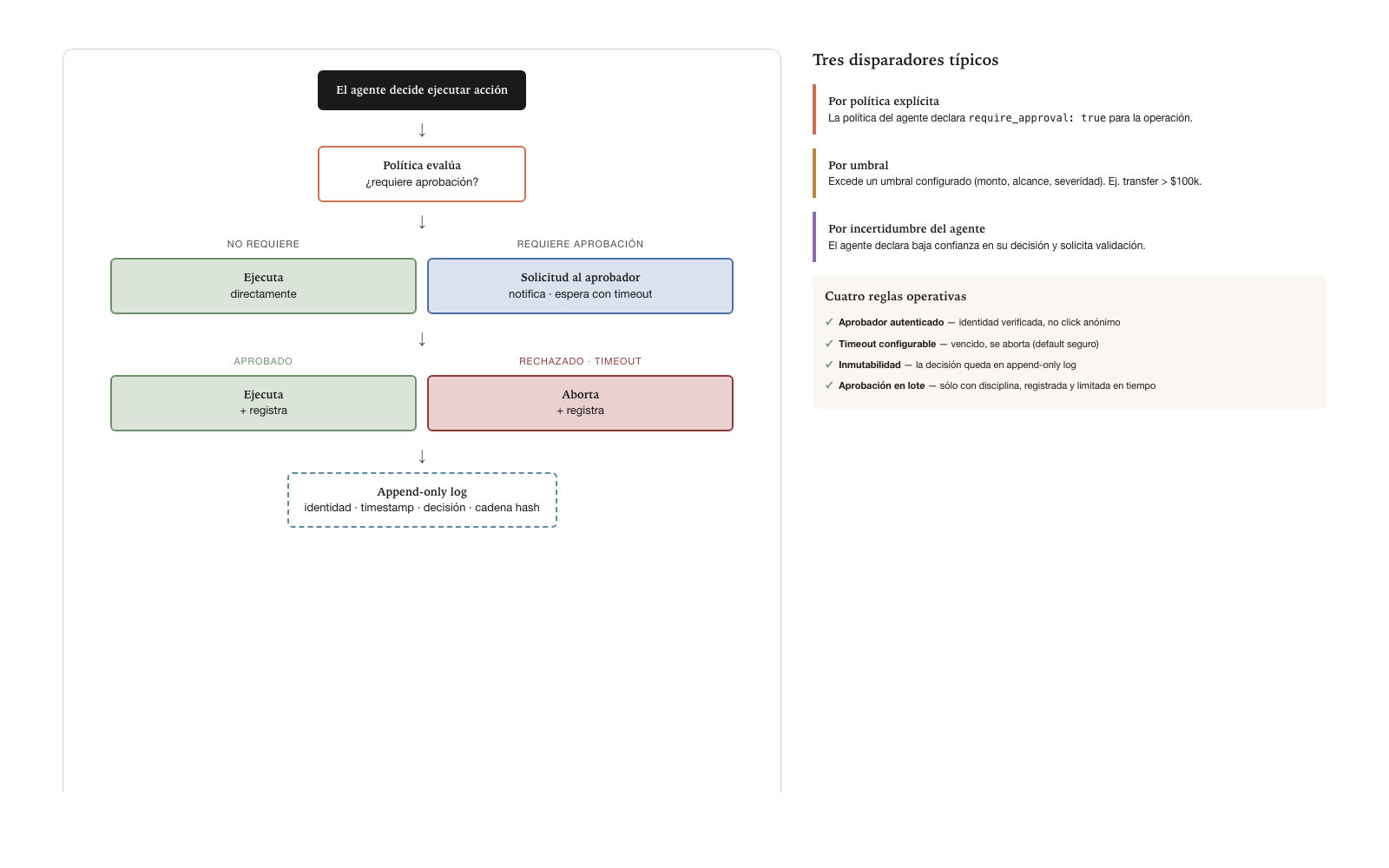
Cuando una operación requiere aprobación humana antes de ejecutarse, la especificación canónica define el protocolo con precisión suficiente para que la implementación sea verificable.
Disparadores de aprobación
Tres disparadores típicos activan el flujo de aprobación humana. El
primero es por política explícita: la política del
agente declara require_approval: true para la operación. Es
el caso más simple — la política está predefinida y el sistema la aplica
automáticamente. El segundo es por umbral: la operación
excede un umbral configurado — monto, alcance, severidad. Por ejemplo,
un agente de pagos que opera autónomamente para montos pequeños puede
requerir aprobación cuando el monto excede los cien mil dólares. El
tercero es por incertidumbre del agente: el agente
mismo declara baja confianza en su decisión y solicita validación. Es
disparador menos común pero útil para casos donde el agente reconoce que
está fuera de su zona de confianza.
Flujo canónico
Cuando un disparador activa la necesidad de aprobación, el flujo canónico es el siguiente. El agente decide ejecutar acción. La política evalúa si requiere aprobación. Si no requiere, el agente ejecuta y registra. Si requiere, el sistema crea solicitud de aprobación, notifica al aprobador o aprobadores configurados, espera respuesta con timeout. Si la respuesta es aprobación, ejecuta. Si la respuesta es rechazo o vence el timeout, aborta. En cualquier caso, registra en el append-only log toda la cadena.
Reglas de la aprobación
La aprobación tiene cuatro reglas operativas que la especificación exige.
La primera regla: aprobador autenticado. La aprobación queda atada a la identidad verificada del aprobador, no a un click anónimo. Si el aprobador es Juan Pérez con credenciales corporativas, la aprobación queda registrada bajo identidad verificada — no como aprobación genérica de “alguien que tenía acceso al sistema”. Sin esta regla, la aprobación pierde valor regulatorio.
La segunda regla: timeout configurable. Cada operación tiene timeout para la aprobación. Si vence sin aprobación, la operación se aborta — default seguro. En casos especiales (operaciones críticas urgentes), puede configurarse escalación automática a un aprobador secundario, pero la escalación misma queda registrada y debe estar permitida por política.
La tercera regla: inmutabilidad del registro. La decisión del aprobador queda en el append-only log con identidad, timestamp y, opcionalmente, comentario. Una vez registrada, no se puede modificar. Esto protege tanto al aprobador (su decisión queda como la tomó) como a la organización (la cadena de aprobaciones es trazable).
La cuarta regla: aprobación en lote para casos repetitivos. Para operaciones repetitivas y de bajo riesgo, puede configurarse aprobación de patrón — “pre-aprueba todas las operaciones de tipo X durante las próximas 4 horas”. Pero la pre-aprobación misma es operación que queda registrada, con identidad del aprobador, alcance del patrón, y duración. La aprobación en lote es eficiente operativamente pero requiere disciplina para no convertirse en aprobación genérica que vacía el modelo.
Reglas de detección de alucinaciones
La validación de respuestas — pilar 3 de Trust Infrastructure — opera con un conjunto de reglas que describimos a continuación. Cada una ataca un tipo distinto de error del agente.
La regla de self-consistency funciona así: el agente formula la misma pregunta de N maneras distintas. Si las N respuestas son consistentes, la confianza aumenta. Si difieren, alerta. La técnica explota una propiedad de los modelos LLM: cuando el modelo está cierto, sus respuestas son estables a través de pequeñas variaciones de la pregunta; cuando está alucinando, las respuestas son inestables. Self-consistency es relativamente barata y útil para detectar alucinaciones flagrantes.
La regla de retrieval-augmented verification funciona así: antes de afirmar un hecho, el agente busca evidencia en su corpus de datos confiables. Si encuentra evidencia consistente, afirma con confianza alta. Si no encuentra evidencia, responde con incertidumbre explícita o se abstiene. Esta técnica requiere que la organización mantenga corpus de datos confiables — bases de conocimiento curadas, no datos de internet sin verificar.
La regla de model-as-judge funciona así: un segundo modelo, idealmente distinto del primero, evalúa la respuesta del agente y emite un score de calidad. Si el score está bajo umbral, alerta o re-pregunta. La técnica es costosa (duplica la inferencia) pero útil para casos críticos donde el costo del error supera el costo de la validación.
La regla de constraint validation funciona así: las respuestas estructuradas — JSON, tablas, números — se validan contra un schema explícito. Si no cumplen, se reformulan o se escalan. Esta técnica es prácticamente gratuita y debe estar siempre activa para respuestas estructuradas — no usarla es desperdicio.
La regla de domain-specific guardrails funciona así: reglas específicas del dominio operan como verificación adicional. En finanzas, validar que cifras cuadren en sumas de control. En salud, validar que diagnósticos referencien guías clínicas reconocidas. En legal, validar que citas a leyes existan. Estas reglas son específicas al dominio y exigen inversión de los expertos del dominio para construirlas.
Las cinco reglas se aplican selectivamente según el contexto y costo. No todas se activan en cada operación — se activan según la criticidad de la decisión. Un agente que responde preguntas casuales sobre el clima no necesita las cinco; un agente que toma decisiones de inversión las necesita todas y posiblemente más.
Política de tokenización
La tokenización reemplaza datos sensibles por tokens antes de que lleguen al modelo de cognición. Es mecanismo crítico cuando la organización opera datos sensibles que no pueden exponerse al proveedor de cognición externo, pero que el agente necesita poder razonar para entregar valor.
Datos típicamente tokenizados
Cuatro categorías de datos típicamente requieren tokenización. PII (Personally Identifiable Information) — nombres, direcciones, teléfonos, emails — por razones de privacidad y compliance. Datos financieros — números de cuenta, tarjetas de crédito, balances — por regulación financiera. Datos de salud — identificadores médicos, diagnósticos, condiciones — por HIPAA y equivalentes. Secretos corporativos — API keys, contraseñas, datos clasificados — por seguridad operativa.
Mecanismo
El mecanismo canónico opera así. El dato original llega al servicio de tokenización, que devuelve un token opaco que reemplaza al dato. El servicio mantiene mapping interno entre el token y el dato original, en almacén con seguridad reforzada. El token opaco es lo que recibe la cognición — el modelo razona sobre el token sin saber qué representa. Cuando el agente toma una decisión y emite resultado, el resultado puede contener el token; el resultado vuelve a pasar por el servicio de tokenización, que de-tokeniza solo donde se requiere — por ejemplo, en la entrega final al usuario humano autorizado o en la invocación de un tool que requiere el dato real.
- El dato original llega al servicio de tokenización.
- El servicio devuelve un token opaco y mantiene el mapping token↔︎dato en un almacén con seguridad reforzada.
- La cognición razona sobre el token, sin saber qué representa.
- El agente emite su decisión, que puede contener el token.
- El resultado vuelve al servicio de tokenización, que de-tokeniza solo donde se requiere — la entrega final al humano autorizado o la invocación de un tool que necesita el dato real.
El modelo nunca ve el dato original. La de-tokenización ocurre solo en el punto donde el dato real es necesario.
Reglas operativas
Tres reglas operativas exigen disciplina en la implementación. La primera: tokenización antes de cognición externa. Si el agente usa un proveedor de cognición de terceros — Claude, GPT, Gemini —, los datos sensibles se tokenizan antes de salir del perímetro corporativo. Sin esta regla, los datos se exponen al proveedor incluso aunque la organización quisiera evitarlo. La segunda: de-tokenización auditada. Cada de-tokenización queda registrada en el append-only log. Permite reconstruir, después, dónde el dato original fue expuesto. La tercera: mapping en almacén separado. El mapeo token-a-dato-original vive en almacén con seguridad reforzada — típicamente un HSM (Hardware Security Module) o servicio dedicado de tokenización. Mantener el mapping en la misma base de datos que los datos operativos vacía la garantía de tokenización.
Catálogo mínimo viable
Una organización que opera agentes en producción debe tener, como mínimo viable, los siguientes componentes operacionalizados. Por debajo de este mínimo, la operación de agentes deja a la organización expuesta. Por encima, hay refinamiento progresivo según madurez y exigencia regulatoria del dominio. Nótese que este catálogo endurece deliberadamente algunos SHOULD de la spec (Capítulo 5 §4) a piso operativo — la detección de alucinaciones entre ellos: lo que la spec deja opcional para implementaciones mínimas, la operación enterprise lo exige.
| Componente | Mínimo viable |
|---|---|
| Catálogo de políticas | Al menos políticas de tools, datos, horarios, identidad, validación |
| CRUDLEX | Aplicado en todos los tools de Capa 4, con niveles preconfigurados |
| Append-only log | Inmutable, encadenado, retención según dominio |
| Aprobación humana | Configurable por operación, con timeout y registro |
| Detección de alucinaciones | Al menos self-consistency + domain guardrails, más constraint validation siempre activa en respuestas estructuradas |
| Tokenización | Para PII y datos financieros si aplica |
| Inventario de agentes | Quién opera, qué Capabilities, qué tools, quién aprobó |
| Dashboard de gobernanza | Visualización del inventario + métricas operativas |
Lo crítico de este catálogo no es la lista en sí — es que está construida con la misma disciplina con que cualquier organización seria construye su sistema de control financiero o su sistema de seguridad. Trust Infrastructure no es subproducto de tener IA agentiva. Es disciplina específica que la organización adopta cuando decide operar agentes en producción.
El patrón tripartito de despliegue — Cloud + Cliente + Local

Operacionalizar Trust Infrastructure en una organización enterprise no es ejercicio puramente técnico — es ejercicio de separación de responsabilidades entre tres planos que operan en lugares físicamente distintos. El patrón que esta operacionalización adopta como canónico para resolver este problema es el despliegue tripartito: tres componentes coordinados que viven en tres lugares con tres roles funcionales diferenciados.
El primer componente es el Cloud — el plano operado por el proveedor de la infraestructura agentiva. Su rol es control plane: gestión de licencias, registry de providers disponibles, integración con proveedores de cognición upstream, telemetría agregada con privacidad preservada. Es donde el proveedor mantiene viva la plataforma y resuelve los problemas que requieren visibilidad cross-cliente — incidentes que afectan a múltiples tenants, actualizaciones del catálogo de políticas canónicas, monitoreo de salud agregado del sistema. El cliente final no opera este componente; lo consume.
El segundo componente es el Cliente — el plano desplegado dentro de la red interna de la organización cliente. Su rol es governance plane: definición y enforcement de las políticas corporativas, integración con el identity provider del cliente, auditoría central de todas las acciones del agente, conexiones a los sistemas internos a los cuales el agente debe acceder. Aquí es donde se ejerce la gobernanza enterprise — porque la gobernanza vive donde la organización tiene control directo, no donde un proveedor externo la promete. El componente Cliente es lo que permite a la organización ejercer Trust Infrastructure sobre sus propios términos.
El tercer componente es el Local — el plano desplegado en el dispositivo de cada usuario. Su rol es execution plane: la app que conecta al agente del usuario (Claude Code, Cursor, Windsurf, cualquier cliente MCP) con el componente Cliente y con los providers locales. Aquí es donde la operación efectivamente ocurre — donde el agente del usuario invoca tools, donde las credenciales del usuario viven encriptadas localmente, donde la latencia de la operación se materializa.
La razón por la cual este patrón es estructural y no arbitrario es que cada uno de los tres planos resuelve un problema que los otros dos no pueden resolver bien. El Cloud no puede ejercer la gobernanza corporativa porque no vive dentro del perímetro de la empresa. El Cliente no puede mantener viva la plataforma sola porque cada empresa replicaría el trabajo común. El Local no puede tomar decisiones de gobernanza porque está bajo control del usuario individual, no de la organización. Los tres planos cooperan, pero ninguno sustituye a los otros.
La política se define donde la empresa controla. La IA opera donde el usuario trabaja. El ecosistema se mantiene donde el proveedor puede operarlo.
Este patrón es replicable por cualquier actor que opere infraestructura agentiva enterprise. La spec exige que los tres planos estén claramente separados — la mezcla de responsabilidades entre ellos produce sistemas que el cliente no puede gobernar (cuando la gobernanza vive en cloud del proveedor) o que el proveedor no puede operar (cuando todo vive en la red del cliente). La separación es la propiedad fundamental.
La economía de Trust Infrastructure operacionalizada
Implementar Trust Infrastructure tiene costo. Vale ser explícito sobre el costo porque la decisión de invertir o no invertir afecta directamente la viabilidad del sistema agentivo en producción.
El costo tiene tres componentes. La construcción inicial es one-time: catálogo de políticas, modelo CRUDLEX, append-only log con encadenamiento criptográfico, mecanismos de validación, integración con servicios de tokenización. Es trabajo de varios meses para una organización mediana. El mantenimiento operativo es continuo: agregar políticas nuevas según el sistema evoluciona, monitorear que las existentes siguen vigentes, ajustar umbrales según aprendizaje, mantener el inventario actualizado. Es trabajo continuo de un equipo dedicado. El sobrecosto de operación es por operación: latencia y cómputo de validar antes de actuar, registrar después, evaluar políticas en cada invocación. Es porcentaje sobre el costo de operación normal — típicamente del cinco al veinte por ciento según implementación.
El costo es real, pero es menor que el costo de no tener Trust Infrastructure. La proyección de cancelaciones de Gartner que el Capítulo 2 documenta pende sobre todo este capítulo — los controles de riesgo inadecuados son su tercera causa —, y el mismo capítulo registra la escala de comportamientos riesgosos que las organizaciones reportan de sus agentes. El costo de un proyecto cancelado o de un incidente — fuga de datos, decisión incorrecta de alto impacto, fallo regulatorio — es típicamente mucho mayor que el costo de prevenirlo.
Trust Infrastructure no es gasto. Es seguro contra el costo asimétrico de su ausencia.
La asimetría del costo es lo que justifica la inversión. Implementar Trust Infrastructure cuesta cantidad relativamente predecible. No implementarla expone a costos potencialmente catastróficos cuyo monto la organización no puede acotar previamente. El balance, cuando se calcula con disciplina, favorece la inversión.
Continuidad operacional — operacionalización del segundo mecanismo
El Capítulo 5 §4 formaliza la distinción entre los dos mecanismos complementarios de continuidad — fallback agéntico y continuidad de negocio operacional — y se asume aquí como dada. El primero ya está cubierto operacionalmente por la spec de los Lets (Cap 5 §2 y §7) y la garantía de no-detención de la capa (Cap 4). El segundo necesita operacionalización propia — la sección que sigue la entrega.
Protocolo de continuidad por sitio físico
Cada sitio físico operativo de un AgencyDomain con Capa 3 distribuida debe tener un protocolo de continuidad documentado. La spec define el contenido mínimo del documento. Sin ese contenido, el sitio no es operable bajo la spec en escenarios de continuidad — no porque la arquitectura falle, sino porque la operación humana no tiene guía cuando los componentes computacionales caen.
El contenido mínimo comprende cinco elementos:
- Rol del operador en modo continuidad — quién hace qué cuando el sistema cae. La definición debe ser nominal por puesto, no por persona. “El cajero pasa a modo continuidad y registra ventas en el cuaderno foliado de respaldo. El supervisor del local valida cada turno cerrado en modo continuidad.”
- Registros físicos de respaldo — cuadernos pre-foliados, talonarios numerados, tarjetas de comanda, formularios oficiales del regulador cuando apliquen. Cada registro físico es la fuente de verdad temporal mientras dura la continuidad; cuando la red vuelve, su contenido se ingresa al sistema.
- Umbrales de activación — a partir de qué tiempo de inactividad el sitio pasa a modo continuidad. Recomendación canónica: diez minutos para gastronomía y retail, treinta segundos para cobro tarjeta con autorización online, inmediato para emisión de comprobante regulado. Los umbrales son política del sitio, ajustables.
- Procedimiento de retorno — cómo se ingresan retroactivamente al sistema los registros físicos cuando la red vuelve. Debe explicitar quién ingresa, en qué orden, cómo se reconcilian conflictos con eventos que pudieron haberse procesado parcialmente antes del corte.
- Frecuencia de simulacros — cada cuánto se ejercita el protocolo. Recomendación canónica: trimestral con corte de red programado y duración mínima de quince minutos. Sin simulacros, el protocolo existe solo en papel y falla cuando se necesita en serio.
Modos de degradación del AgencyDomain
Una operación en producción no opera siempre en modo normal. La spec formaliza los cuatro modos canónicos de degradación según el escenario de falla, y la organización debe poder identificar en cada momento en qué modo opera cada sitio. Esta identificación es lo que permite gobernar las expectativas operativas.
| Modo | Condición | ¿Quién sostiene la operación? |
|---|---|---|
| Normal | Todos los componentes activos: cognición, central, edge, red corporativa. | Topología paralela completa. La operación elige la vía Cognición o la vía Autonomía según el patrón. |
| Cognición caída | Capa 2 inalcanzable; central y edge activos. | Vía Autonomía sostiene. Los Botlets senior ejecutan; los Botlets junior y en aprendizaje degradan a su última versión funcional. La cognición rescata fallos al volver. |
| Edge offline | Botler edge sin conexión al central; cognición inalcanzable; sitio físico aislado. | Botlets senior contra BD local + Conectores edge-resident. La cola de eventos hacia central acumula; al volver la red, drena y reconcilia. |
| Continuidad operacional total | Cognición + edge caídos por causa exógena (corte de energía, hardware destruido, red catastróficamente perdida). | Protocolo manual del sitio. El registro físico es la fuente de verdad temporal; el ingreso retroactivo al sistema es la reconciliación. |
La transición entre modos es automática hasta
Edge offline — el sistema detecta la falla y
degrada solo. La transición a Continuidad operacional
total es gobernada por el protocolo del sitio
— un humano la activa explícitamente cuando reconoce que ningún
componente computacional opera. Esta diferencia importa: los primeros
tres modos son responsabilidad de la arquitectura; el cuarto es
responsabilidad del cliente, ejecutado por sus operadores.
Trazabilidad de la transición a modo continuidad
El append-only log debe registrar las transiciones entre modos para que la auditoría posterior pueda reconstruir qué sostuvo la operación en cada momento. La spec define las marcas canónicas:
- Inicio de continuidad operacional — cuando el sitio
activa el protocolo manual, emite (cuando vuelve la red,
retroactivamente) un evento
mode-change: continuity-operationalcon timestamp del corte y duración estimada. - Registros físicos ingresados retroactivamente —
cada transacción ingresada desde registro físico lleva tag
provenance: manual-continuityyoriginal-timestamp: <hora física>distinto delsystem-timestamp: <hora de ingreso>. La distinción permite que reportes y reconciliaciones distingan eventos físicos de eventos digitales. - Reconciliación de cola edge — cuando un Botler edge
drena su cola hacia central tras volver la red, los eventos llevan tag
provenance: edge-queue-replaycon el timestamp original del sitio. - Distinción auditable entre fallback agéntico y continuidad
operacional — el log distingue eventos
agentic-fallback(la cognición rescató al Let — ejecutó por el Botlet o recibió el escalamiento del Agentlet) deoperational-continuity(humano sostuvo la operación). Auditoría posterior puede separar ambos casos sin ambigüedad. Esta distinción es lo que la organización presenta cuando un regulador pregunta cómo operó durante un incidente.
Propiedades exigidas operacionales
| Propiedad | Nivel |
|---|---|
| Distinción explícita en documentación de producto | MUST |
| Protocolo de continuidad documentado por sitio físico | MUST |
| Simulacros documentados con frecuencia mínima trimestral | SHOULD |
| Cuatro modos de degradación reconocibles por la organización | MUST |
| Trazabilidad de transición a modo continuidad en append-only log | MUST |
| Distinción auditable entre fallback agéntico y continuidad operacional | MUST |
| Reconciliación retroactiva de registros físicos al sistema | MUST |
La operacionalización completa del segundo mecanismo cierra el círculo abierto en Cap 5 §4. La distinción entre fallback agéntico y continuidad operacional ya no es solo conceptual — tiene protocolo de campo, modos canónicos de operación y trazabilidad auditable.
Lo que sigue
Cerrado el bloque operativo, el libro cierra con la implementación de referencia — el Capítulo 9 — y su epílogo. Quien haya leído los capítulos anteriores con la sensación de que cada uno deja preguntas abiertas tendrá ahí la confirmación explícita de que esa lectura es correcta: lo que sigue no es un cierre sino el reconocimiento de que esta especificación es un punto de partida formalizado, no un destino final.