Capítulo 5 · Primitivas
Las cuatro capas del Capítulo 4 son la respuesta arquitectónica al paradigma, pero no se sostienen solas: necesitan piezas reusables que las pueblen. Este capítulo entrega esas piezas — las primitivas técnicas canónicas del Mundo Agentivo. Cada sección formaliza una: el AgencyDomain (§1), el Botlet con su proto-Botlet (§2), la Capability (§3), la Trust Infrastructure (§4), la distinción Asistente vs Agente Autónomo (§5), la Faceta (§6) y el Agentlet (§7).
AgencyDomains
El Capítulo 4 introdujo la noción del AgencyDomain como construcción formal donde se materializa la Arquitectura Agentiva. Esta sección desarrolla esa noción con el detalle de una especificación. Lo que sigue es lo más cercano a una spec normativa que este libro entrega — un documento que un implementador puede tomar y construir, sabiendo qué es obligatorio y qué es opcional, qué propiedades debe satisfacer y qué decisiones puede tomar libremente.
Premisa fundacional — Space ≠ Domain
Las palabras cargan corporeidad. Space (espacio, en inglés) nace describiendo extensión física: oficina, escritorio, hogar, ciudad. Cuando un humano dice “mi espacio”, invoca lugar — coordenadas, paredes, presencia. La industria del software empresarial extendió la palabra a WorkSpace (espacio de trabajo) — Google Workspace, Microsoft 365, Notion — para nombrar la colección de soluciones que digitalizan lo que la persona hace en su escritorio físico: leer email, agendar reuniones, escribir documentos, archivar. WorkSpace es la prótesis digital del Space humano; ambos términos cargan la misma corporeidad de origen.
El agente no tiene cuerpo. No abre aplicaciones. No trabaja sobre un
escritorio. No habita en un espacio físico ni en metáfora de él: ejerce
agencia sobre un ámbito de jurisdicción computacional —
territorio digital donde su identidad rige, sus Capabilities aplican y
sus Botlets corren. La palabra latina que nombra exactamente eso es
Domain (dominium: ámbito de pertenencia y
soberanía).
Donde el humano tiene Space (WorkSpace), el agente tiene Domain (AgencyDomain).
El paralelo histórico — JSR-000148
El paralelo histórico se conserva: como JavaSpaces (JSR-000148, 1999) formalizó los espacios distribuidos para sistemas Java sin atar la implementación a un proveedor, esta especificación formaliza los AgencyDomains para sistemas agentivos con la misma agnosticidad. Múltiples implementaciones surgieron sobre JavaSpaces — GigaSpaces, Blitz, otras —, todas compatibles entre sí porque respetaban el contrato común. La spec sobrevivió a las implementaciones; las implementaciones evolucionaron sin que la spec necesitara reescritura constante. Ese es el patrón que AgencyDomains busca replicar para el campo agentivo. Este libro propone la spec; las implementaciones que cumplan con ella podrán llamarse AgencyDomain conforme.
La diferencia de nombre con su predecesor no es ruptura — es
precisión. Un Java Space (espacio) era espacio
computacional para procesos sin cuerpo; un Agency Domain
(dominio, ámbito) es ámbito de jurisdicción para agentes con
agencia. Lo que en 1999 se nombraba como “espacio” se nombra mejor en
2026 como “domain”. El término AgencyDomain carga
sentido en cada palabra. Agency — agencia, en su sentido
filosófico de capacidad de actuar — denota que el ámbito es habitado por
entidades con iniciativa propia, no por procesos pasivos.
Domain — dominium: ámbito de pertenencia y
soberanía — denota territorio donde la identidad del agente rige, no
proceso efímero. La unión de las dos palabras nombra exactamente lo que
la spec define: un ámbito donde el agente ejerce agencia.
Nota terminológica: en lore comercial (marca, ventas, comunicación cliente) la forma corta
Domainreemplaza aAgencyDomain. Es el patrón Apple iCloud / CloudKit, Stripe Connect / Account: marca corta + nombre técnico largo. Las dos formas son intercambiables; cada registro elige la suya.
Definición
Un AgencyDomain es un espacio computacional con identidad propia donde habitan agentes autónomos y Botlets en ejecución, donde se alojan y ejecutan las Capabilities que les dan el saber-hacer, y donde viven los recursos que los sostienen — cognición, tools, almacenamiento persistente. Constituye la unidad mínima de despliegue de un sistema agentivo productivo.
La Capability no es recurso de soporte: es saber-hacer cognitivo, habitante de primer orden del espacio junto al agente y al Botlet. La relación entre las dos primitivas es directa — un AgencyDomain aloja y ejecuta Capabilities; una Capability corre en un AgencyDomain anfitrión.
La spec define cómo deben construirse esos espacios — capas, identidad, ciclos de vida, protocolos de comunicación — sin prescribir una implementación específica. Múltiples implementaciones son admisibles siempre que respeten el contrato. Una implementación puede usar Kubernetes para contenerización; otra puede usar microVMs aisladas; otra puede usar procesos nativos en una sola máquina. Las tres son válidas si satisfacen las propiedades fundamentales que la spec exige.
Donde un agente vive, ese lugar es un AgencyDomain. Donde no hay AgencyDomain, no hay vida del agente — hay invocación de modelo.
La cita anterior distingue al AgencyDomain conforme a esta especificación de cualquier “endpoint que invoca un LLM”. Un endpoint que invoca un LLM responde a peticiones; un AgencyDomain hospeda agentes que viven. La diferencia es estructural, no de grado. Un sistema sin estado persistente, sin Botlets propios, sin capacidad de operación proactiva, no es AgencyDomain — es servicio. Puede ser servicio útil, pero no satisface lo que el campo agentivo requiere.
La unidad mínima importa. Un AgencyDomain no es subcomponente de algo más grande — es la unidad atómica del despliegue. Un sistema agentivo más grande es una colección de AgencyDomains que cooperan, posiblemente bajo un mismo gobierno o federados entre dueños distintos, pero cada uno conserva su identidad propia y sus propiedades fundamentales.
Propiedades fundamentales
Toda implementación que pretenda llamarse AgencyDomain conforme a esta spec debe satisfacer cinco propiedades fundamentales. La satisfacción no es opcional — un sistema que no las cumple no es AgencyDomain, sino otra cosa con otro nombre.
La primera propiedad es identidad propia. Cada AgencyDomain tiene una identidad única — una URI canónica — que lo distingue en cualquier red. La identidad sobrevive al reinicio del espacio, a la migración entre infraestructuras y al cambio de implementación. Si un AgencyDomain migra de un cloud provider a otro, su identidad no cambia: los agentes que lo habitan, los humanos que interactúan con él, los otros AgencyDomains que lo invocan, todos siguen reconociéndolo como el mismo espacio. La identidad es estable, no efímera.
La segunda propiedad es materialización de las cuatro capas. Un AgencyDomain materializa las cuatro capas de la Arquitectura Agentiva — Interacción, Cognición, Autonomía, Acceso — y ejerce Trust Infrastructure transversal. La materialización puede distribuirse técnicamente — las capas pueden vivir en infraestructuras distintas, en servidores físicos distintos, hasta en proveedores cloud distintos —, pero la responsabilidad por las cuatro recae en el espacio. No hay AgencyDomain conforme que entregue solo tres capas, o que delegue alguna capa a un sistema externo sin asumir responsabilidad sobre ella. La completitud es no-negociable.
La tercera propiedad es persistencia. El estado del AgencyDomain — agentes activos, Botlets en ejecución, datos de capabilities, logs de auditoría — sobrevive a desconexiones, reinicios y migraciones. Un AgencyDomain no es proceso efímero; es entidad persistente. Si el sistema se reinicia por mantenimiento, los agentes que estaban activos continúan donde estaban. Si la conexión a un servicio externo se cae temporalmente, el agente espera y reanuda. La persistencia es lo que hace al AgencyDomain lugar y no proceso.
La cuarta propiedad es aislamiento. Cada AgencyDomain tiene un límite explícito. Recursos internos — cómputo, memoria, datos — no son accesibles desde fuera salvo por interfaces definidas. La comunicación con el exterior pasa por la Capa 4 (Acceso) y queda registrada. El aislamiento no es solo seguridad — es contención de fallos: un AgencyDomain que se cae no afecta a otros AgencyDomains que comparten infraestructura, porque el límite contiene la falla. Los modelos de implementación que ofrecen aislamiento varían — desde sandboxing fuerte vía MicroVMs hasta aislamiento más liviano vía namespaces de Kubernetes —, pero el límite explícito existe siempre.
La quinta propiedad es direccionabilidad. Tanto el AgencyDomain como los agentes y Botlets que lo habitan son direccionables vía URLs predecibles. La sintaxis canónica que la spec adopta es:
{domain}/ → el espacio mismo
{domain}/agents/{agent} → un agente que vive en él
{domain}/agents/{agent}/botlets/{botlet} → un Botlet específico
{domain}/tools/{tool} → un tool expuesto vía Capa 4La direccionabilidad importa por dos razones operativas. Primera, es la base de la comunicación A2A — un agente que necesita invocar a otro agente lo hace a través de su URL canónica, sin necesidad de descubrimiento ad hoc. Segunda, es la base del MEO (Model Engine Optimization — el desplazamiento SEO→MEO que el Capítulo 6 §1 desarrolla): los modelos frontera que aprenden a referenciar AgencyDomains los hacen a través de URLs predecibles que aparecen en su corpus de entrenamiento. URLs caóticas o inestables hacen al AgencyDomain invisible para los modelos que no fueron entrenados con su mapa específico.
Modelo de datos canónico

La estructura interna de un AgencyDomain conforme sigue un modelo canónico que la spec define con precisión (figura arriba).
Cada componente del modelo tiene su rol específico. Identity mantiene la información que identifica el espacio frente al mundo: su URI canónica, las credenciales con las que se autentica frente a sistemas externos, las políticas raíz que ningún agente puede contravenir. Agents es la colección de agentes que viven en el espacio, cada uno con sus Capabilities asignadas, sus Botlets en ejecución y su estado persistente. Capabilities Registry es el árbol de capabilities disponibles para los agentes del espacio — saber-hacer compartido que los agentes pueden invocar según su rol. Tools Registry es la colección de tools que la Capa 4 expone hacia el exterior — la interfaz por la cual el AgencyDomain toca sistemas externos. Trust Layer ejerce gobernanza y auditoría transversales — políticas, log append-only, mecanismos de validación. Cognition Bindings son los bindings al recurso cognitivo — qué proveedor de modelo invoca el AgencyDomain, bajo qué credenciales, con qué políticas de uso.
La noción de Cuenta es concepto comercial superpuesto al modelo técnico. Una Cuenta puede poseer múltiples AgencyDomains. La spec trata la Cuenta como entidad opaca; cada implementación define su semántica específica — una empresa cliente, una organización federada, un usuario individual. La distinción entre AgencyDomain (técnico) y Cuenta (comercial) es importante porque permite que el modelo técnico evolucione sin que el modelo comercial necesite reescritura cada vez.
El modelo de regímenes

Un aspecto que distingue significativamente a la spec de AgencyDomains respecto a soluciones agentivas más limitadas es el reconocimiento de tres regímenes posibles de un AgencyDomain, análogos a los regímenes del cómputo en la nube. Los tres regímenes son técnicamente equivalentes en su estructura interna; lo que cambia entre ellos es la frontera de acceso, no la arquitectura.
El régimen privado corresponde a un AgencyDomain donde el espacio y todos sus componentes viven dentro de un perímetro controlado por una organización. No hay acceso público. Los agentes del espacio son invocables solo desde dentro de la organización. Los datos del espacio no salen del perímetro. Es análogo conceptual al Private Cloud — la organización tiene el control total de sus recursos, paga por ese control en términos de operación pero gana en términos de soberanía. El régimen privado es típico para casos donde la organización opera datos sensibles o cumple regulación que exige residencia local.
El régimen público corresponde a un AgencyDomain accesible públicamente. Agentes, Botlets y tools son invocables desde fuera del perímetro. El AgencyDomain tiene una URL pública y los agentes que lo habitan están registrados en un directorio que cualquier sistema externo puede consultar. Es análogo conceptual al Public Cloud — máxima accesibilidad, máxima exposición, modelo de operación distinto. El régimen público es donde la red de agentes coopera abiertamente con el resto de internet.
El régimen híbrido es combinación de los dos anteriores. Un AgencyDomain híbrido tiene componentes en perímetro privado y componentes accesibles públicamente vía proxy. Los datos sensibles permanecen privados, pero la interfaz que expone capacidades al exterior está disponible públicamente. Es análogo conceptual al Hybrid Cloud — la organización elige qué exponer y qué retener, balanceando soberanía y accesibilidad. El régimen híbrido es típico para organizaciones que necesitan ofrecer agentes públicos a sus clientes pero quieren mantener los datos del cliente dentro del perímetro corporativo.
Lo crítico de esta arquitectura de regímenes — y es propiedad fuerte de la spec — es que la estructura técnica del AgencyDomain es la misma en los tres regímenes. Un agente que opera en un AgencyDomain privado es técnicamente equivalente a uno que opera en uno público; lo que cambia es el régimen, no la capacidad. Un Botlet que ejecuta en privado puede mover ese mismo código a un régimen público sin reescritura. Esta uniformidad estructural habilita la migración natural entre regímenes — un agente puede graduarse de privado a público o viceversa sin cambiar su lógica interna. La organización gobierna el régimen; la lógica del agente no se entera.
Esta propiedad de migración natural es estructuralmente importante porque desacopla la decisión arquitectónica (cómo se construye el agente) de la decisión comercial (en qué régimen se opera). Una organización puede empezar construyendo agentes en régimen privado mientras valida su utilidad, y migrarlos a régimen público o híbrido cuando la madurez lo justifique. La inversión arquitectónica inicial no se pierde en la transición.
Para fijar la idea con instancias concretas a mayo de 2026 — ambas del portafolio de la casa; el marco de implementaciones vive al cierre de esta spec y en el Capítulo 9 —: Agentia opera AgencyDomains en régimen privado para firmas que mantienen sus agentes dentro del perímetro corporativo; Soveria opera AgencyDomains en régimen público donde agentes habilitados se hospedan con identidad pública y URL canónica; un mismo agente puede graduarse del primero al segundo sin reescritura técnica, manteniendo intacta la spec del agente y mudando sólo el régimen.
Modelos de acceso a la cognición
La spec reconoce dos modos coexistentes mediante los cuales los componentes del AgencyDomain acceden al recurso cognitivo (Capa 2). Los dos modos coexisten porque resuelven problemas distintos, y un AgencyDomain serio típicamente opera ambos simultáneamente para distintos componentes.
El primer modo es Tokens. El flujo es: AgencyDomain → recurso cognitivo, centralizado y facturado al espacio. El AgencyDomain centraliza credenciales, facturación y políticas. Provee acceso cognitivo a todos sus componentes activos. Este modo aplica cuando los agentes deben operar en background sin intervención del usuario, cuando la organización desea control central sobre consumo y costos, o cuando múltiples agentes comparten un mismo proveedor de cognición. La organización que opera Agentes Autónomos en background — agentes que monitorean continuamente, responden a eventos, ejecutan tareas asíncronas — necesita Tokens, porque no hay un humano disponible cuya suscripción individual subsidie las invocaciones.
El segundo modo es Suscripción. El flujo es: Asistente del usuario → recurso cognitivo, vía la suscripción del propio usuario. El asistente con el cual el usuario interactúa — Claude, ChatGPT, Copilot, Gemini — accede directamente al recurso cognitivo bajo la suscripción del usuario. El AgencyDomain no consume tokens del recurso. Este modo aplica cuando el usuario ya tiene una suscripción activa al proveedor de cognición, cuando el AgencyDomain expone tools y datos al asistente del usuario sin centralizar la cognición, o cuando la economía operativa del AgencyDomain privilegia minimizar costos de inferencia. La organización que adopta ultraPRO — una implementación del portafolio de la casa (Capítulo 9): el integrador seguro entre el agente del usuario y los sistemas corporativos — opera típicamente en modo Suscripción, porque los usuarios traen sus propias suscripciones a los proveedores de cognición.
Ambos modos coexisten en sistemas maduros. Un mismo AgencyDomain puede operar Asistentes del usuario (modo Suscripción) y Agentes Autónomos en background (modo Tokens), simultáneamente. La spec exige que el AgencyDomain declare explícitamente qué modo aplica a qué componente. La declaración explícita previene la fuente más recurrente de errores económicos en sistemas agentivos: confusión accidental entre modos, donde un Agente Autónomo que debería operar en Tokens termina facturando contra la suscripción del usuario y la agota en horas, o donde un Asistente que debería operar en Suscripción termina facturando contra el AgencyDomain y consume tokens que no debería.
El rol de los Botlets en la economía cognitiva merece énfasis
particular. En planes de Suscripción fija, los Botlets son el mecanismo
para lograr autonomía sin costo adicional: el ciclo 95/4/1
de los Botlets es la base económica de la autonomía bajo suscripción. El
desarrollo completo de esta economía vive en §2.
Ciclo de vida del agente
Un AgencyDomain conforme a la spec gestiona el ciclo de vida completo de cada agente que habita en él. El ciclo tiene seis fases canónicas, y cada transición entre fases queda registrada en el append-only log del Trust Layer.
La fase de provisioning es donde el AgencyDomain crea el agente. Asigna identidad, asocia las Capabilities iniciales que el agente puede invocar, registra al agente en el espacio. El agente nace, en términos del sistema, cuando esta fase termina exitosamente. Si la fase falla — por error de credenciales, por conflicto de nombre, por restricciones de cuota —, el agente nunca llega a existir.
La fase de bootstrap es donde el agente entra en operación. Carga su estado persistente si existe — si el agente había sido hibernado o reiniciado, recupera su contexto previo. Establece bindings con la cognición y los tools que va a usar. Verifica que sus Capabilities estén disponibles. Después de bootstrap, el agente está listo para responder o para operar proactivamente, según su modo.
La fase de operación reactiva corresponde al agente operando en modo Asistente. Capa 2 activa. El agente responde a solicitudes del humano: cada solicitud llega, el agente la procesa invocando cognición y posiblemente Capabilities, devuelve respuesta. Entre solicitudes, el agente está pasivo — no consume cómputo activo, no ejecuta nada. Esta fase es la más frecuente en sistemas que operan principalmente con Asistentes.
La fase de operación proactiva corresponde al agente operando en modo Agente Autónomo. Capa 3 activa. El agente persigue objetivos en background, monitorea eventos, ejecuta Botlets cuando corresponde, escala al humano cuando los umbrales lo exigen. Pattern Recognition genera y mantiene Botlets a medida que el agente identifica patrones repetitivos. Esta fase es donde se materializa el modelo “la inteligencia va hacia las personas y actúa en su nombre” — el agente está activo continuamente, el humano interviene solo cuando es necesario.
La fase de hibernación es donde el agente queda en pausa pero persistente. Estado guardado. No consume cómputo activo. Esta fase es útil cuando un agente no necesita operar durante períodos extendidos — un agente de soporte que solo opera durante horario hábil, por ejemplo, hiberna durante la noche y se reactiva con el inicio del día siguiente. La hibernación preserva el contexto sin gastar recursos.
La fase de decommissioning es donde el AgencyDomain retira al agente. El estado del agente se archiva o se elimina según política. Las Capabilities que tenía asignadas se liberan. La identidad del agente queda registrada en el log histórico, pero el agente deja de existir como entidad operativa. La fase de decommissioning es importante porque cierra el ciclo formalmente — un agente “decommissioned” no es lo mismo que un agente “olvidado”. El registro del decommissioning es lo que permite, semanas o meses después, reconstruir auditablemente que el agente existió, qué hizo, y por qué dejó de existir.
Comunicación entre agentes
La spec reserva el término A2A
(agent-to-agent) para la relación entre agentes, y
un agente es un AgencyDomain. La relación A2A es, por tanto,
entre AgencyDomains — entre agentes distintos, cada uno
con su propia identidad y agencia. La comunicación dentro de un mismo
AgencyDomain no es A2A en este sentido relacional: los componentes que
la sostienen son runtimes del mismo agente, no agentes distintos. La
spec distingue así dos planos: el plano
intra-AgencyDomain (un agente comandando sus propios
runtimes y memoria muscular) y el plano A2A (un agente
invocando a otro agente). Cuando dentro de un AgencyDomain se usa el
protocolo A2A como transporte entre
runtimes, se dice vía el protocolo A2A —
el nombre propio del protocolo —, nunca “A2A interna”, para no atribuir
agencia a runtimes que no la tienen.
¿Cómo comanda la Cognición a su memoria muscular? — interfaz Capa 2 ↔︎ Capa 3
La Cognición (el agente LLM, Capa 2)
comanda su propia memoria muscular — el Botler, runtime
de Capa 3 sin agencia — por una interfaz interna dentro
del mismo AgencyDomain. Es la relación Capa 2 → Capa 3: la Cognición
especializa, manifiesta, consume y controla los Botlets que el Botler
hospeda. El transporte natural de esta interfaz es
MCP (LLM↔︎herramienta): el
Botler expone uno o más servidores MCP y la Cognición es el
cliente. Esta interfaz no es A2A — no
cruza la frontera del AgencyDomain ni media entre agentes distintos; es
un agente operando su propio sustrato de ejecución. A2A
queda reservado para AgencyDomain↔︎AgencyDomain.
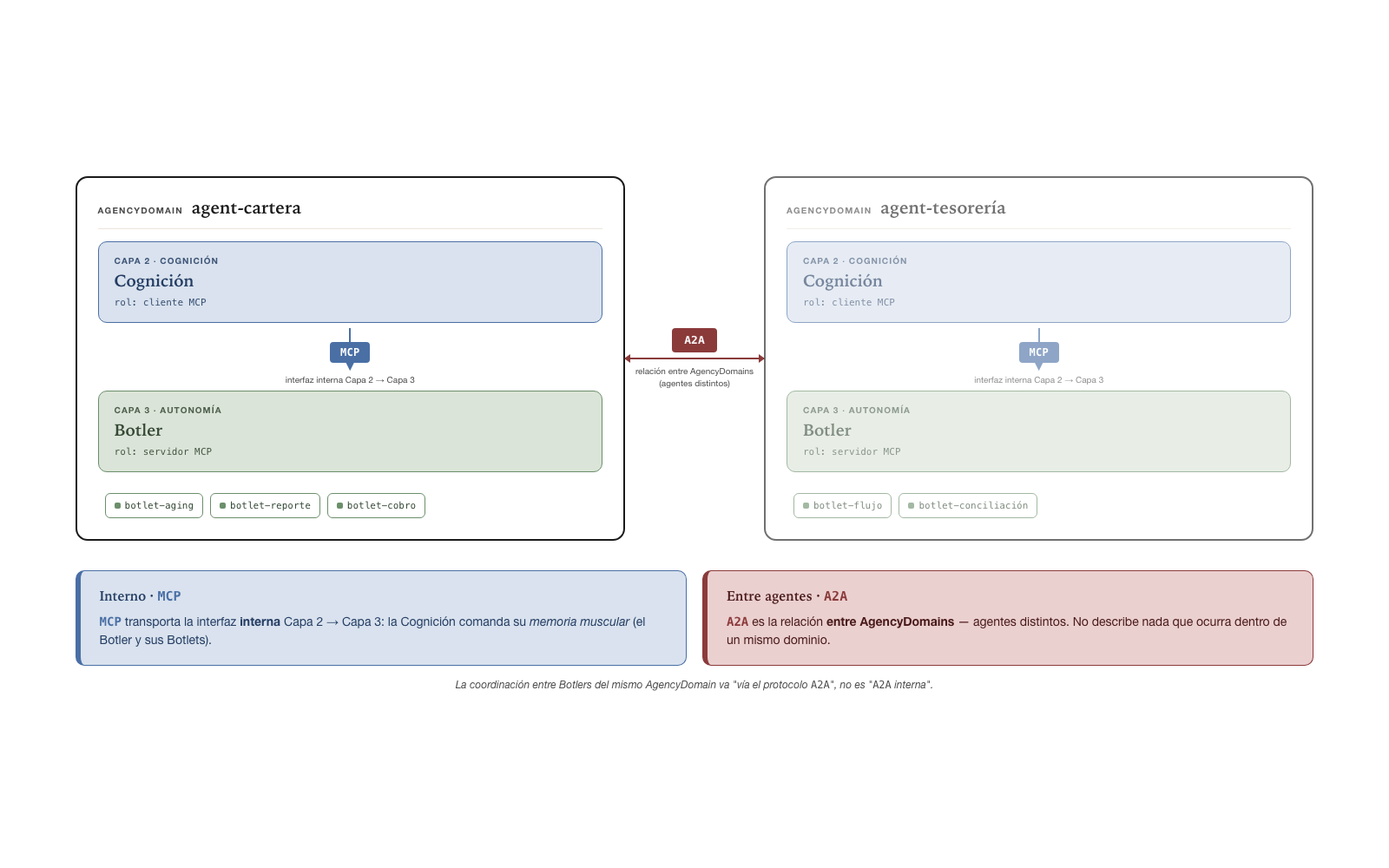
¿Qué propiedades exige la comunicación intra-AgencyDomain?
Toda comunicación entre componentes que viven en el mismo
AgencyDomain — sea la interfaz Capa 2 → Capa 3 vía
MCP, sea el transporte entre Botlers vía el protocolo
A2A — satisface tres propiedades que la spec exige. La
primera es direccionabilidad uniforme — cualquier
componente del espacio puede ser invocado por su URI canónica, sin
necesidad de descubrimiento ad hoc. La segunda es tipado de
mensajes — los mensajes tienen schema declarativo verificable;
quien emite declara el schema y quien recibe verifica que el mensaje lo
cumple antes de procesarlo. La tercera es trazabilidad
— toda invocación queda registrada en el append-only log con identidad
de emisor y receptor. Si un componente invocó a otro, el sistema sabe
quién, cuándo y con qué contenido.
¿Cómo se comunican agentes distintos? — A2A entre AgencyDomains
La comunicación A2A entre AgencyDomains
es entre agentes que viven en AgencyDomains distintos.
Esta modalidad requiere protocolos adicionales que la spec reconoce como
necesarios pero no completamente normaliza en su versión 1.0. Los
protocolos abiertos para A2A están en evolución — la
industria está convergiendo hacia ciertas direcciones, pero el consenso
completo no ha llegado. Lo que la spec sí define es que el
A2A entre AgencyDomains requiere tres mecanismos:
descubrimiento — cómo un AgencyDomain publica los
agentes que ofrece para ser invocados externamente;
autenticación cruzada — cómo dos AgencyDomains
verifican identidad mutuamente; resolución semántica —
cómo dos AgencyDomains que pueden tener glosarios distintos negocian el
significado de tools y capabilities cuando interoperan.
La especificación normativa completa del A2A entre
AgencyDomains — protocolo de descubrimiento, formato de mensajes
federados, resolución de identidad — es trabajo
abierto. Implementaciones de referencia pueden adoptar
protocolos emergentes, por ejemplo MCP federado, o el
protocolo A2A propuesto por Google. Cuando
exista consenso de industria sobre un protocolo específico, una versión
futura de esta spec lo incorporará como normativo. Por ahora, las
implementaciones serias tratan el A2A entre AgencyDomains
como capacidad emergente, no como spec consolidada.
Federación entre AgencyDomains

La federación es el mecanismo formal mediante el cual múltiples AgencyDomains colaboran como red. Hay que distinguirla del concepto cercano pero distinto del Cluster — múltiples instancias del mismo AgencyDomain operando como conjunto coordinado. Cluster es operacional; Federación es arquitectónica.
| Concepto | Granularidad | Ejemplo |
|---|---|---|
| Cluster | Múltiples instancias del mismo AgencyDomain | Tres instancias de un AgencyDomain de la misma firma compartiendo carga |
| Federación | Múltiples AgencyDomains distintos colaborando | El AgencyDomain de la firma A invoca un agente del AgencyDomain de la firma B |
La federación habilita ecosistemas de agentes que cruzan límites organizacionales. Un AgencyDomain puede invocar agentes de otro AgencyDomain, intercambiar datos, coordinar operaciones — todo bajo modelos de confianza explícitos que cada participante establece. Esto extiende el modelo agentivo más allá de los límites de una organización individual y permite redes de cooperación que se asemejan más a internet abierta que a sistemas corporativos cerrados.
La especificación normativa de federación es trabajo abierto. La versión 1.0 de la spec reconoce los mecanismos necesarios sin prescribir su implementación específica:
Un protocolo de descubrimiento abierto debe existir, posiblemente sobre DNS y bien-conocidos. Cuando un AgencyDomain quiere descubrir qué agentes ofrece otro AgencyDomain, debe poder consultar un endpoint estándar y obtener la lista. La spec no prescribe el formato exacto del endpoint — esa decisión depende del consenso de industria que aún no ha llegado.
Estándares de identidad criptográfica para AgencyDomains y agentes son necesarios. Cada AgencyDomain federado debe poder autenticarse criptográficamente — no por API key compartida, sino por mecanismo verificable que no requiere autoridad central. Las tecnologías candidatas incluyen DIDs (Decentralized Identifiers) del W3C, certificados X.509, mecanismos basados en blockchain. La spec admite cualquiera que satisfaga la propiedad fundamental: identidad verificable sin autoridad central.
Modelos de confianza explícitos son requisito. Cuando dos AgencyDomains interactúan, cada uno debe declarar el nivel de confianza que extiende al otro: qué operaciones permite, qué datos comparte, qué auditoría ejerce. La confianza no es binaria — un AgencyDomain puede confiar en otro para invocaciones de bajo impacto pero no para alto, o puede confiar para lectura pero no para escritura. La spec exige que estos modelos sean explícitos y configurables, no implícitos en código.
Resolución de conflictos cuando dos AgencyDomains aplican políticas contradictorias. Si el AgencyDomain A invoca a un agente del AgencyDomain B, y las políticas de A y B tienen conflictos — A permite la operación pero B la prohíbe, por ejemplo —, debe haber mecanismo claro para resolver el conflicto. La spec define que la prioridad es siempre del AgencyDomain receptor — es decir, B en este caso. El emisor puede pedir; el receptor decide.
Capa 3 distribuida — patrón canónico para presencia física múltiple
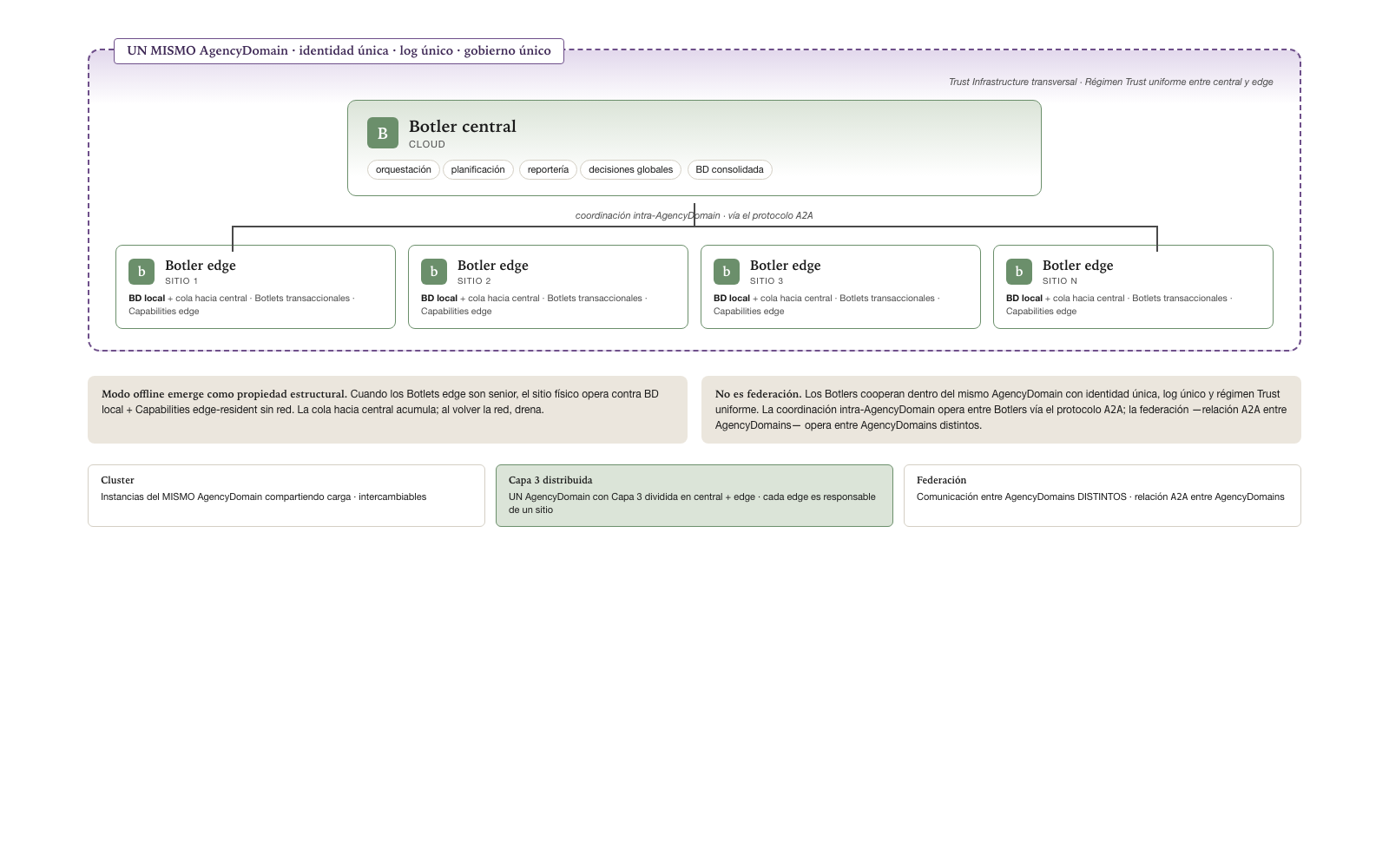
El Capítulo 4 (sección Capa 3 — Autonomía) anticipó que las cuatro capas pueden distribuirse técnicamente en infraestructuras distintas. Esta sección formaliza el caso particular más frecuente y operacionalmente importante: la distribución geográfica de la Capa 3 dentro de un mismo AgencyDomain. El patrón resuelve un escenario que cualquier organización con sucursales físicas múltiples encuentra invariablemente — gastronomía multilocal, retail con cadena de tiendas, logística distribuida, salud con red de centros, banca con sucursales, plantas industriales con líneas de producción simultáneas. Sin formalización, cada implementador reinventa el patrón con vocabulario propio y lo trata como excepción al modelo. Con formalización, queda como patrón canónico que cualquier implementación seria debe contemplar.
La distinción esencial es entre distribución interna y federación externa. La distribución interna ocurre cuando un mismo AgencyDomain divide su Capa 3 entre múltiples nodos físicos coordinados — un Botler central y N Botlers edge —, manteniendo identidad única, gobierno único, log único y modelo de datos único. La federación externa ocurre entre AgencyDomains distintos, cada uno con su identidad y gobierno propios. Cluster es un caso intermedio (mismo AgencyDomain, mismas instancias compartiendo carga). La distribución de Capa 3 es Cluster en términos de identidad — todos los Botlers pertenecen al mismo AgencyDomain — con la complicación adicional de que los Botlers no son intercambiables: cada Botler edge es responsable de un sitio físico específico.
Tres piezas del patrón
El patrón canónico distingue tres piezas con responsabilidades distintas:
1. Botler central. Hospeda los Botlets de orquestación, planificación, reportería, decisiones globales. Vive típicamente en cloud. Tiene visión consolidada del estado de todos los nodos edge. Ejecuta operaciones que requieren atravesar varios sitios — consolidar inventario, conciliar caja del día, planificar la operación del día siguiente, enviar reportes regulatorios consolidados. Mantiene la BD consolidada y el log de auditoría unificado. Comunica con la cognición (Capa 2) para escalamientos y decisiones nuevas.
2. Botlers edge. Uno por cada sitio físico. Hospedan los Botlets transaccionales locales — los que ejecutan la operación cotidiana del sitio: tomar pedidos, cobrar, emitir comprobantes, gestionar inventario local, controlar dispositivos físicos (pinpads, impresoras, sensores). Cada Botler edge mantiene una BD local con el estado del sitio y una cola de eventos hacia central que sincroniza cuando hay red. Operan con autonomía total cuando la red está disponible y con autonomía local cuando la red se cae — el sitio sigue operando contra su BD local; los eventos se acumulan en cola; cuando la red vuelve, la cola drena y la consolidación con el central se reanuda.
3. Coordinación entre Botlers vía el protocolo
A2A. Los Botlers central y edge se comunican
vía el protocolo A2A — el nombre propio
del protocolo de coordinación. No es A2A en sentido
relacional: estos Botlers son runtimes del mismo agente — el mismo
AgencyDomain —, no agentes distintos, de modo que la coordinación entre
ellos es comunicación intra-AgencyDomain, no
A2A entre AgencyDomains. La conversación atraviesa la red
corporativa pero no atraviesa la federación — está
enteramente dentro de un solo AgencyDomain. La distinción no es
retórica: el régimen de Trust Infrastructure es el del AgencyDomain
único, no el de federación entre AgencyDomains; el log es unificado; el
modelo de identidad es interno; las políticas se aplican
uniformemente.
Modo offline como propiedad emergente
Bajo la topología paralela del Capítulo 4 + el patrón de Capa 3 distribuida, el modo offline de un sitio físico emerge como propiedad estructural del sistema, no como capacidad especial que requiere construcción separada. Cuando la red se cae en un sitio, dos cosas ocurren simultáneamente: la vía Cognición queda inactiva (la Capa 2 vive en cloud y no es accesible), y el Botler central tampoco es accesible. Pero el Botler edge sigue activo: sus Botlets corren contra la BD local, los Conectores edge-resident (impresora ESC/POS, gaveta, pinpad) siguen disponibles, la operación cotidiana del sitio continúa. La cola de eventos hacia central acumula transacciones pendientes; cuando la red vuelve, drena y consolida.
La condición para que el modo offline opere correctamente es que los
Botlets edge sean senior en términos de la propuesta de
madurez (sección §2): Botlets que ya incorporaron las variantes del
ambiente y operan con ratio cercano a 99+ / <1 / ~0. Un
Botlet edge en fase junior — todavía descubriendo variantes — no puede
operar sin la posibilidad de fallback a cognición. Un Botlet edge senior
sí puede, porque sus únicos modos de fallo son exógenos (energía,
hardware, red catastrófica), no aprendizaje pendiente.
Propiedades exigidas del patrón
Una implementación de AgencyDomain con Capa 3 distribuida debe satisfacer:
| Propiedad | Nivel | Descripción |
|---|---|---|
| Identidad única del AgencyDomain | MUST | Todos los Botlers (central + edge) pertenecen al mismo AgencyDomain con una sola URI canónica. |
| BD local en cada Botler edge | MUST | Estado operativo del sitio físico, accesible sin red. |
| Cola de eventos hacia central | MUST | Mecanismo de sincronización eventual; transacciones pendientes drenan cuando hay red. |
| Resolución de conflictos en consolidación | MUST | Cuando un evento desde edge llega a central y entra en conflicto con el estado consolidado, política explícita decide. |
| Log de auditoría unificado | MUST | Un solo append-only log para todo el AgencyDomain, alimentado por todos los Botlers. |
| Modelo de identidad interno único | MUST | Los Botlers no se autentican como AgencyDomains externos entre sí; comparten el modelo de identidad del AgencyDomain. |
| Régimen Trust uniforme | MUST | Las políticas se aplican igual en central y edge; no hay régimen especial para edge. |
| Capacidad de operación offline en edge | SHOULD | Cuando los Botlets edge son senior, el sitio opera con red intermitente o sin red. |
Portabilidad del AgencyDomain entre plataformas conformes
La sección de regímenes formalizó la migración natural entre regímenes (privado, público, híbrido) sin reescritura. Esta sección formaliza una propiedad complementaria pero distinta: la portabilidad entre plataformas hosting conformes a la spec. Un AgencyDomain conforme puede migrarse a otra plataforma conforme sin reescribir su lógica, su estado, ni sus políticas. Esto es propiedad estructural de la spec — no compromiso comercial de un proveedor particular.
La motivación es operativa antes que filosófica. Sin compromiso explícito de portabilidad, el AgencyDomain repite el lock-in de la era de las aplicaciones — el cliente queda atado a su proveedor agéntico exactamente como antes quedaba atado a su proveedor SaaS. La promesa estructural de la spec — que el AgencyDomain es propiedad real del cliente, no del hosting — depende de que la portabilidad sea propiedad de la spec, no concesión negociada caso por caso.
Tres condiciones técnicas
La portabilidad exige tres condiciones técnicas que cualquier implementación conforme debe satisfacer:
1. Botlets contra primitivas canónicas. Los Botlets
del AgencyDomain deben invocar Capabilities y el SDK de AgencyDomain
conforme, no APIs propietarias del hosting actual. Si
un Botlet invoca una API específica del proveedor —
cloudprovider.lambda.exec, vendor.workflow.run
—, esa invocación es deuda de portabilidad. Cuando llega el momento de
migrar, ese Botlet debe regenerarse para invocar la primitiva canónica
equivalente. Una implementación conforme provee SDKs y registries que
abstraen del hosting; el Botlet ve la primitiva, no la
implementación.
2. BD operativa exportable. El estado persistente del AgencyDomain — agentes, Botlets, capabilities, log de auditoría, datos operativos — debe ser exportable en formato neutro, sin dependencias del motor de almacenamiento del hosting. Esquema documentado (DDL portable o representación equivalente). Dump completo (toda la información necesaria para reconstruir el espacio en otra plataforma). Sin tipos de datos propietarios. Sin extensiones específicas del motor que no tengan equivalente en motores estándar. La portabilidad de la BD es lo que permite que la migración no sea reescritura.
3. Trust Layer portable. Las políticas, el log append-only, la configuración de Capabilities y los bindings de identidad deben mantenerse en formato neutro reproducible — típicamente Markdown estructurado o YAML/JSON con schema explícito. La spec no prescribe el formato exacto, pero exige que el formato sea legible por cualquier implementación conforme, no solo por la implementación actual. Una política que solo el motor de políticas de un proveedor sabe interpretar no es política del AgencyDomain — es configuración del proveedor.
Migración natural vs portabilidad
Las dos propiedades — migración natural entre regímenes y portabilidad entre plataformas — son complementarias pero distintas:
| Eje | Migración natural entre regímenes | Portabilidad entre plataformas |
|---|---|---|
| ¿Qué cambia? | El régimen del AgencyDomain (privado → público) | La plataforma de hosting |
| ¿Qué permanece? | Plataforma de hosting | Régimen del AgencyDomain |
| ¿Quién decide? | La organización dueña, según madurez de uso | La organización dueña, según economía o estrategia |
| Frecuencia esperada | Una o dos veces en la vida del AgencyDomain | Cero o pocas veces, pero la posibilidad debe existir |
La portabilidad no es promesa de que la migración será trivial — siempre habrá costo de orquestación, validación, ventana de corte. Es promesa de que la migración será posible sin reescribir la lógica del agente. Esa diferencia — entre posible-con-trabajo y imposible-sin-reescritura — es lo que separa un AgencyDomain conforme de un sistema agentivo proprietary disfrazado.
Conformidad
Una implementación que pretenda llamarse AgencyDomain conforme a esta especificación debe satisfacer la siguiente lista de requisitos. Los marcamos con la convención de IETF: MUST para obligatorio, SHOULD para fuertemente recomendado, MAY para opcional.
| Requisito | Nivel |
|---|---|
| Identidad propia | MUST |
| Materialización de las cuatro capas | MUST |
| Persistencia del estado | MUST |
| Aislamiento entre espacios | MUST |
| Direccionabilidad URL | MUST |
| Modelo de datos canónico | MUST |
| Soporte de los tres regímenes | SHOULD (al menos uno; idealmente los tres con migración) |
| Soporte de modos Tokens y Suscripción | MUST ambos |
| Ciclo de vida completo del agente | MUST |
Comunicación intra-AgencyDomain (interfaz Capa 2 → Capa 3 vía
MCP; coordinación entre runtimes vía el protocolo
A2A) |
MUST |
A2A entre AgencyDomains |
SHOULD |
| Federación | MAY (cuando la spec normativa esté disponible) |
| Trust Infrastructure transversal | MUST |
| Principio Agent First | MUST |
| Capa 3 distribuida (Botler central + edge) | SHOULD (cuando hay presencia física múltiple) |
| Portabilidad entre plataformas conformes | MUST (Botlets contra primitivas canónicas, BD exportable, Trust Layer portable) |
Una implementación que cumple todos los MUST es AgencyDomain conforme a la versión 1.0 de la spec. Una implementación que cumple los MUST y los SHOULD es lo que llamaríamos AgencyDomain de referencia — implementación ejemplar que la industria puede tomar como base. Las implementaciones que cumplen también los MAY son implementaciones de frontera, que típicamente lideran la evolución del campo.
Implementaciones de referencia
Como mencionamos en el Capítulo 4, esta especificación es agnóstica a
implementación. La implementación de referencia pública
es Vergis: distribuida bajo AGPL, con
repositorio público en AgencyDomains.org, diseñada para que cualquier
desarrollador o estudiante pueda descargarla, leerla, ejecutarla y
aprender cómo la spec se traduce en un sistema vivo. El Capítulo
9 la desarrolla en detalle; aquí basta con dejar el puntero y
afirmar que es conforme.
Sobre la misma estructura canónica operan también implementaciones de productos en regímenes complementarios: Agentia materializa AgencyDomains en régimen privado dentro de la infraestructura de la firma cliente, y Soveria los materializa en régimen público como red de agentes con identidad pública. Otras implementaciones son admisibles y bienvenidas. La especificación pretende ser estándar de industria, no propiedad intelectual de un actor.
Frontera de evolución
Tres áreas de la especificación están en evolución activa y una versión futura del libro probablemente las normalizará con mayor detalle.
La federación es la primera. Como mencionamos, el protocolo normativo aún no está consensuado por la industria. La versión 1.0 reconoce los mecanismos necesarios sin prescribirlos en detalle. Cuando el consenso llegue — probablemente en los próximos dos a tres años —, la spec lo incorporará.
La cognición agnóstica es la segunda. La spec admite cognición no-LLM — simbólica, multimodal, híbrida. La implementación contemporánea es predominantemente LLM-céntrica. La extensión a otros sustratos cognitivos exige refinamiento de las interfaces entre Capa 2 y los demás componentes del AgencyDomain.
La identidad criptográfica de agentes es la tercera. El modelo de identidad verificable on-chain o por DID está en exploración. La adopción depende de que el ecosistema más amplio de identidad descentralizada madure suficientemente para soportar el caso de uso agentivo.
Dos de estas fronteras — la federación y la cognición agnóstica — coinciden con las del Capítulo 4; la identidad criptográfica es propia de esta spec. Todas son fronteras de la arquitectura misma, no solo de su materialización en AgencyDomains.
Botlets
Cuando un pianista aprende una pieza nueva, los primeros minutos son una experiencia consciente y costosa. El pianista mira la partitura, identifica cada nota, decide la digitación, ejecuta cada movimiento de los dedos prestando atención plena. La pieza, en esa primera lectura, es trabajo cognitivo intenso. Una hora más tarde, después de práctica deliberada, los dedos empiezan a tocar solos. El pianista todavía sigue la partitura, pero ya no tiene que decidir conscientemente cada nota — los dedos saben dónde van. Una semana después, la pieza está incorporada en la memoria muscular: el pianista la ejecuta sin pensar. Si en algún momento se equivoca o algo sale del esperado — un sonido raro, una digitación incómoda — la conciencia vuelve a aparecer brevemente, evalúa el problema, ajusta, y luego se retira de nuevo. La memoria muscular vuelve a tomar control.
Esta dinámica del aprendizaje motor humano no es metáfora arbitraria. Es la base neurobiológica documentada por Squire y Wixted en su trabajo de 2011 sobre los sistemas de memoria humana, ampliando trabajo previo de Larry Squire sobre las modalidades de memoria. La corteza prefrontal aprende patrones nuevos invirtiendo recursos cognitivos costosos. Los traspasa a estructuras subcorticales — el cerebelo, los ganglios basales — que los ejecutan sin intervención consciente. La corteza prefrontal se reactiva solo cuando detecta una desviación significativa que la rutina codificada no maneja. Esta arquitectura es lo que permite que el cerebro humano opere eficientemente: lo costoso se minimiza, lo barato se maximiza, y la atención consciente se reserva para cuando es realmente necesaria.
La Arquitectura Agentiva replica esta arquitectura biológica con disciplina. Lo que el cerebro hace con corteza prefrontal y memoria procedimental, el sistema agentivo lo hace con cognición LLM y Botlets. Cuando un agente enfrenta una tarea por primera vez, la cognición — Capa 2 — la procesa con los recursos costosos del LLM: razona, decide, ejecuta. Cuando la tarea se repite con frecuencia, la cognición delega la ejecución a un Botlet — código tradicional, no-LLM, que la cognición misma generó — que vive en Capa 3 y ejecuta sin invocar al modelo. Si el ambiente cambia y el Botlet falla, la cognición vuelve a tomar control: regenera el Botlet adaptado al ambiente nuevo o, en el peor caso, ejecuta la tarea manualmente. Lo costoso se minimiza, lo barato se maximiza, la cognición se reserva para casos genuinamente nuevos.
La cognición piensa una vez. El Botlet ejecuta diez mil veces.
Esta sección desarrolla la primitiva del Botlet con el detalle que merece. La spec del Botlet es probablemente la primitiva más importante para la economía operativa de un sistema agentivo — sin Botlets, los costos de inferencia hacen inviable la autonomía continua; con Botlets bien diseñados, la organización puede operar agentes en producción a costos predecibles y estables.
Definición
Un Botlet es una unidad de automatización auto-evolutiva: código tradicional, no basado en LLM, generado por un agente para ejecutar una tarea repetitiva sin invocar cognición costosa. Los Botlets son la memoria muscular del agente — el equivalente computacional de los gestos automatizados que un humano ejecuta sin pensar conscientemente.
Cuatro propiedades distinguen al Botlet de cualquier “macro” o “script automatizado” tradicional. La primera es que el código del Botlet no lo escribió un humano: lo generó la cognición del agente cuando reconoció un patrón repetitivo en su actividad. Esto importa porque la generación dinámica del código permite que el sistema adapte la automatización a cada contexto particular, sin depender de que un programador anticipe cada caso. La segunda es que el Botlet ejecuta sin invocar cognición durante operación normal. Una vez generado, el Botlet corre como código tradicional — Python, JavaScript, Bash, lo que sea —, independiente del modelo que lo creó. La tercera es que se regenera automáticamente cuando detecta que el ambiente cambió. Si el Botlet falla porque una API cambió, una estructura de datos varió, o una pantalla se renombró, la cognición regenera el Botlet adaptado al ambiente nuevo. La cuarta — y crítica — es que tiene garantía de fallback: si el Botlet falla catastróficamente y no puede ejecutarse, la cognición ejecuta la tarea manualmente. El proceso nunca se detiene.
La diferencia con un script tradicional es estructural. Un script tradicional que falla deja a la operación detenida hasta que un humano intervenga: alguien debe identificar el problema, modificar el script, redeployarlo, validar. Un Botlet que falla activa la cognición, que ejecuta la tarea — en ese caso particular, sin Botlet — y registra el evento para regenerar después. La organización puede depender del Botlet sin riesgo operativo, porque la falla del Botlet no es falla del sistema.
El ciclo 95/4/1
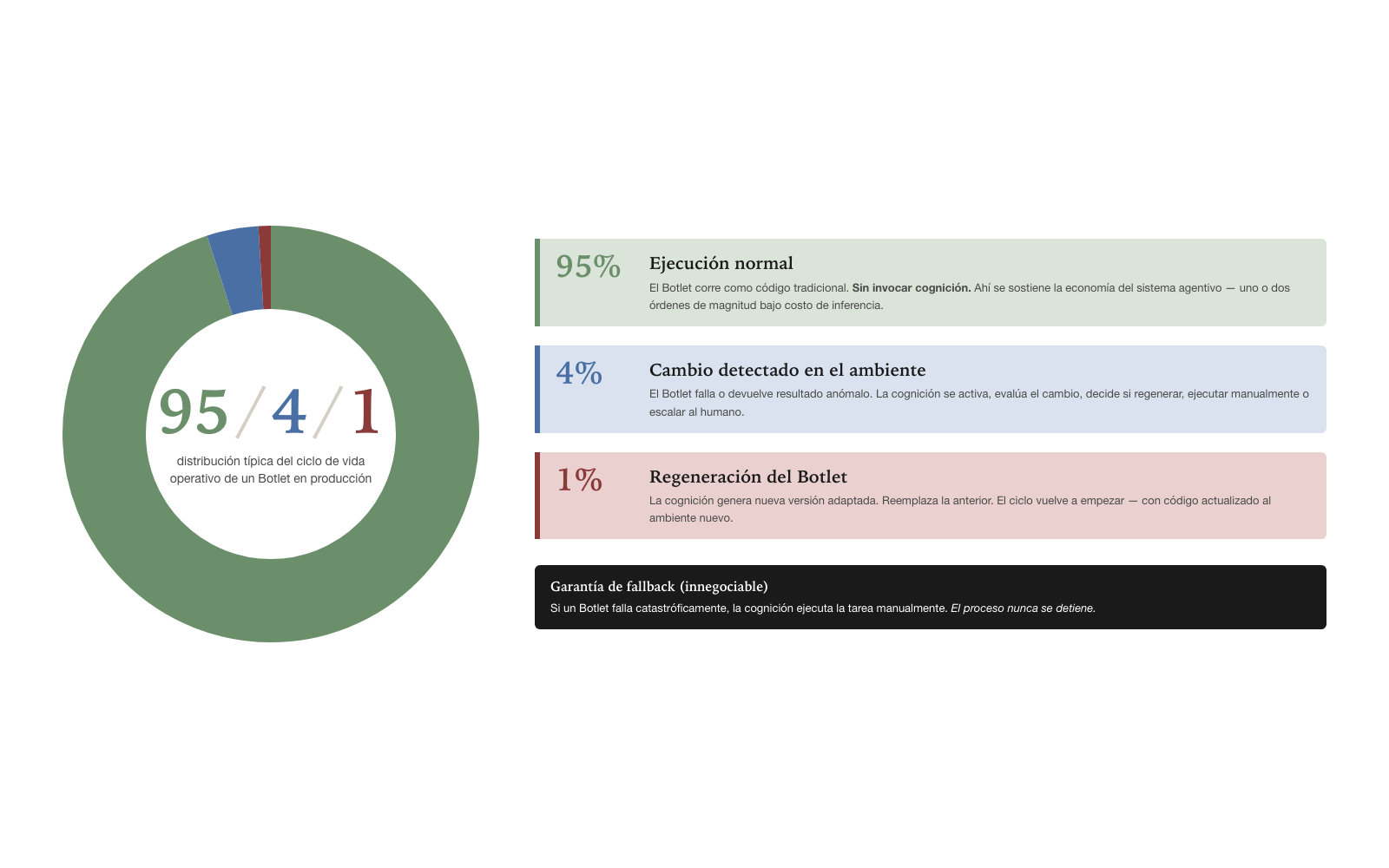
El ciclo de vida operativo de un Botlet en producción se distribuye
típicamente con la proporción que da nombre a este modelo:
95/4/1. Las proporciones son aproximadas
pero estructuralmente correctas: la mayor parte del tiempo el Botlet
ejecuta sin invocar cognición; ocasionalmente el ambiente cambia y el
Botlet falla; raramente la cognición debe regenerar el código.
El noventa y cinco por ciento del tiempo, el Botlet está en ejecución normal. La cognición no se invoca. El Botlet corre, completa su tarea en segundos o minutos según el caso, devuelve resultado. Esta es la fase eficiente — donde toda la economía del sistema agentivo se sostiene. Una organización que opera mil agentes con Botlets bien diseñados ejecuta noventa y cinco por ciento de las tareas a costo de cómputo tradicional, no a costo de inferencia LLM. La diferencia económica es de uno o dos órdenes de magnitud.
El cuatro por ciento del tiempo, el Botlet detecta un cambio en el ambiente. Falla o devuelve un resultado anómalo. El ambiente cambió: un campo de la API se movió, una estructura de datos varió, la respuesta de un sistema externo tiene un formato distinto. El Botlet, escrito para el ambiente de hace dos semanas, ya no funciona. La cognición se activa. Evalúa el cambio: ¿es algo que se puede manejar regenerando el Botlet? ¿es algo que requiere ejecución manual única en este caso? ¿es algo que requiere escalación al humano?
El uno por ciento del tiempo, la cognición decide regenerar el Botlet. Genera una nueva versión adaptada al ambiente cambiado. La nueva versión queda como Botlet activo, reemplazando la versión anterior. Las próximas invocaciones — la nueva fase del noventa y cinco por ciento — usan la versión regenerada. El ciclo se cierra y vuelve a empezar.
La proporción exacta varía según el caso. Un Botlet operando contra un sistema externo muy estable puede mantener noventa y nueve por ciento de ejecución normal y solo uno por ciento de cambio detectado. Un Botlet operando contra un sistema externo volátil puede caer a ochenta por ciento de ejecución normal con quince por ciento de cambios y cinco por ciento de regeneración. Lo importante no son las proporciones específicas: es la estructura del ciclo. El Botlet ejecuta la mayoría del tiempo sin cognición; la cognición se reserva para los casos donde el ambiente cambia.
Madurez del Botlet — junior, en aprendizaje, senior

El ciclo 95/4/1 es presentación didáctica útil, pero es
estática: describe el estado estacionario de un Botlet
ya conformado, no la trayectoria por la cual el Botlet llega a ese
estado. La realidad operativa exige una distinción adicional: un Botlet
recién generado no opera con la proporción
95/4/1. Opera con una proporción peor. Solo
después de incorporar las variantes del ambiente alcanza la madurez que
el ciclo canónico describe. Esta sección formaliza la trayectoria.
La spec reconoce tres fases canónicas en la madurez de un Botlet: junior, en aprendizaje, senior. Las fases no son etiquetas administrativas; son estados con propiedades distintas que el sistema rastrea para decidir cuánto delegar al Botlet y cuándo escalarlo.
Fase junior
Un Botlet junior es un Botlet recién generado. Acaba de salir de la cognición. Conoce el ambiente solo en la versión que la cognición observó cuando lo creó. Las variantes del ambiente — fechas en formato distinto, mensajes de error con redacción nueva, campos opcionales que aparecen solo a veces, casos límite — todavía no han pasado por él, así que su código no las contempla.
La proporción típica de un Botlet junior es algo como
60 / 35 / 5: solo el 60% de las invocaciones son ejecución
normal exitosa; el 35% son fallos por variantes del ambiente que el
Botlet no anticipa; el 5% son regeneraciones cuando la cognición decide
que la variante observada es estructural y debe incorporarse. La
proporción es desfavorable, pero no es problema — es la fase normal de
cualquier Botlet recién generado, y la cognición está ahí precisamente
para rescatarlo.
Operativamente, un Botlet junior depende fuertemente de la disponibilidad de la cognición (Capa 2). No puede operar offline porque demasiadas de sus invocaciones requieren rescate. Tampoco puede asumir responsabilidades críticas sin red de seguridad explícita.
Fase en aprendizaje
Un Botlet en aprendizaje es un Botlet que ya pasó
por las primeras invocaciones reales. Ha enfrentado variantes del
ambiente y ha sido regenerado varias veces para incorporarlas. Su
proporción se mueve hacia algo como 85 / 12 / 3: la mayoría
de las invocaciones son exitosas, los fallos por variantes nuevas son
menos frecuentes, las regeneraciones son ocasionales.
La fase en aprendizaje es la fase más larga de la vida útil del Botlet — puede durar semanas o meses según la frecuencia de invocación y la volatilidad del ambiente. Cada regeneración consolida saber operativo: cada variante incorporada es una variante menos que puede sorprender al Botlet en el futuro.
Operativamente, un Botlet en aprendizaje puede operar con red intermitente — los fallos siguen siendo lo suficientemente frecuentes como para necesitar la cognición disponible regularmente, pero no en cada invocación. Puede asumir responsabilidades operativas con observación humana cercana.
Fase senior
Un Botlet senior es un Botlet que ya incorporó las
variantes del ambiente. Su proporción tiende a
99+ / <1 / ~0: prácticamente todas las invocaciones son
ejecución normal exitosa; los fallos por cambios de ambiente son raros
porque el ambiente ya rara vez le presenta algo que no conozca; las
regeneraciones son excepcionales.
Una propiedad fundamental del Botlet senior cambia respecto a las fases anteriores: sus fallos en estado senior no son cambios de ambiente; son causas exógenas. Cuando un Botlet senior falla, la causa típica es algo que detendría a cualquier sistema estable: corte de energía, hardware caído, red catastróficamente perdida, recurso externo (proveedor de tools, sistema regulado) caído. Estos fallos no son aprendizaje pendiente — son lo mismo que cualquier sistema operativo encuentra ocasionalmente y resuelve con redundancia, restart o intervención humana.
Operativamente, un Botlet senior puede operar offline confiablemente. La razón es estructural: si sus únicos modos de fallo son exógenos, la presencia o ausencia de la cognición no cambia la probabilidad de fallo significativamente — la cognición no tiene cómo rescatar de un corte de energía. El Botlet senior, contra una BD local y Conectores edge-resident, sostiene la operación del sitio físico aunque la cognición esté inalcanzable. Esta propiedad es la base estructural del modo offline en sistemas con Capa 3 distribuida (Capítulo 5 §1).
Implicaciones de la trayectoria
La distinción entre las tres fases tiene tres implicaciones que conviene retener.
Primera, el offline confiable es propiedad de Botlets senior, no de Botlets en general. Pretender que un Botlet recién deployado en un local nuevo pueda operar offline es violar la spec — todavía es junior, depende de la cognición. La trayectoria de un nodo edge desde puesta en producción hasta operación offline plena requiere tiempo de exposición al ambiente, no es propiedad instantánea.
Segunda, la garantía de fallback agéntico es lo que produce la madurez. Cada fallo del Botlet por cambio de ambiente activa la cognición; cada activación de la cognición regenera el Botlet incorporando la variante. Sin fallback agéntico, el Botlet quedaría atrapado en su versión inicial, sin manera de aprender. La conexión con la sección de continuidad de negocio operacional del §4 es directa: la garantía de fallback resuelve la fase junior y la transición hacia senior; la continuidad operacional resuelve los fallos exógenos de la fase senior.
Tercera, la madurez de un Botlet es trazable. El append-only log del Trust Layer registra cada invocación, cada fallo, cada regeneración. La proporción de cada fase es observable, y la trayectoria de un Botlet desde junior hasta senior es auditable. Esta trazabilidad es lo que permite que la organización tome decisiones operativas — “este Botlet ya es senior, podemos delegarle responsabilidades críticas” — sobre evidencia, no sobre suposición.
Botlets seed vs Botlets emergentes — el origen del Botlet
El ciclo hasta aquí descrito supone que Pattern
Recognition — la primitiva auxiliar que se desarrolla más abajo
— activa la generación de un Botlet al detectar un patrón repetitivo no
anticipado. Esa es la modalidad emergente de
generación. Es la modalidad que el modelo neurobiológico inspira y que
el ciclo 95/4/1 describe en su forma más pura. Pero
no es la única modalidad, y para sistemas productivos
reales no es ni siquiera la más frecuente.
En un sistema productivo, los Botlets críticos del MVP no emergen: los implementa la cognición porque el equipo de diseño los planificó como parte de la spec del producto. El equipo sabe, antes de que el sistema vea su primera transacción, que va a necesitar un Botlet de POS, un Botlet de comanda, un Botlet de cobro, un Botlet de cierre de turno. La cognición ejecuta la implementación de esos Botlets; pero la decisión de existir la tomó el diseño, no Pattern Recognition.
La spec distingue por tanto dos orígenes canónicos del Botlet:
Botlets seed. Generados por la cognición a pedido del equipo de diseño, como parte del producto inicial. La cognición ejecuta la implementación — escribe el código del Botlet, lo registra en el Botler, lo deploya al ambiente correspondiente — pero la decisión de qué Botlets debe haber, qué tareas cubren y bajo qué contratos operan, es del equipo de diseño. Pattern Recognition no participa en la generación seed.
Botlets emergentes. Generados por Pattern Recognition cuando la cognición, durante operación, detecta un patrón repetitivo no anticipado por el diseño. La cognición evalúa si el patrón merece automatización, decide afirmativamente, y genera el Botlet. Es la modalidad que la sección anterior describió.
Ambos viven y operan idénticamente una vez generados — ambos están
sujetos al ciclo 95/4/1, ambos pasan por las fases junior →
en aprendizaje → senior, ambos tienen garantía de fallback, ambos son
auditables. La diferencia está en el origen.
Pattern Recognition no es la única vía a Botlet. El diseño tampoco es deuda técnica. Las dos vías coexisten.
La distinción tiene tres consecuencias prácticas.
Primera, un sistema agentivo productivo no requiere esperar a que Pattern Recognition descubra los Botlets críticos. Los Botlets seed se generan al inicio según la spec del producto, y el sistema entra en producción con la batería de Botlets necesaria para operar. Pattern Recognition entra después, durante la vida del sistema, para optimizar lo que el diseño no anticipó.
Segunda, los Botlets seed pueden vivir en cualquier capa, no solo en Capa 3. Las GUIs persistentes generadas como Botlets de fachada del Capítulo 4 §1 lo ilustran: el Botlet de fachada es un Botlet seed de Capa 3 que expone su superficie estable en Capa 1, y los Botlets de presentación que componen esa superficie (shells y vistas) son Botlets seed de Capa 1 — generados por la cognición a pedido del equipo de diseño porque el rol operativo (cajero, cocinero, operador de planta) lo justifica. La definición canónica del Botlet seed permite estas materializaciones sin que la spec las trate como excepciones.
Tercera, la trayectoria de madurez aplica igual a Botlets seed que a Botlets emergentes. Un Botlet seed recién deployado es junior; un Botlet seed que ya operó miles de veces y consolidó su saber del ambiente es senior. La distinción origen no cambia la trayectoria; solo el momento de inicio.
proto-Botlet — la pieza pre-forjada
La distinción seed vs emergente describe quién decide que un Botlet exista. Queda una pregunta anterior: cuando la cognición genera un Botlet seed, ¿escribe su código desde cero cada vez? En la práctica operativa, no. El código del Botlet rara vez nace de la nada: nace de una pieza pre-forjada que el agente configura.
Un proto-Botlet es una pieza pre-forjada de capacidad operativa que el agente, en su tiempo de Ingeniería, configura para instanciar un Botlet específico al caso. El proto-Botlet contiene el código; el Botlet es la instancia configurada. La relación es genérico → instancia: el proto-Botlet vive en un catálogo y sirve a muchos casos; el Botlet es uno de esos casos resuelto.

La conexión con el origen del Botlet es directa. Un Botlet seed que el equipo de diseño planificó no obliga a la cognición a escribir su lógica entera: si el catálogo tiene un proto-Botlet que cubre la función — cobro de cuenta, comanda contra impresora de tickets, una operación informativa —, la cognición instancia el Botlet configurando ese proto-Botlet en vez de generándolo. La decisión de existir sigue siendo del diseño (es seed); la materialización del código se apoya en la pieza pre-forjada.
La spec reconoce dos clases de proto-Botlet, según la naturaleza de su código:
| Clase | ¿Qué es su código? | ¿Cómo se configura? | Ejemplo anonimizado |
|---|---|---|---|
| Templado | Código específico de su función | Parametrización acotada | Cobro de una cuenta; comanda contra impresora de tickets |
| Platafórmico | Código genérico cuya especialización vive en una configuración composicional | Configuración composicional, que cubre N funciones del dominio | Una pieza de operación informativa que sirve reportes y dashboards de muchas formas |
Un proto-Botlet templado resuelve una función y la resuelve completa; configurarlo es ajustar parámetros dentro de un rango previsto. Un proto-Botlet platafórmico es un motor: su código es genérico y la función específica emerge de una configuración rica — composicional, no una lista plana de parámetros —, de modo que un solo proto-Botlet platafórmico cubre N funciones de su dominio. Mira, en el catálogo de la implementación de referencia, es un proto-Botlet platafórmico de operación informativa.
Distintas implementaciones mantienen catálogos de proto-Botlets — públicos en AgencyDomains.org, privados en códices propietarios. Y el grado en que el agente configura la pieza pre-forjada, co-escribe su código o lo genera entero define las generaciones del Botlet — la sección siguiente las fija.
Las generaciones del
Botlet — G1, G2, G3
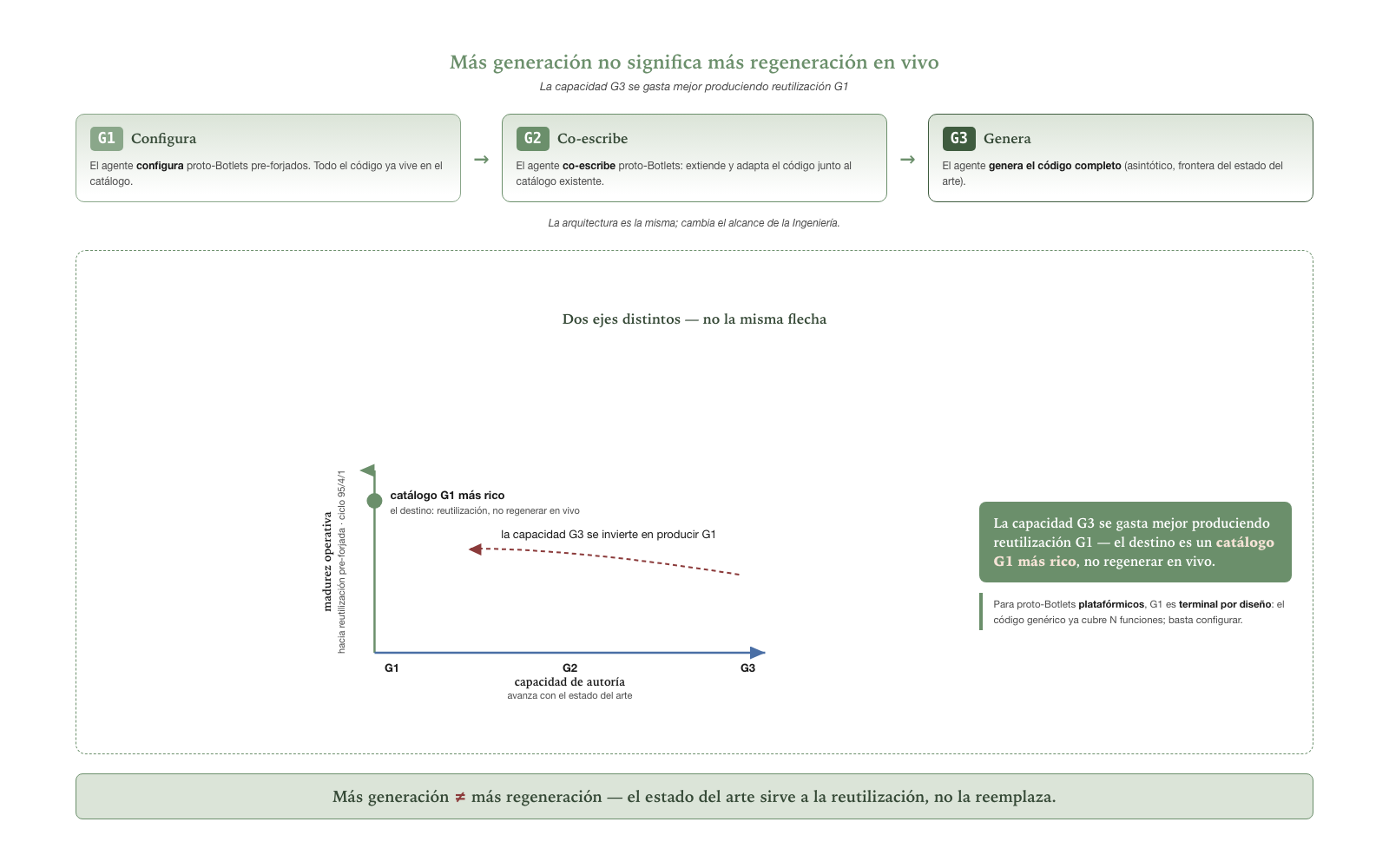
Las generaciones son el modelo evolutivo de cómo nace el código del Botlet conforme avanza el estado del arte de la cognición:
G1— el agente, en su tiempo de Ingeniería, configura proto-Botlets pre-forjados del catálogo. Si ninguno sirve, especifica uno nuevo para forjar en la próxima Preparación.G2— el agente co-escribe proto-Botlets con asistencia humana o de modelo. Parte del trabajo que enG1ocurría en Preparación migra a la Ingeniería.G3— el agente genera el código completo del Botlet en su tiempo de Ingeniería, sin pre-forjar nada. Escenario asintótico.
La arquitectura es la misma en las tres generaciones; lo que cambia
es el alcance de la Ingeniería que el agente realiza.
Una implementación puede operar en G1 hoy y migrar
incrementalmente hacia G3 conforme el estado del arte lo
permita, sin re-arquitectura.
Una generación más alta no es un destino. La frase
anterior — migrar hacia G3 — induce, leída sola, una
conclusión falsa: que G3 es el destino y G1
una estación de paso primitiva. El error nace de proyectar dos
ejes distintos sobre una sola flecha:
| ¿Qué eje? | ¿Qué mide? | ¿Dirección de “avance”? |
|---|---|---|
| Capacidad de autoría | Cuánto puede forjar el agente: configurar (G1) →
co-escribir (G2) → generar entero (G3) |
Hacia G3, conforme avanza el estado del arte de la
cognición |
| Madurez operativa | Para una operación recurrente, cuánto se reutiliza pre-forjado vs se
regenera cada vez (ciclo 95/4/1) |
Hacia la reutilización (G1), conforme el Botlet madura
junior → senior |
No son la misma flecha. Un agente con capacidad G3 que
regenera cada artefacto desde cero en cada ejecución no es avanzado:
tiene el músculo y elige re-aprender el movimiento cada vez. La
reconciliación es directa: la capacidad G3 se gasta mejor
produciendo reutilización G1. Las
generaciones describen lo que el agente puede autorar; el ciclo
95/4/1 describe lo que un agente maduro reutiliza.
El destino de la capacidad G3 es un catálogo
G1 más rico, no la regeneración en vivo de todo.
Hay un corolario para los proto-Botlets
platafórmicos. Para uno de ellos, G1 es
terminal por diseño, no estación de paso: su identidad
es código genérico más configuración. Un platafórmico “en
G3” — donde el agente regenera el motor por cada pieza — no
es una versión más avanzada; disuelve el proto-Botlet y colapsa de
vuelta al modo agéntico que la arquitectura existe para trascender.
G1 no es configuración pobre. Lo que
define G1 es que el agente no escribe el cuerpo del
proto-Botlet — pero la configuración que rellena puede ser tan rica como
un DSL composicional con expresiones formales evaluables.
La distinción G1/G3 es sobre autoría
del cuerpo del proto-Botlet, no sobre expresividad de la
configuración. Un proto-Botlet platafórmico con un DSL rico
es G1 puro.
Eso deja un caso frontera: configuración que admite expresiones
formales evaluables — SQL, especificaciones de gráfico,
expresiones de filtro. El filo
G1/G2 lo resuelve:
- Una expresión formal evaluable que es parámetro de una
Capability bien definida (
SQL→execute-sql, una especificación de gráfico →render-chart, una expresión de filtro →filter-stream) es configuración →G1. - Una expresión que extiende o sobreescribe la lógica interna
del proto-Botlet — callbacks, lambdas que el proto-Botlet
evalúa internamente, fragmentos que se concatenan a su cuerpo — es
código escrito por el agente →
G2.
El test es uno solo: “¿el código pertenece a la Capability
invocada o al proto-Botlet mismo?”. Si lo evalúa una Capability del
catálogo, G1; si lo evalúa el proto-Botlet en su lógica
interna, G2.
La implementación de referencia, Vergis, opera hoy en
G1: su catálogo expone proto-Botlets — Mira entre ellos —
que el agente especializa configurando, no regenerando (Capítulo 9). El
sentido profundo de las generaciones — por qué el agente avanzado genera
menos, no más — es el ensayo con que cierra el libro.
Garantía de fallback — la propiedad innegociable
La garantía de fallback merece tratamiento detallado porque es lo que hace al Botlet operacionalmente confiable en lugar de frágilmente automatizado. Una organización que depende de un Botlet para una operación crítica — procesar un batch nocturno, enviar reportes regulatorios, conciliar transacciones — debe poder confiar en que el Botlet va a ejecutarse o, en su defecto, alguien va a ejecutar la tarea por él. La garantía de fallback es lo que sostiene esa confianza.
Cuando un Botlet falla catastróficamente — no porque el ambiente cambió levemente y la cognición pueda regenerar el código, sino porque algo realmente impide la ejecución —, la cognición ejecuta la tarea manualmente. Manualmente en este contexto significa que el LLM hace el trabajo paso a paso, invocando los tools subyacentes que el Botlet usaría, pero sin la eficiencia del código compilado. El proceso es más lento y más costoso — la cognición consume tokens — pero el trabajo se hace. La organización no se queda detenida.
Esta garantía no es decorativa. Es lo que distingue al Botlet conforme a esta spec de cualquier “macro inteligente” o “automatización con IA” frágil. Las macros tradicionales fallan y dejan la operación detenida; los Botlets fallan y la cognición toma el relevo. La diferencia es estructural y se traduce directamente en disponibilidad operativa: una organización con Botlets correctamente diseñados puede prometer SLAs de operación que serían imposibles con automatización tradicional.
El Botlet no reemplaza a la cognición. La libera del trabajo repetitivo, pero queda como red de seguridad.
La cita anterior resume bien la relación entre las dos capas. La cognición no es residual — sigue siendo la inteligencia general que sostiene el sistema. El Botlet es eficiencia operativa que opera mientras el ambiente lo permite. Cuando el ambiente sale del rango, la cognición vuelve.
¿Cuándo usar Botlets, y cuándo no?
No todas las tareas se benefician de ser delegadas a Botlets. La spec define criterios claros para decidir cuándo conviene generar un Botlet y cuándo conviene mantener la tarea bajo cognición continua.
Conviene generar un Botlet cuando la tarea es repetitiva — más de diez invocaciones es regla práctica útil —, cuando el patrón es estable en su núcleo aunque el ambiente puede cambiar, cuando el proceso es crítico y debe ser rápido, cuando el costo de cognición por invocación es relevante a escala, y cuando hay tolerancia a regeneración esporádica del código sin que eso afecte la operación.
No conviene generar un Botlet cuando la tarea es única o de baja frecuencia, cuando el patrón es altamente variable y cada invocación requiere juicio fresco, cuando la tarea exige razonamiento profundo que un script no puede capturar, cuando es prototipo o exploración donde la flexibilidad importa más que la eficiencia, cuando el costo total es irrelevante y la cognición continua es práctica, o cuando los cambios en el ambiente son tan constantes que el Botlet se regeneraría todo el tiempo, perdiendo su beneficio. Hay un caso intermedio que merece nombre propio: la tarea recurrente en su forma pero interpretativa en cada instancia — el patrón es estable, pero cada ejecución exige juicio fresco que ningún código determinístico captura. Esa tarea no pertenece al Botlet ni a la cognición continua: pertenece al Agentlet, la primitiva hermana que el §7 de este capítulo formaliza.
La regla práctica que sintetiza estos criterios: si la tarea se ejecuta más de diez veces y su lógica es estable en su núcleo, conviene generar un Botlet. Por debajo de ese umbral, la cognición es más eficiente. Por encima, la diferencia económica empieza a ser material.
Una observación importante: la decisión de cuándo generar Botlet no la toma un humano. La toma la cognición misma, asistida por Pattern Recognition que detecta los patrones repetitivos. El humano define las reglas generales — qué tipos de tareas son candidatas, qué umbrales de frecuencia son relevantes, qué tipos de ambientes son sensibles —, pero la decisión específica en cada caso emerge del comportamiento del agente. Esta es propiedad del sistema agentivo: la decisión de optimización es propia del agente, no externa a él.
Manifestación y temporalidad del Botlet
Un Botlet es memoria muscular: una disposición latente, un saber-hacer almacenado que no es nada hasta que se ejerce. Cuando el Botlet se ejecuta, ese latente se actualiza en el mundo. Esa actualización es su manifestación: el paso de potencia a acto del Botlet, perceptible o no.
La palabra exige cuidado. Manifestación no es aparición. El término corriente sugiere “hacerse visible”, y eso dejaría fuera casos legítimos: un Botlet que dispara una ingestión periódica se manifiesta — actualiza su latente, produce un efecto — aunque no deje ningún artefacto visible. Por eso el canon la define como actualización del latente, no como aparición: el efecto invisible cuenta tanto como el artefacto a la vista.

La manifestación es el género abstracto; cada familia de Botlet la especializa, y cada práctica le pone su nombre cargado:
- familia de información → su manifestación deja un
Producto de Información (
PI), - familia de actuación → un efecto sobre el mundo, sin artefacto,
- familia de decisión → la nombra su propia práctica.
El PI no es primitiva del canon: es la
manifestación de una familia. El canon se queda en
manifestación; el Producto de Información es un
término normado de esta spec — no primitiva, pero sí
vocabulario con reglas —, y su carga de gobernabilidad se añade aquí sin
contaminar el nivel canónico. Esta es su descripción de referencia:
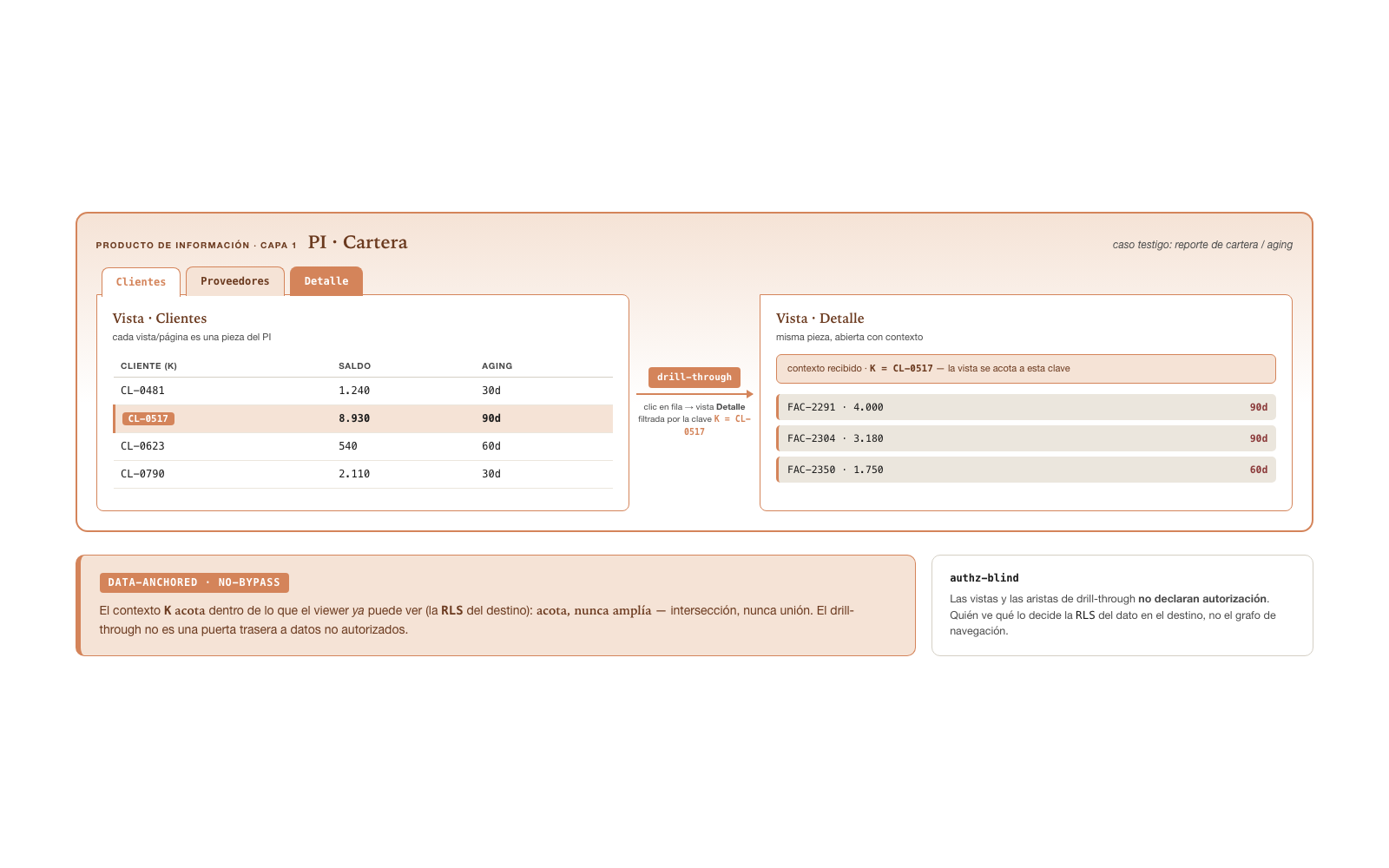
Producto de Información multi-vista · drill-through.
Un PI no es necesariamente una pieza única. Puede
componerse de N piezas nombradas: cada
vista es una pieza más del mismo PI,
elegible desde un selector, con una vista por defecto (la primera). El
PI es authz-blind — ni las vistas ni las
aristas que las conectan declaran autorización; esa política vive en el
policy store, no en la composición.
La conexión entre vistas es el drill-through: una
arista de navegación con contexto. Una tabla declara
“al clickear una fila, ir a la vista destino pasando la clave de esa
fila”; la vista destino se renderiza filtrada por esa
clave. La propiedad crítica es data-anchored /
no-bypass: el contexto que viaja con la arista acota
dentro de lo que el viewer ya puede ver — la vista destino
aplica su propia política de filas (RLS, row-level
security: la seguridad a nivel de fila) sobre la fuente, y el
contexto entra como filtro adicional, nunca como override de la política
(MUST). El drill acota, nunca amplía —
intersección con lo autorizado, jamás unión. Si el viewer no alcanza la
fila origen, no llega a la arista; si llega, el destino sigue gobernado
por su propia política.
Un reporte de cartera / aging de saldos ilustra el patrón: vistas
nombradas (Clientes, Proveedores, Relacionados, Detalle) sobre el mismo
PI, una tabla jerárquica Empresa→Socio, y una arista de
drill-through Socio→Detalle que abre los documentos de ese socio —
filtrados por la clave del socio y acotados a lo que el viewer ya tenía
derecho a ver. La composición multi-vista es ortogonal a la familia del
Botlet de operación: lo que cambia es cuántas piezas componen la
manifestación, no su naturaleza.
La temporalidad es el régimen de la manifestación. Es atributo declarado del Botlet, con dos valores:
| Temporalidad | ¿Cómo se manifiesta? | Relación con el runtime |
|---|---|---|
discreta |
En pulsos: despierta por schedule, trigger o evento, actúa, descansa | El Botler invoca o agenda; el Botlet no vive entre pulsos |
continua |
Sostenida: vive persistente y se manifiesta sin cesar | El Botler sostiene la ejecución mientras el Botlet viva |
temporalidad: continua equivale a la vida persistente de
Capa 3: obliga al Botler a sostener la ejecución del Botlet sin
re-arranque por cada manifestación. Un Botlet conforme con temporalidad
continua MUST poder ser sostenido por el runtime persistente; un Botlet
con temporalidad discreta se manifiesta vía schedule, trigger o
evento.
La consecuencia operativa es fuerte: el tiempo real no se
elige en un canal de entrega. No se obtiene marcando un canal
como push; se obtiene dándole al Botlet temporalidad
continua, lo que a su vez obliga al runtime persistente. El modo de
entrega es el síntoma; la temporalidad continua es la causa. Esto
reubica el “tiempo real” del nivel del canal al nivel del Botlet, y
conecta con la distinción Empresa en línea ≠ Empresa en tiempo
real: no son dos clases de información, sino dos puntos del
continuo de temporalidad.
De aquí se sigue una economía de runtime. Un reporte — snapshot en un punto del tiempo — y un dashboard vivo no son dos tipos distintos de qué: son la misma manifestación bajo distinta temporalidad. Por eso un único runtime los cubre: se construye el caso más difícil (continua) y los casos simples son configuraciones degeneradas de ese caso, no codepaths aparte. La distinción se sostiene precisamente porque la temporalidad es ortogonal a lo que se manifiesta.
Botler — el framework runner
Botler es la infraestructura que ejecuta los Lets — el nombre propio del género de las unidades empaquetadas de la Capa 3 (Autonomía): los Botlets que esta sección desarrolla y los Agentlets que el §7 formaliza como su especie hermana. Es invisible para el usuario y para el agente; es responsabilidad de la implementación del AgencyDomain. La relación canónica es simple y se enuncia sobre el género: un proceso del AgencyDomain contiene un Botler, y el Botler gestiona N Lets que viven dentro de ese proceso — 1 Proceso = 1 Botler + N Lets. En esta sección, donde los Lets son Botlets, la relación se instancia como 1 Botler + N Botlets.
El Botler provee cuatro funciones críticas. La primera es aislamiento de ejecución — sandboxing apropiado al ambiente, que detallamos en la próxima sección. La segunda es gestión del ciclo de vida del Botlet: invocación cuando se necesita, monitoreo durante ejecución, detección de fallos, disparar regeneración cuando corresponde. La tercera es comunicación con la cognición cuando el Botlet detecta un fallo o cambio en el ambiente que excede su capacidad de manejo. La cuarta es trazabilidad: cada invocación del Botlet, cada resultado, cada fallo, cada regeneración, queda registrado en el append-only log del Trust Layer. Esta trazabilidad es lo que permite reconstruir, auditablemente, qué hizo el agente y por qué — y es indispensable para gobernanza.
El Botler como abstracción importa porque desacopla la implementación de aislamiento del agente que lo usa. El agente no sabe — ni tiene por qué saber — si su Botlet corre en un contenedor Docker, en una sandbox WASM, o en una microVM. Solicita ejecución al Botler; el Botler ejecuta bajo el modelo de aislamiento que la implementación del AgencyDomain eligió. Esta separación es lo que permite que la spec sea agnóstica a tecnología de aislamiento — distintas implementaciones eligen distintas tecnologías según sus tradeoffs específicos.
El Botler es genérico por definición
El Botler no entiende el dominio de los Botlets que ejecuta. Gestiona el ciclo de vida, el aislamiento y la ejecución de cualquier Botlet sin saber qué hace ese Botlet ni a qué disciplina pertenece. Toda la especialización de dominio vive en los Botlets y en sus proto-Botlets, nunca en el runtime que los hospeda. La arquitectura es plana: un runtime genérico hospeda componentes especialistas autocontenidos.
De aquí se sigue una propiedad estructural: no existen subtipos de Botler por familia de operación. No hay un Botler “informativo”, uno “transaccional”, uno “para artefactos de información” — un Botlet de operación informativa ya carga su propia frescura, su caché, su distribución, de modo que un subtipo de Botler que lo duplicara contradiría la genericidad del runtime sin agregar nada.
Los subtipos de Botler se distinguen por topología y rol de despliegue — central, edge, fachada operativa para Botlets invocables desde Capa 1 —, nunca por dominio. La especialización de dominio vive íntegramente en los Botlets que el Botler ejecuta.
Los ejes de topología y rol son legítimos porque responden a dónde corre el runtime y con qué autonomía, no a qué dominio ejecuta: un Botler central y un Botler edge difieren en conectividad y operación offline, no en conocimiento de negocio. La nota normativa es la frontera: cualquier distinción de Botler que apele a la familia de operación que ejecuta está mal planteada.
El Botler valida orquestando, no ejecutando
El registro de un Botlet exige que su spec sea válida contra el tipo declarado antes de aceptarlo. Esto plantea una tensión aparente: si el Botler no entiende el dominio, ¿cómo valida una spec cuyo sentido es de dominio? La respuesta distingue orquestar la validación de ejecutarla.
El Botler hace valer la validación; no la ejecuta con conocimiento de dominio. En el momento del registro invoca el punto de validación que el propio Botlet provee — o que provee su proto-Botlet en G1 —, le entrega el contexto genérico que sí controla (el catálogo de Capabilities disponibles, la identidad, las políticas del AgencyDomain) y actúa sobre el veredicto: acepta, rechaza, o registra el resultado en el append-only log. El juicio de qué hace válida a la spec vive enteramente en el Botlet; el Botler decide admitir o no según un veredicto que no produjo. Así, ninguna spec inválida entra — el rechazo ocurre antes de admitir el Botlet y queda trazado — sin que el runtime interprete jamás el dominio.
Este patrón tiene un hermano en la invocación de Capabilities. El Botler es el único punto por el cual un Botlet invoca Capabilities, y el bypass por canales paralelos no se prohíbe solo por política: se hace estructuralmente imposible. En cada invocación el Botler entrega al Botlet un handle controlado — un objeto con acceso a Capabilities y al log ligado al propio Botler — en vez de permitir que el Botlet construya accesos por su cuenta. El Botlet solo puede actuar sobre el mundo a través de ese handle. Ambos casos comparten el principio: el Botler genérico expone puntos de control y el especialista se enchufa en ellos; el runtime se mantiene delgado sin renunciar a las garantías que el contrato exige.
La interfaz Capa 2 ↔︎ Capa 3
vía MCP
El Botler es el único punto de ejecución de los Botlets, y eso
incluye la operación que la propia Cognición dirige: la
Cognición (el agente LLM, Capa 2) comanda
al Botler (runtime de Capa 3, sin agencia) por una interfaz
interna cuyo transporte natural es MCP —
el Botler expone servidores MCP y la Cognición es el
cliente. Esta interfaz no es A2A; la
corrección formal de la nomenclatura A2A y la interfaz Capa
2 ↔︎ Capa 3 se desarrollan en el Capítulo 5 §1.
Código
fuente vs spec · dos superficies · un Botlet por PI
La operación de un Botlet involucra dos cosas que conviene no confundir. Una es el código fuente del Botlet: su implementación. Para un proto-Botlet platafórmico, ese código fuente es el motor, compartido por todos los Botlets que de él se instancian. La otra es la spec: lo que especializa el comportamiento del Botlet a su instancia. La spec no es el código; lo configura.
Esa separación se proyecta en dos superficies de gestión:
| Superficie | ¿Qué gestiona? | Granularidad | Cadencia |
|---|---|---|---|
| Ciclo de vida del código fuente | Instalar, versionar, cargar y descargar el motor | Nivel-Botler | Releases (Producto) |
| Operación | Especializar, manifestar, consumir y controlar cada Botlet | Por-Botlet | Fluida (Instancia) |
La operación incluye configurar el spec. Para un
proto-Botlet platafórmico, el spec es el input operacional: no hay
“operar” sin spec. De ahí un principio: configurar el spec es
operar. El agente evoluciona el spec operando — verbo
specialize —, de forma fluida; la cristalización del spec a
un registro versionado sigue, no precede, y la
proveniencia la da el append-log. Los verbos del API de operación son
specialize, invoke y schedule
(para temporalidad discreta), read y subscribe
(para temporalidad continua), y status,
activate, deactivate, retire.
De esto se desprende la regla de granularidad: un Botlet por
PI sobre un motor compartido. Cada Producto de
Información es su propio Botlet — su propio servicio, con identidad,
temporalidad, madurez y fallback propios —, especializado del motor
compartido (el proto-Botlet platafórmico). No es un Botlet con N
configuraciones, que perdería esa independencia; no son N programas,
porque el motor es uno. Es la relación
1 Proceso = 1 Botler + N Botlets, con los Botlets como
instancias especializadas del mismo proto-Botlet. El rationale es
RISC: muchos Botlets simples y focalizados — uno por
PI — componen mejor que un monolito.
El consumo subscribe es el puente al norte
agentivo. Hoy lo consume un humano — un navegador suscrito por
SSE que recibe la corriente de manifestaciones de un Botlet
continuo —; mañana lo consume la Cognición, alimentándose de esa misma
corriente para decidir. La temporalidad continua, el runtime persistente
y el verbo subscribe son, juntos, la infraestructura de ese
norte.
Modelo de aislamiento — sandboxing
Los Botlets son código generado dinámicamente por un agente. Esto exige aislamiento estricto. Un Botlet mal escrito, o un Botlet generado por un agente que fue víctima de prompt injection, podría intentar acciones maliciosas — exfiltrar datos, modificar archivos del sistema, abrir conexiones de red no autorizadas. El aislamiento es lo que contiene esos riesgos.
La spec admite cuatro estrategias de sandboxing, con sus trade-offs:
Procesos con seccomp ofrecen aislamiento bajo y overhead mínimo. Es estrategia útil solo en ambientes controlados donde el riesgo de código malicioso es bajo — por ejemplo, Botlets ejecutándose dentro del perímetro privado de una organización con confianza implícita en sus propios agentes. No es estrategia adecuada para Botlets que tocan datos sensibles o que operan bajo régimen público.
Contenedores — Docker, Podman, equivalentes — ofrecen aislamiento medio-alto con overhead medio. Es la estrategia más práctica para Botlets genéricos que necesitan invocar tools del sistema operativo o redes. Los contenedores tienen ecosistema maduro, portabilidad razonable, herramientas operacionales abundantes. Son default razonable para la mayoría de los casos.
WASM (WebAssembly) ofrece aislamiento alto con overhead bajo, pero el ecosistema es más limitado. WASM es ideal para Botlets transformacionales puros — cálculos, transformaciones de datos, lógica algorítmica — que no necesitan acceso al sistema operativo subyacente. La velocidad de inicio es muy rápida (milisegundos), lo que importa cuando un agente necesita invocar muchos Botlets simultáneamente.
MicroVMs — Firecracker, Kata Containers — ofrecen aislamiento máximo con overhead alto. Son adecuadas para Botlets que manejan datos altamente sensibles o que operan en ambientes multi-tenant compartidos donde el riesgo de cross-tenant leakage es inaceptable. El overhead típicamente significa decenas de milisegundos de inicio adicional, que en algunos casos es prohibitivo.
La recomendación canónica para implementaciones de referencia es híbrida: WASM para transformers puros (sin acceso al sistema), contenedores para Botlets genéricos que necesitan invocar tools del sistema operativo, MicroVMs para Botlets que manejan datos altamente sensibles o que operan en entornos multi-tenant compartidos. La elección específica para cada Botlet depende de su perfil de riesgo y de sus requisitos de performance.
Lenguaje de los Botlets
La spec es agnóstica al lenguaje de implementación de los Botlets. La cognición puede generar Botlets en cualquier lenguaje siempre que el Botler los pueda ejecutar dentro del sandbox elegido. Esta agnosticidad importa porque el panorama de lenguajes evoluciona — un sistema atado a un lenguaje específico puede quedar obsoleto cuando ese lenguaje pierde tracción en el ecosistema de IA.
Las recomendaciones prácticas para implementaciones de referencia son:
Python es primera elección. La madurez del ecosistema, las librerías para casi cualquier integración, la generación por LLM altamente confiable — los modelos contemporáneos generan Python correctamente con frecuencia muy alta —, hacen de Python el default razonable para Botlets genéricos.
JavaScript / TypeScript son adecuados para Botlets que tocan APIs HTTP o que automatizan browsers. El ecosistema npm tiene cobertura amplia, y la generación por LLM también es confiable.
Bash o shell son adecuados para Botlets que orquestan comandos del sistema operativo. La generación de bash por LLM es confiable para casos simples, menos confiable para casos complejos donde la sintaxis de bash tiene quirks.
Rust o Go — lenguajes compilados — son adecuados para Botlets de muy alta frecuencia donde el overhead del intérprete importa. La generación por LLM es menos confiable que Python, pero los Botlets resultantes ejecutan más rápido. Esta combinación tiene sentido cuando un Botlet va a ejecutarse millones de veces y la diferencia de milisegundos por invocación se acumula a impacto material.
Hay una propiedad importante: el Botlet no es editable por humanos. Es regenerado por la cognición. Esto importa porque cualquier mejora manual al código del Botlet — un humano que abre el archivo y mejora la lógica — se convierte en deuda en el momento que la cognición lo regenere por cambio de ambiente. La regeneración elimina las mejoras humanas. Por eso la spec define que los Botlets son read-only para humanos en producción: si un humano quiere mejorar la lógica, debe mejorar la cognición o las Capabilities, no el Botlet directamente.
Pattern Recognition — la entrada al ciclo

Los Botlets no se generan al azar. La cognición decide generar un Botlet cuando reconoce un patrón repetitivo en la actividad del agente. El componente que detecta esos patrones es Pattern Recognition — primitiva auxiliar de la Capa 2 que ya mencionamos en el Capítulo 4.
Pattern Recognition opera sobre la traza de actividad del agente: qué tareas hizo, con qué frecuencia, con qué entradas similares, con qué resultados. Cuando un patrón cruza un umbral — la misma tarea repetida más de N veces con variabilidad acotada en sus entradas, los resultados estables —, la cognición evalúa si vale la pena generar un Botlet.
La inspiración neurobiológica que mencionamos al inicio se refleja en el diseño del Pattern Recognition. La corteza perirrinal del cerebro humano implementa familiaridad rápida — el “¿he visto esto antes?” que ocurre en milisegundos, sin recollection consciente. El Pattern Recognition agentivo implementa lo análogo: detección rápida de tareas similares a tareas pasadas, sin necesidad de razonamiento profundo. Si la respuesta es sí, el sistema activa el siguiente nivel.
El hipocampo implementa recollection: el “¿qué hice exactamente la última vez?”. El Pattern Recognition recupera la traza específica de las invocaciones pasadas, con sus parámetros, sus resultados, sus duraciones. Esta información es lo que la cognición usa para decidir si generar Botlet vale la pena.
La corteza prefrontal implementa decisión consciente: el “¿debo automatizar esto?”. Aquí la cognición evalúa los criterios — frecuencia, estabilidad del patrón, costo de cognición continua, riesgo de regeneración — y decide. Si decide sí, dispara la generación del Botlet.
Tres etapas, tres niveles de procesamiento. Pattern Recognition no es un solo paso — es un proceso jerárquico que filtra desde “potencialmente interesante” hasta “vale la pena automatizar”. La especificación de Pattern Recognition como tool de Capa 2 está fuera del alcance de este libro; basta retener que es la primitiva auxiliar que activa el ciclo del Botlet.
Botlets y la economía de la autonomía bajo suscripción

Una propiedad operativa crítica del Botlet, que ya introdujimos en el Capítulo 4 §2 pero que merece desarrollo aquí, es su rol en la economía de la autonomía bajo planes de Suscripción fija — Claude Pro, ChatGPT Plus, Copilot empresa.
En estos planes, el costo marginal de invocar la cognición es cero hasta el límite del plan. El usuario paga una mensualidad fija y puede invocar el modelo cuantas veces quiera, hasta que el plan agota su cuota. Esta estructura económica es muy distinta de los modelos de pago por token, donde cada invocación cuesta y la economía se calcula por uso real.
El problema es que el límite existe. Un Agente Autónomo operando continuamente en background, sin Botlets, invocaría la cognición miles de veces al día — cada decisión, cada validación, cada acción consultaría al modelo. Bajo plan de Suscripción fija, el agente agotaría la cuota del usuario en horas. La autonomía continua sería económicamente imposible.
Los Botlets son el mecanismo arquitectónico para extender autonomía sin saturar el plan. Un agente que ejecuta su trabajo cotidiano vía Botlets — y solo invoca la cognición cuando el ambiente cambia — puede operar en background continuo sin agotar la cuota del usuario. La cognición queda disponible para razonamiento real, no para tareas repetitivas que el código tradicional ejecuta mejor.
Sin Botlets, la autonomía sostenida bajo Suscripción fija es económicamente imposible.
Esto es lo que hace al Botlet palanca económica, no solo optimización técnica. La diferencia entre un agente que cuesta doscientos dólares por mes operar y uno que cuesta veinte dólares por mes operar, con capacidad efectiva idéntica, es casi siempre la proporción de tareas que ejecuta vía Botlets versus vía cognición continua. Una organización que adopta Botlets disciplinadamente puede operar agentes a un orden de magnitud menos costo que una organización que invoca cognición para cada operación.
La consecuencia comercial es directa: los proveedores que entregan agentes con buenos Botlets pueden ofrecer pricing competitivo y márgenes razonables; los proveedores que dependen de cognición continua para cada operación enfrentan un dilema económico — o suben pricing a niveles que el mercado no acepta, o operan con márgenes negativos. Esta presión es probablemente lo que llevará a la mayoría de los proveedores serios a adoptar arquitecturas con Botlets en los próximos dos a tres años.
Cadena de derivación y catálogo de proto-Botlets
Los Botlets de un sistema no aparecen sueltos: se derivan de lo que el sistema necesita hacer, y se apoyan en piezas pre-forjadas del catálogo. La spec fija esa cadena de derivación como relación estructural:
- Casos de uso documentados — cada caso requiere…
- Botlets necesarios (cero, uno o varios; algunos casos los resuelve la cognición sin Botlet) — cada Botlet es instancia de…
- proto-Botlets requeridos del catálogo.
La cadena es estructural, no metodológica. Un caso de uso puede no requerir Botlet alguno — la cognición lo resuelve directamente —, requerir uno, o requerir varios; cada Botlet que sí existe es instancia de algún proto-Botlet del catálogo. De aquí una propiedad exigida: todo Botlet conforme MUST poder trazarse en esta cadena, y el append-only log MUST registrar el proto-Botlet de origen de cada Botlet instanciado. El método por el cual se descubren los casos de uso y se derivan los Botlets no entra al canon — es uno de varios posibles y vive en los cuerpos complementarios de cada implementador; lo que el canon fija es la relación y su trazabilidad.
El extremo inferior de la cadena — los proto-Botlets — se acumula en catálogos comunes que producen efectos de red. Cada implementador que consume un proto-Botlet contribuye a su maduración: variantes nuevas, configuraciones probadas, refinamientos. Mientras más implementadores lo consumen, más casos cubre y más confiable se vuelve; el implementador n+1 recibe versiones refinadas por los implementadores 1 a n. Un proto-Botlet pertenece a una comunidad de catálogo bajo alguno de estos modos:
| Modo de pertenencia | ¿Qué es? |
|---|---|
| Contrato privado | Catálogo cerrado entre cliente y proveedor |
| Códice propietario | Catálogo privado que un implementador cura (ucodex es un ejemplar) |
| Catálogo público abierto | AgencyDomains.org: cualquier implementador consume y contribuye |
| Acuerdo soberano | AgencyDomains que adoptan estándares comunes sin contrato comercial directo |
Los modos coexisten sin tensión: un mismo implementador puede consumir el catálogo público abierto y, sobre él, curar un códice propietario con sus refinamientos por casos reales. La cadena de derivación y el catálogo común son, juntos, lo que hace de los proto-Botlets una economía y no una colección de piezas aisladas.
Conformidad
Una implementación de Botlet conforme a esta especificación debe satisfacer los siguientes requisitos:
| Requisito | Nivel |
|---|---|
| Código generado por la cognición, no escrito por humanos | MUST |
| Ejecución sin invocar cognición en operación normal | MUST |
| Garantía de fallback a cognición manual ante fallo | MUST |
| Trazabilidad: cada invocación queda en append-only log | MUST |
| Aislamiento adecuado al ambiente | MUST |
| Regeneración automática ante cambio de ambiente | SHOULD |
| Pattern Recognition como activador de generación | SHOULD |
| Lenguaje agnóstico (no atar a un solo lenguaje) | MUST |
| Reconocimiento de fases de madurez (junior, en aprendizaje, senior) | SHOULD |
| Distinción entre origen seed y origen emergente | SHOULD |
| Trazabilidad de trayectoria de madurez en append-only log | MUST |
| Botlet trazable en la cadena casos-uso → Botlet → proto-Botlet | MUST |
| proto-Botlet de origen de cada Botlet registrado en append-only log | MUST |
| Botler genérico: sin subtipos de Botler por dominio | MUST |
| Botler hace valer la validación de spec sin ejecutarla con dominio | MUST |
Soporte de las dos temporalidades (discreta y
continua) |
MUST |
| Runtime persistente que sostiene Botlets de temporalidad continua | MUST |
Capabilities
Cuando un consultor experimentado de finanzas se enfrenta a un problema nuevo en un cliente, no parte de cero. Trae consigo un cuerpo de saber-hacer organizado que aplica al caso particular: principios contables, marcos regulatorios, frameworks de análisis, prácticas profesionales que la industria ha consolidado durante décadas. Cuando un consultor de operaciones aborda un problema de cadena de suministro, hace lo mismo con su propio cuerpo de saber: SCOR, Six Sigma, lean manufacturing, planificación de demanda. Cada disciplina profesional tiene su árbol de saber-hacer, y la calidad del consultor depende en buena parte de cuán profundo y bien organizado está ese árbol en su cabeza.
Los agentes de IA enfrentan el mismo problema. Un agente que opera en finanzas necesita saber finanzas; un agente que opera en legal necesita saber legal; un agente que opera en marketing necesita saber marketing. Pero “saber” en este contexto no significa simplemente que el modelo subyacente haya leído documentación de finanzas durante el entrenamiento. Significa que el agente tiene acceso, modular y composable, a un cuerpo organizado de saber-hacer profesional que puede aplicar selectivamente según la tarea. Esta organización es lo que la Arquitectura Agentiva llama Capabilities.
Esta sección desarrolla el concepto de Capability como primitiva canónica de la Capa 2 (Cognición). Lo que hace especial a la Capability respecto a otros conceptos cercanos del campo es su estructura jerárquica, su composabilidad, y su distinción explícita de plugins y prompts. Un agente sin Capabilities tiene cognición monolítica que confunde dominios; un agente con Capabilities bien organizadas opera con la disciplina de un profesional que conoce las distinciones de su campo.
Definición
Una Capability es una unidad de saber-hacer especializado que un agente comprende y aplica. Encapsula el conocimiento procedimental y declarativo de un dominio: qué se sabe, cómo se aplica, qué se decide, qué se pregunta cuando faltan datos. Las Capabilities residen en la Capa 2 (Cognición) de la Arquitectura Agentiva. La cognición selecciona y aplica Capabilities según la tarea — del mismo modo en que un consultor experto selecciona y aplica frameworks profesionales según el problema que tiene enfrente.
El agente no sabe lo que el modelo sabe. Sabe lo que sus Capabilities le permiten saber.
La cita anterior distingue lo que la Capa 2 sabe de lo que el modelo subyacente conoce. El modelo subyacente — Claude, GPT, Gemini — fue entrenado con una cantidad masiva de información que incluye, entre muchas otras cosas, conocimiento profesional. Pero el agente que vive en la Capa 2 no opera directamente con el conocimiento del modelo. Opera con las Capabilities que le fueron asignadas, que son curaciones específicas de saber-hacer aplicado a contextos particulares. Un agente que tiene la Capability de General Ledger pero no la Capability de Tax responde con autoridad sobre contabilidad general pero sabe que no es la fuente correcta para preguntas de impuestos. Un agente sin Capabilities específicas opera con el conocimiento difuso del modelo, que puede ser correcto en general pero rara vez es preciso en lo profesional.
¿Qué NO es una Capability?
Para fijar la definición con la precisión que la spec exige, contrastamos la Capability con conceptos vecinos que la industria usa con descuido. Cada uno de estos conceptos vecinos tiene su rol legítimo en sistemas de IA, pero ninguno es Capability, y confundirlos lleva a arquitecturas que terminan siendo collages mal integrados.
El término Capability queda reservado, en sentido estricto, al saber-hacer cognitivo de la Capa 2 (Cognición): saber que interpreta, decide y razona sobre un dominio. Esta reserva importa porque otros entregables agentivos —conexiones a sistemas fuente, confecciones de presentación— viven en otras capas, tienen naturaleza distinta y se construyen con esquemas de desarrollo propios. Tratarlos a todos como Capabilities obligaría a apellidar el término en cada uso y diluiría su valor. La sección Capability, Conector y Plantilla — tres entregables por capa fija los términos propios de cada capa.
Un plugin vive en el contexto de una aplicación host. Extiende esa aplicación con una función nueva. Está atado al host: el plugin de Excel solo opera dentro de Excel, el plugin de Notion solo opera dentro de Notion. Una Capability no está atada a un host — vive en el árbol de Capabilities del agente y es invocable desde cualquier contexto donde el agente opere.
Un prompt es una formulación lingüística específica que se inyecta al modelo en una invocación particular. Los prompts son útiles, pero son artefacto transitorio: cambian de invocación a invocación, no codifican saber persistente. La Capability puede usar prompts internamente como uno de sus mecanismos de implementación, pero no se reduce a un prompt. Una Capability bien diseñada incluye vocabulario, conocimiento procedimental, conocimiento declarativo, heurísticas y referencias a tools — el prompt es solo uno de los componentes.
Un system prompt establece tono y comportamiento general del modelo. Es configuración del modo de operación, no saber-hacer modular. Las Capabilities no son system prompts — pueden coexistir con uno, pero capturan otra cosa: conocimiento del dominio aplicable según la tarea, no configuración global del agente.
Un tool vive en la Capa 4 (Acceso). Es acción ejecutable sobre el mundo externo: invocar una API, leer un archivo, enviar un email. La Capability decide qué tool invocar y cómo interpretar su resultado, pero no es el tool mismo. La Capability es saber; el tool es acción. Un agente financiero con la Capability de Treasury sabe cuándo y cómo invocar el tool que consulta los saldos bancarios — pero el tool en sí es componente separado que vive en otra capa.
Un skill, en la terminología popular del campo, es término que la industria usa con tanto descuido que prácticamente ha perdido sentido. Diversos proveedores llaman “skills” a plugins, a prompts, a tools, a configuraciones — sin distinción precisa. La Capability no es skill en el sentido genérico, pero la coincidencia parcial de uso popular puede confundir al lector. Para evitar la confusión, este libro reserva el término Capability con definición precisa y evita usar “skill” salvo en cita textual de fuentes que lo usan.
Tres rasgos distinguen a una Capability genuina. Modular: puede activarse o desactivarse independientemente de las demás. Si un agente tiene Capabilities de Finance y Legal y se le retira Legal, el agente sigue operando coherentemente con Finance solamente. Composable: múltiples Capabilities pueden coexistir en un mismo agente y combinarse cuando la tarea cruza dominios. Un agente que tiene Finance y Operations puede manejar un caso de logística que tiene componentes financieros sin tropezarse en la transición. Saber, no acción: la Capability sabe; los tools (Capa 4) actúan. La Capability decide qué tool invocar y cómo interpretar su resultado.
Capability, Conector y Plantilla — tres entregables por capa
Un proyecto agentivo de entrega rara vez entrega solo una Capability. La Capability cognitiva es la protagonista, pero suele venir acompañada de entregables que viven en otras capas y se construyen con esquemas distintos. La spec canoniza tres términos, uno por capa, para que cada entregable se nombre por lo que es sin apellidar el término Capability.

Una Capability (sentido estricto) es saber-hacer cognitivo, interpretativo, decisional. Vive en la Capa 2 · Cognición. Es la protagonista del proyecto.
Un Conector es saber acceder a sistemas fuente — conexión con poder de ejecución. No es saber cognitivo. Vive en la Capa 4 · Acceso. El Conector es lo que el campo pre-agentivo conoce como la integración técnica que toca el mundo externo. Una API legacy, al traerse al Mundo Agentivo, se convierte en Conector (Capa 4), no en Capability.
Una Plantilla es la confección específica del cliente sobre un instrumento canónico — un reporte o dashboard que la Capability produce — en un formato o regla particular exigido por el cliente. Vive en la Capa 1 · Interacción, junto a la Faceta, el Botlet de superficie y el Botlet de vista. Ejemplos anonimizados: una plantilla regulatoria de oferta básica de interconexión sobre el reporte canónico de costos; un formato de cierre financiero mensual gerencial sobre el dashboard canónico de rentabilidad. La Plantilla no es Capability, no es Faceta y no es Botlet: el comprador ya conoce el término “plantilla” del vocabulario pre-agéntico y no necesita aprender uno nuevo.
¿Cómo se desarrolla cada entregable?
Cada término tiene su capa, su naturaleza y su esquema de desarrollo propio:
| Entregable | Capa | Naturaleza | Esquema de desarrollo |
|---|---|---|---|
| Capability (protagonista) | Capa 2 · Cognición | Saber-hacer cognitivo, interpretativo, decisional | Wingtraining 5 pasos (workshop SME · creación · personalización · ALFA · BETA) |
| Conector (compañero, si requiere acceso a sistemas fuente) | Capa 4 · Acceso | Saber acceder a sistemas; no es saber cognitivo | Esquema de integración (relevar · configurar · probar · certificar) |
| Plantilla (compañero, si la entrega debe conformar a una expectativa de presentación) | Capa 1 · Interacción | Confección de un instrumento canónico en un formato o regla del cliente | Esquema de confección (relevar expectativa · confeccionar sobre instrumento canónico · validar) |
El Wingtraining, citado en la tabla, es el esquema canónico de desarrollo de una Capability en cinco pasos: workshop con el SME (subject-matter expert — el experto humano cuyo saber se transfiere al agente), creación, personalización, ALFA (validación con el SME) y BETA (validación en operación real). Su desarrollo pertenece a la práctica de entrega, no a este canon; el test de clasificación de más abajo lo usa como criterio porque es la prueba operativa de que un alcance es transferencia de saber — y no integración ni formato.
¿Cuál es la estructura conceptual de un proyecto agentivo de entrega?
Un proyecto agentivo de entrega se estructura como una Capability protagonista (Capa 2) acompañada típicamente de uno o más Conectores (Capa 4) y una o más Plantillas (Capa 1). Además, la propia Capability produce sin esfuerzo adicional sus instrumentos de información — reportes y dashboards canónicos —, que quedan implícitos en la entrega: no requieren esquema de desarrollo propio porque emergen de la Capability y su capa de interacción. La Plantilla aparece solo cuando uno de esos instrumentos debe conformar a una forma específica del cliente.
¿Capability o entregable de otra capa? — el test
Para decidir si un alcance es Capability en sentido estricto, los tres tests siguientes deben ser sí:
- ¿Es saber-hacer cognitivo? ¿Interpreta, decide o razona sobre un dominio — más allá de solo conectar o solo formatear?
- ¿Tiene un SME identificable? ¿Hay un humano experto cuyo saber se transfiere al agente?
- ¿Pasa por los cinco pasos de Wingtraining sin forzar? ¿Tiene sentido aplicarle workshop SME · creación · personalización · ALFA · BETA?
Si uno o más son no, el alcance no es Capability: pertenece a otra capa — Conector o Plantilla, según el mapeo de la sección Capability, Conector y Plantilla — o, si es saber cognitivo pero subordinado a una Capability mayor, es feature de esa Capability (ver la sección siguiente).
La estructura jerárquica — el árbol del saber

Las Capabilities se organizan en un árbol jerárquico. La estructura no es decoración — es la forma natural en que el conocimiento profesional está organizado en cualquier disciplina seria. Los analistas financieros piensan jerárquicamente: las finanzas tienen sub-disciplinas (contabilidad, corporate finance, treasury, tax), cada sub-disciplina tiene áreas (general ledger, cuentas por pagar, reconciliación), cada área tiene prácticas específicas. La organización jerárquica refleja cómo el profesional domina el campo.
A continuación un ejemplo del árbol canónico que la spec propone como punto de partida. El árbol no es exhaustivo — se extiende según las necesidades de cada implementación —, pero ilustra la estructura (figura arriba).
Cuatro reglas estructurales gobiernan el árbol. La primera: cualquier nodo es una Capability válida. Tanto los nodos hoja — Reconciliación, Demand generation, Calidad — como los nodos intermedios — Contabilidad, Sales & Marketing, Manufacturing — son Capabilities válidas. La granularidad la decide el contexto. Un agente especializado en operación contable diaria adopta nodos hoja con alta especificidad; un agente orquestador que coordina varios especialistas adopta nodos intermedios con visión panorámica; un agente multiespecialista combina varias raíces.
La segunda regla: es composable. Capabilities pueden compartirse entre agentes. Una Capability Customer success puede vivir en el agente de un equipo comercial y simultáneamente en el agente de un equipo de soporte, sin duplicación. Esto es crítico operativamente — la organización no necesita re-construir el saber para cada agente nuevo, sino que asigna Capabilities ya construidas según el rol del agente.
La tercera regla: es escalable. Se agregan ramas nuevas sin romper las existentes. La Capability Telecom puede subir en sofisticación — agregar sub-ramas Network APIs, 5G core, Customer experience — sin que las otras ramas del árbol cambien. Esta propiedad es lo que permite que el árbol crezca con la organización: cada vez que la organización entra en un dominio nuevo, agrega ramas; cada vez que profundiza en un dominio existente, extiende ramas. El árbol nunca necesita reescritura completa.
La cuarta regla: es heredable. Una Capability hereda contexto y vocabulario de sus ancestros. Una Capability General Ledger no necesita re-explicar lo que es Contabilidad ni Finanzas — esa contextualización viene del árbol. Esto importa en la implementación porque permite que las Capabilities hojas sean más concisas: solo necesitan describir lo que es específico de su nodo, no lo que ya está implícito en el camino del árbol.
Anatomía de una Capability
La especificación canónica de una Capability incluye nueve componentes que desplegamos uno por uno. Los componentes uno y nueve son metadata; los componentes dos a siete son el cuerpo del saber-hacer; el componente ocho es el binding con la capa de acción.
El primer componente es identidad: nombre canónico más posición en el árbol. La identidad es lo que hace que la Capability sea referenciable — los agentes la invocan por nombre, las políticas se aplican a Capabilities específicas, los logs registran qué Capability se invocó.
El segundo componente es vocabulario: términos técnicos del dominio que el agente debe reconocer y usar correctamente. Un agente con Capability General Ledger debe distinguir débito de crédito sin titubeos, debe conocer la diferencia entre asientos manuales y automáticos, debe usar correctamente el concepto de período fiscal. El vocabulario es lo que permite al agente conversar con profesionales del dominio sin sonar amateur.
El tercer componente es el conocimiento procedimental: cómo se hacen las tareas típicas del dominio. Cómo se reconcilia una cuenta. Cómo se valida una factura. Cómo se prepara un cierre mensual. El conocimiento procedimental es secuencial y operativo — describe pasos, no solo conceptos.
El cuarto componente es el conocimiento declarativo: hechos y reglas verificables del dominio. Que las cuentas por pagar tienen vencimientos. Que los ingresos se reconocen cuando se cumplen ciertos criterios. Que la conciliación bancaria debe ocurrir mensualmente. El conocimiento declarativo es factual y permanente — describe qué es verdadero del dominio.
El quinto componente son las heurísticas: reglas de decisión profesionales del dominio. Cuando una factura se desvía más del cinco por ciento del monto típico, escalar. Cuando una conciliación tiene más de diez transacciones sin hacer match, suspender el proceso y escalar. Cuando un proveedor tiene tres reclamos en seis meses, marcar para revisión. Las heurísticas son juicio profesional codificado — capturan no qué es verdadero del dominio, sino qué decisión tomaría un profesional en cada situación.
El sexto componente son las tools asociadas: tools de Capa 4 que la Capability invoca típicamente. La Capability General Ledger invoca tools que consultan la base de datos contable, que ejecutan asientos, que generan reportes. La Capability declara qué tools usa para que el agente sepa qué necesita disponible cuando ejerce esa Capability.
El séptimo componente son las Capabilities padres: posición jerárquica de la cual la Capability hereda contexto. Una Capability General Ledger declara que es hija de Contabilidad, que a su vez es hija de Finance. La declaración de los padres es lo que permite la herencia descrita en la sección anterior.
El octavo componente es el estado de madurez: Borrador / Vigente / Deprecado. El estado de madurez es metadata operacional — permite que la organización gestione el ciclo de vida de sus Capabilities. Una Capability en Borrador todavía se está validando; una Vigente está aprobada para uso productivo; una Deprecada es legacy que se mantiene por compatibilidad pero no debe usarse en agentes nuevos.
El noveno componente es versión: trazabilidad de evolución. Las Capabilities cambian con el tiempo — las prácticas profesionales evolucionan, las regulaciones cambian, el saber acumulado se refina. Las versiones permiten que la organización rastree la evolución del saber y que distintos agentes puedan operar con versiones distintas según sus requisitos.
Los componentes dos a cinco — vocabulario, procedimental, declarativo, heurísticas — son lo que diferencia profundamente una Capability bien construida de un prompt elaborado. Un prompt da contexto al modelo de manera transitoria, una sola conversación. Una Capability codifica saber profesional con persistencia y modularidad. La diferencia es estructural: el agente puede consultar la Capability General Ledger sin que el saber contable inunde todas sus otras conversaciones — puede tener al mismo tiempo la Capability Marketing sin que los frameworks de marketing contaminen el rigor contable. Esta separación es lo que permite a los agentes operar con la disciplina del profesional que cambia de marcos según la tarea.
Features de una Capability
Una Capability expone operaciones internas. La spec canoniza el término feature para nombrarlas — equivalente práctico de lo que otros vocabularios llaman feature, operation, skill o method. Una feature es una operación interna que la Capability expone; comparte con la Capability contenedora su modelo de datos, su SME, su instalación y su runtime. Una Capability única de costeo, por ejemplo, expone como features la asignación de costos, la rentabilidad y el pricing: tres dimensiones de un mismo saber-hacer, no tres Capabilities.
¿Capability o feature interna? — el test
Un alcance se trata como Capability propia si y solo si los tres tests siguientes son sí:
- ¿Independencia operativa? ¿Puede instalarse y operar sin la otra capacidad?
- ¿Identidad cognitiva? ¿Tiene modelo de datos y SME distintos de la otra capacidad?
- ¿Reusabilidad? ¿Tiene valor para más de un consumidor o contexto fuera de este caso?
Si uno o más son no, el alcance es feature de la Capability contenedora, no Capability propia.
Convención de IDs
Una implementación MAY adoptar una convención de identificadores para
trazar el árbol de entregables: la Capability (o entregable) lleva ID
E<n> —E1, E2—; la feature
lleva ID compuesto F<n>.<m> —F1.1,
F1.2— donde <n> es el ID de la
Capability contenedora. La convención es opcional; lo canónico es que el
constructo feature tenga nombre.
¿Qué patologías previene el test?
Distinguir feature de Capability previene dos patologías observadas en proyectos reales:
- Inflación del codominio de entregables — dimensiones de una misma Capability se documentan como Capabilities separadas, multiplicando el inventario y diluyendo la portabilidad. El ejemplo de costeo ya citado —asignación, rentabilidad y pricing tratadas como tres Capabilities cuando son features de una sola— es el caso típico.
- Esconder lock-in — alcances que sí son Capabilities propias, con lifecycle, modelo de datos y reusabilidad independientes, terminan empotrados como “sub-capacidades” de otra, escondiendo que podrían instalarse y portarse por separado.
Los dos tests se aplican en orden: el primero decide si el alcance es siquiera cognitivo; recién entonces el segundo decide su granularidad dentro de la Capa 2. Si el alcance no es cognitivo, se clasifica directamente como Conector o Plantilla por su capa, sin correr el test de feature.
¿Cómo opera la cognición sobre Capabilities?
Dado un agente con un conjunto de Capabilities activas, cuando el agente recibe una solicitud, el procesamiento sigue un flujo canónico de siete pasos.
Paso uno: la solicitud del usuario llega al agente. El agente la recibe en lenguaje natural — “reconcilía la cuenta de ingresos del mes pasado”, por ejemplo.
Paso dos: la cognición clasifica el dominio de la solicitud. Esta operación es de routing semántico — el agente identifica que la solicitud es sobre contabilidad, específicamente reconciliación. Esta identificación se basa en el vocabulario que las Capabilities activas le proveen al agente.
Paso tres: la cognición selecciona las Capabilities relevantes. En el caso del ejemplo, Finance/Contabilidad/Reconciliación es la Capability más específica aplicable. La cognición la selecciona junto con sus ancestros — Contabilidad, Finance — para tener todo el contexto heredado.
Paso cuatro: la cognición aplica el conocimiento procedimental y declarativo de las Capabilities seleccionadas. Sabe qué pasos componen una reconciliación, qué reglas debe seguir, qué errores típicos puede encontrar.
Paso cinco: la cognición invoca los tools que la Capability indica. Consulta la base de datos contable para los asientos del mes pasado, consulta el extracto bancario, ejecuta el proceso de match.
Paso seis: la cognición compone la respuesta usando el vocabulario del dominio y las heurísticas de la Capability. Reporta los matches encontrados, los items sin match, las recomendaciones de cómo proceder con las discrepancias. Usa terminología que un profesional contable reconocería como correcta.
Paso siete: si la solicitud es repetitiva — el agente ya hizo reconciliaciones similares en el pasado —, Pattern Recognition sugiere generar un Botlet que automatice el ciclo uno a seis para futuras solicitudes similares. La cognición evalúa la sugerencia y, si las condiciones son apropiadas (frecuencia alta, patrón estable), genera el Botlet.
Una observación importante: la Capability no se ejecuta — es ejecutada por la cognición. Esto importa estructuralmente: la misma Capability puede ser aplicada con distinta profundidad — rápida y superficial, o lenta y exhaustiva — según el modelo cognitivo y el modo de operación del agente. Un agente con cognición sofisticada puede aplicar la Capability General Ledger con todo el rigor de un controller experimentado; un agente con cognición más limitada puede aplicar la misma Capability con la profundidad de un junior. La Capability define el saber-hacer; la cognición define cuán profundamente lo aplica.
Las industrias verticales como Capabilities raíz
El árbol incluye una raíz dedicada a industrias verticales — Telecom, Healthcare, Retail, Banking, Public sector. Esto es deliberado: cada vertical tiene su propio vocabulario, sus propias regulaciones, sus propios procesos canónicos. La existencia de una raíz vertical separada de las raíces funcionales (Finance, Sales, Operations) refleja una propiedad estructural del saber profesional: las verticales y las funciones son ortogonales.
Un consultor financiero generalista tiene saber funcional — Finance — pero no saber vertical específico. Un consultor de finanzas para telecom tiene los dos: Finance (la función) y Telecom (la vertical). El consultor de telecom puede aplicar frameworks financieros generalistas, pero también conoce las particularidades del sector — los modelos de revenue assurance específicos de telecom, las regulaciones del regulador sectorial, los sistemas operacionales típicos de un operador. El conocimiento vertical es adicional, no sustituto, del conocimiento funcional.
El árbol de Capabilities refleja esta ortogonalidad. Un agente puede tener simultáneamente Capabilities de Finance/Treasury y de Industrias verticales/Telecom — y la combinación produce un agente que opera con saber funcional y vertical al mismo tiempo, exactamente como el consultor experto del sector.
Esta arquitectura tiene dos consecuencias importantes. La primera: la especialización vertical no es prompt — es Capability. Un “agente legal” o “agente médico” o “agente de telco” no es un prompt sofisticado del modelo general. Es un agente que carga la Capability vertical correspondiente, con su vocabulario, heurísticas y conocimiento normativo propio. Esto distingue Capabilities de System Prompts genéricos: el saber vertical es modular, persistente, y se compone con otras Capabilities no verticales sin contaminación.
La segunda consecuencia es comercial. Esta arquitectura explica el éxito comercial de los especialistas verticales del mercado actual: Cursor (coding), Harvey (legal), Jasper (marketing), Fin (customer support). Lo que estos productos venden no es “un GPT especializado” en su vertical — es una Capability vertical robusta que la cognición aplica con confianza. La diferencia con un GPT genérico no es marketing; es estructural. El usuario que prueba Cursor para programar no nota que la diferencia es la Capability Coding que la herramienta carga; nota que las respuestas son correctas más frecuentemente que con GPT genérico, y eso es exactamente lo que la Capability bien construida produce.
La Capability vertical es la diferencia entre un agente útil y un agente serio para el dominio.
Marketplace de Capabilities
Una propiedad emergente de la arquitectura es que las Capabilities admiten un mercado. Una Capability bien construida puede distribuirse entre AgencyDomains, versionarse y mantenerse por un proveedor especializado distinto del operador del AgencyDomain, cobrarse por suscripción o licencia, y auditarse por terceros respecto a su corrección y completitud.
Esto da forma a una economía de Capabilities análoga a la economía de paquetes de software open source. Quien construye y mantiene Capabilities expertas — por ejemplo General Ledger IFRS-compliant, o Telecom 5G core — puede operar como proveedor especializado sin construir agentes ni AgencyDomains propios. Su producto es la Capability misma. Su modelo de negocio es licencia o suscripción de la Capability. Sus clientes son organizaciones que operan AgencyDomains y necesitan saber-hacer profesional verificado.
La economía emergente tiene precedentes claros. La industria del software cuenta con economías similares de componentes especializados desde hace décadas: librerías compiladas que se venden o licencian, módulos certificados para frameworks específicos, configuraciones de mejores prácticas que las consultoras venden como activos. La economía de Capabilities sería evolución natural de esos modelos al campo agentivo.
La especificación normativa del protocolo de Marketplace de Capabilities — formato de paquete, modelo de versionado, sistema de firmas, modelo de cobro — es trabajo abierto en la versión 1.0 de este libro. Las implementaciones contemporáneas pueden adoptar paquetes ad-hoc; la consolidación como estándar de industria está pendiente. Cuando el consenso llegue, una versión futura del libro lo incorporará como spec normativa.
Localidad y disponibilidad — clasificación operativa de Conectores
La descripción canónica anterior trata el saber-hacer como aplicable en cualquier contexto. La realidad operativa de sistemas con presencia física múltiple — restaurantes con locales, sucursales bancarias, tiendas de retail, plantas industriales — exige una clasificación adicional que la spec formaliza explícitamente: localidad y disponibilidad offline. La clasificación pertenece a los Conectores — la cara de Capa 4 del par que acompaña a la Capability —, porque lo que reside en un lugar y necesita (o no) red es el acceso, nunca el saber: la Capability que decide cuándo y cómo invocar no tiene localidad. Se documenta en este capítulo porque el par Capability–Conector se entrega y se razona junto. Sin esta clasificación, las decisiones de qué puede invocarse desde un Botlet edge en modo offline se hacen en la oscuridad.
La clasificación opera sobre dos ejes ortogonales:
Eje de localidad
Dónde residen físicamente los componentes del Conector:
Cloud-resident — el Conector vive en un servicio remoto. Ejemplos canónicos: Conector
DTE-SII(servicio del SII de Chile para emisión de boleta y factura electrónica),Transbank-Onepay(gateway bancario),Stripe-Connect(procesamiento de pagos). El agente los invoca por red; sin red no hay acceso.Edge-resident — el Conector vive en el sitio físico, asociado a hardware o sistemas locales. Ejemplos canónicos: Conector
ESC/POS-Printer(impresora térmica de comandas y boletas con protocolo ESC/POS conectada por USB o serial),Cash-Drawer(gaveta de dinero del cajón),Pinpad-Local(pinpad de tarjetas conectado al POS),Sensor-Temperatura(sensor de cámara de frío conectado por GPIO). El agente los invoca contra el hardware del sitio; no necesitan red para operar.Híbrido — el Conector tiene un componente local y un componente cloud. Ejemplos canónicos: Conector
Cliente-DTE(firma localmente el documento, lo encola si no hay red, lo envía al SII cuando vuelve la red),Cliente-Pinpad-Procesamiento-Diferido(autoriza localmente con clave PIN y batch, envía al adquirente cuando vuelve la red). La parte local opera offline; la parte cloud sincroniza cuando hay red.
Eje de disponibilidad offline
Si el Conector puede ejecutarse sin red:
Online-only — requiere red para ejecutar. Sin red, la invocación falla. Los Conectores cloud-resident son típicamente online-only en el sentido estricto, aunque algunos tienen variantes con cliente local que los convierten en híbridos.
Offline-capable — ejecuta sin red. Si su contrato externo exige eventualmente comunicación cloud (un comprobante que debe llegar al SII, una transacción que debe consolidarse en central), encola y emite hacia afuera cuando la red vuelve. Los Conectores edge-resident son típicamente offline-capable; los híbridos también lo son por diseño.
Matriz canónica de clasificación
Cada Conector conforme declara explícitamente su posición en la matriz:
| Online-only | Offline-capable | |
|---|---|---|
| Cloud-resident | DTE-SII (sin cliente local) · Transbank Onepay · API meteorológica | (combinación inusual; típicamente migra a híbrido) |
| Edge-resident | (combinación inusual) | ESC/POS-Printer · Cash-Drawer · Sensor-Temperatura · Pinpad-Local |
| Híbrido | (combinación inusual) | Cliente-DTE · Cliente-Pinpad-Procesamiento-Diferido · Sync-Inventario |
Conexión con Capa 3 distribuida
La clasificación es necesaria estructuralmente cuando la Capa 3 está distribuida (Capítulo 5 §1). Un Botler edge debe saber qué Conectores puede invocar offline. Si no lo sabe, sus Botlets edge intentarán invocar Conectores cloud-resident sin red y fallarán catastróficamente — sin red, ni siquiera el fallback agéntico aplica, porque la cognición vive en cloud.
La regla operativa que la clasificación habilita es directa: un Botlet edge senior, en un sitio físico sin red, opera invocando exclusivamente Conectores edge-resident y la parte local de Conectores híbridos. Los cloud-resident y la parte cloud de los híbridos quedan inaccesibles temporalmente; los efectos diferidos (envío a SII, consolidación con central) se encolan; cuando la red vuelve, las colas drenan.
Propiedades exigidas
| Propiedad | Nivel | Descripción |
|---|---|---|
| Declaración explícita de localidad del Conector | MUST | Cloud-resident, edge-resident o híbrido. |
| Declaración explícita de disponibilidad offline | MUST | Online-only u offline-capable. |
| Especificación del comportamiento offline para offline-capable | MUST | Qué hace cuando no hay red, qué encola, cómo drena. |
| Resolución determinista del componente que se ejecuta en híbridos | MUST | Bajo qué condiciones corre el componente local; bajo cuáles invoca el cloud. |
Portabilidad de la Capability
La sección anterior clasifica dónde reside físicamente el Conector que acompaña a la Capability — cloud, edge o híbrido. Una propiedad distinta, que la spec formaliza explícitamente, es la portabilidad de la Capability: una Capability conforme puede instalarse y ejecutarse en cualquier AgencyDomain conforme, sin reescritura. Esta portabilidad es lo que vuelve a la Capability propiedad real del cliente — no del AgencyDomain que la aloja, ni del hosting que sostiene a ese AgencyDomain.
El argumento es el mismo de no-lock-in que el canon hace para el AgencyDomain, aplicado un nivel más abajo. Así como un AgencyDomain conforme migra a otra plataforma hosting conforme sin quedar cautivo de ella, una Capability conforme migra a otro AgencyDomain conforme sin quedar cautiva de él. El cliente que adquiere una Capability adquiere un activo portable, no un alquiler atado a una plataforma.
¿Las dos portabilidades?
Conviene no confundir dos portabilidades que operan en niveles distintos:
| Portabilidad | ¿Qué migra? | ¿Hacia dónde? |
|---|---|---|
| Portabilidad del AgencyDomain | El AgencyDomain completo | A otra plataforma hosting conforme |
| Portabilidad de la Capability | Una Capability | A otro AgencyDomain conforme |
¿Cuál es la relación Capability ↔︎ AgencyDomain?
La relación es asimétrica y explícita: un AgencyDomain aloja y ejecuta Capabilities; una Capability corre en un AgencyDomain anfitrión. La Capability es habitante de primer orden de la Capa 2 del AgencyDomain — el saber-hacer que da cognición a sus agentes —, no un recurso de soporte. Esta es la razón por la que la definición canónica de AgencyDomain nombra a las Capabilities entre lo que el AgencyDomain aloja y ejecuta, a la par de los agentes autónomos y los Botlets.
La certificación regulatoria reside en el componente certificado, no en el Botlet
Una propiedad estructural que aparece con fuerza en sistemas agentivos productivos en industrias reguladas — gastronomía, salud, finanzas, retail con DTE, farmacia, telecomunicaciones — y que la spec necesita formalizar explícitamente: la certificación regulatoria de operaciones reside en el componente certificado que el Botlet invoca — el Conector certificado, con la Capability regulada que porta su saber normativo —, nunca en el Botlet que orquesta. La separación es necesaria porque la naturaleza generada del Botlet hace imposible certificarlo a priori, y certificarlo a posteriori contradice su naturaleza regenerable.
El problema
El libro define que la cognición genera el código del Botlet (Capítulo 5 §2). Pero algunas operaciones que un Botlet ejecuta están reguladas: emisión de DTE bajo norma del SII, cobro con tarjeta bajo PCI-DSS, dispensación farmacéutica bajo registro sanitario, comunicación financiera bajo norma del regulador correspondiente. Para estas operaciones, la regulación exige certificación del componente que ejecuta la operación. Un sistema que emite boleta electrónica sin certificación SII no es legal; un sistema que cobra con tarjeta sin certificación PCI no puede operar.
Si la certificación residiera en el Botlet, cada Botlet que ejecuta
una operación regulada tendría que ser certificado individualmente. Pero
un Botlet es código generado por la cognición que se
regenera cuando el ambiente cambia. Cada regeneración produciría un
Botlet técnicamente distinto que requeriría re-certificación. La
certificación regulatoria sobre Botlets convierte el ciclo
95/4/1 en imposibilidad operacional: cada cambio del 1%
requeriría un proceso regulatorio.
La solución canónica
La spec resuelve la tensión separando responsabilidades con disciplina, y el reparto respeta la doctrina de capas del capítulo:
- El Botlet orquesta. Conoce el flujo del proceso, valida pre-condiciones operativas (¿hay productos?, ¿la mesa está abierta?, ¿el cliente tiene su RUT registrado?), captura el evento, formatea la solicitud según el contrato del componente certificado.
- El Conector certificado ejecuta la operación
regulada. Recibe la solicitud del Botlet, ejecuta bajo todas
las normas que aplican, devuelve el comprobante. El Conector
DTE-SIIrecibe el detalle de la venta, firma con el certificado tributario, transmite al SII, recibe folio y timbre electrónico, devuelve el comprobante al Botlet. Es certificable precisamente porque es acceso estable, no saber generado. - La Capability regulada porta el saber normativo. Qué exige la norma, cómo se interpreta, cuándo corresponde boleta y cuándo factura, qué hacer ante rechazo del regulador — el saber cognitivo con que la cognición decide y valida. Vive en Capa 2, se desarrolla con SME del dominio regulatorio, y acompaña al Conector como su par.
La separación tiene tres consecuencias estructurales:
Primera, la certificación es del componente
certificable. El Conector DTE-SII puede
certificarse formalmente — su código es estable, su contrato con el SII
es explícito, su comportamiento es auditable. La certificación es
trabajo único; vale para todos los Botlets que lo invoquen.
Segunda, los Botlets generados conviven naturalmente con
cumplimiento regulatorio. Un Botlet Cobrar-Mesa-9
que se regenera cuando la cocina cambia su menú no rompe la
certificación tributaria — sigue invocando el mismo Conector
DTE-SII certificado. La regeneración del Botlet afecta
lógica de orquestación, no la operación regulada.
Tercera, la frontera de auditoría queda nítida. Cuando el regulador audita, el AgencyDomain expone: el Botlet (lógica de negocio, mutable, regenerable) y el componente certificado (operación regulada, congelada, auditable). La inspección regulatoria se concentra en el Conector certificado — donde la certificación reside —, mientras la lógica de negocio se gobierna con los mecanismos de Trust del Capítulo 5 §4 sin contradecirse con la regulación.
Patrón canónico
El patrón se aplica a cualquier industria regulada:
| Industria | Botlet (orquesta) | Componente certificado (ejecuta la operación regulada) |
|---|---|---|
| Gastronomía | Cobrar-Mesa |
Conector DTE-SII (boleta o factura electrónica) |
| Banca | Procesar-Pago |
Conector Gateway-PCI-DSS (tokenización +
autorización) |
| Farmacia | Dispensar-Receta |
Conector Registro-Sanitario (validación y registro de
dispensación) |
| Telecom | Activar-Servicio |
Conector Registro-Subtel (registro regulatorio de
activación) |
| Salud | Emitir-Prescripción |
Conector MINSAL-Receta-Electrónica (firma médica
certificada) |
El patrón es uniforme: el Botlet contiene la lógica de negocio mutable; el componente certificado contiene la operación regulada congelada; la Capability regulada aporta el saber normativo con que la cognición gobierna el conjunto. La frontera entre ellos es la frontera entre lo que la organización puede regenerar libremente y lo que debe mantener bajo certificación.
Propiedades exigidas
| Propiedad | Nivel | Descripción |
|---|---|---|
| Componentes regulados declaran su régimen regulatorio | MUST | Qué norma cumple, ante qué regulador, con qué número de certificación. |
| Componentes certificados son inmutables entre auditorías | MUST | El código del Conector certificado no se regenera; cambia solo bajo proceso regulatorio. |
| Botlets pueden invocar componentes certificados sin restricción | MUST | El contrato del componente es estable; el Botlet lo invoca como cualquier otro. |
| Auditabilidad de la frontera | MUST | El log distingue claramente operaciones del Botlet (lógica de negocio) de operaciones del componente certificado (operación regulada). |
Capabilities y Botlets — la relación
Capabilities y Botlets viven en capas distintas y resuelven problemas distintos, pero interactúan de manera estructurada. Capability vive en Capa 2 (Cognición). Es saber-hacer. Botlet vive en Capa 3 (Autonomía). Es hacer aprendido. Capability tiene forma de vocabulario más procedimientos más heurísticas más tools. Botlet tiene forma de código tradicional ejecutable. Capability es persistente y versionada. Botlet es auto-regenerable y efímero. Capability se aplica cuando el agente reconoce su dominio. Botlet se invoca cuando el agente reconoce el patrón. Capability es creada por humanos expertos o por proveedores especializados. Botlet es creado por la cognición del agente, automáticamente.
La interacción canónica es la siguiente: una Capability puede dar lugar a múltiples Botlets. El agente que aplica General Ledger repetidamente para una empresa específica empieza a generar Botlets que automatizan los pasos rutinarios del proceso — clasificar transacciones, conciliar cuentas, generar reportes mensuales — sin invocar la cognición. La Capability sigue siendo la misma; los Botlets son el residuo eficiente de su aplicación reiterada en un contexto particular.
Esta relación es lo que permite que el sistema agentivo escale económicamente. Las Capabilities son el saber estable que la organización adquiere, mantiene, evoluciona. Los Botlets son el residuo eficiente que la cognición genera al aplicar Capabilities reiteradamente en contextos específicos. La organización invierte en Capabilities; los Botlets emergen del uso. La inversión en saber genera ahorro en operación.
Conformidad
Una implementación de Capabilities conforme a esta especificación debe satisfacer los siguientes requisitos:
| Requisito | Nivel |
|---|---|
| Estructura jerárquica en árbol | MUST |
| Cualquier nodo es Capability válida | MUST |
| Composabilidad entre Capabilities | MUST |
| Anatomía con vocabulario + procedimental + declarativo + heurísticas | MUST |
| Versionado explícito | MUST |
| Estado de madurez declarado (Borrador / Vigente / Deprecado) | MUST |
| Selección por la cognición, no ejecución directa | MUST |
| Verticales como raíz dedicada | SHOULD |
| Marketplace abierto | MAY (cuando la spec normativa exista) |
| Declaración explícita de localidad del Conector acompañante (cloud / edge / híbrido) | MUST |
| Declaración explícita de disponibilidad offline | MUST |
| Portabilidad entre AgencyDomains conformes | MUST |
| Componentes regulados (Capability normativa + Conector certificado): régimen declarado | MUST |
| Conectores certificados: inmutabilidad entre auditorías | MUST |
Frontera de evolución
Tres áreas activas de evolución de la primitiva Capability merecen mención.
El marketplace de Capabilities es la primera. El protocolo normativo aún no está consolidado; cuando lo esté, la versión 2.0 de este libro lo incorporará.
Las Capabilities cross-vertical son la segunda. Cómo una Capability puede combinarse con verticales múltiples sin contradicciones — un agente que opera en finanzas para banca y para telecom simultáneamente, por ejemplo — exige refinamiento de los mecanismos de herencia que la versión 1.0 de la spec describe.
La auditoría de Capabilities es la tercera. Cómo certificar que una Capability hace lo que dice hacer — que una Capability IFRS Compliance efectivamente refleja IFRS y no su aproximación informal — es problema de gobernanza que el campo aún no resuelve. Las soluciones probables vendrán del lado de la auditoría profesional tradicional adaptada al contexto agentivo.
Trust Infrastructure
Hay una asimetría operativa que cualquier organización que ha intentado llevar IA agentiva a producción reconoce con incomodidad: lo que funciona en piloto rara vez funciona en producción enterprise. Un piloto controlado, con un puñado de usuarios sofisticados, supervisado de cerca por el equipo que lo construyó, puede ejecutarse exitosamente sin gobernanza explícita. Los pilotos demuestran capacidad técnica, no aptitud operativa. La distancia entre los dos es exactamente lo que esta sección desarrolla.
La cifra que más preocupa al campo en 2026 es la proyección de Gartner: más del cuarenta por ciento de los proyectos de IA agentiva serán cancelados antes de fines de 2027. Las razones que Gartner identifica son tres: costos imprevistos, valor de negocio poco claro, y controles de riesgo inadecuados. La tercera razón — controles de riesgo inadecuados — es la que conecta directamente con el contenido de esta sección. Las organizaciones cancelan proyectos no porque la tecnología no funcione, sino porque la organización no puede defender lo que la tecnología hace cuando algo sale mal. La diferencia entre un piloto exitoso y un proyecto cancelado es típicamente la madurez de la infraestructura de confianza.
Trust Infrastructure es el conjunto de propiedades transversales que permiten a una organización confiar en que sus agentes operen con autonomía sin perder control. No es una capa adicional de la Arquitectura Agentiva — es una propiedad que atraviesa las cuatro capas existentes (Interacción, Cognición, Autonomía, Acceso) y se ejerce en distintos puntos según el pilar específico. Esta sección desarrolla los cinco pilares con el detalle que el lector arquitecto necesita para diseñar y el lector ejecutivo necesita para evaluar.
La Trust Infrastructure no es lo que se agrega después de que el agente funciona. Es lo que separa pilotos de producción.
La urgencia de Trust Infrastructure ya no es solo arquitectónica. Es regulatoria. Singapore IMDA publicó en enero de 2026 el primer framework estatal de gobernanza específicamente para IA agentiva. La Unión Europea hace lo propio con el EU AI Act. NIST con su AI Risk Management Framework. ISO/IEC con la norma 42001. La pregunta ya no es si los reguladores exigirán infraestructura de confianza — es si la organización puede demostrarla auditablemente cuando se la pidan. Las organizaciones que no la tengan operativa enfrentarán, en el horizonte de los próximos veinticuatro meses, una decisión binaria: invertir aceleradamente para alcanzar conformidad, o suspender operaciones agentivas en mercados regulados.
Los cinco pilares
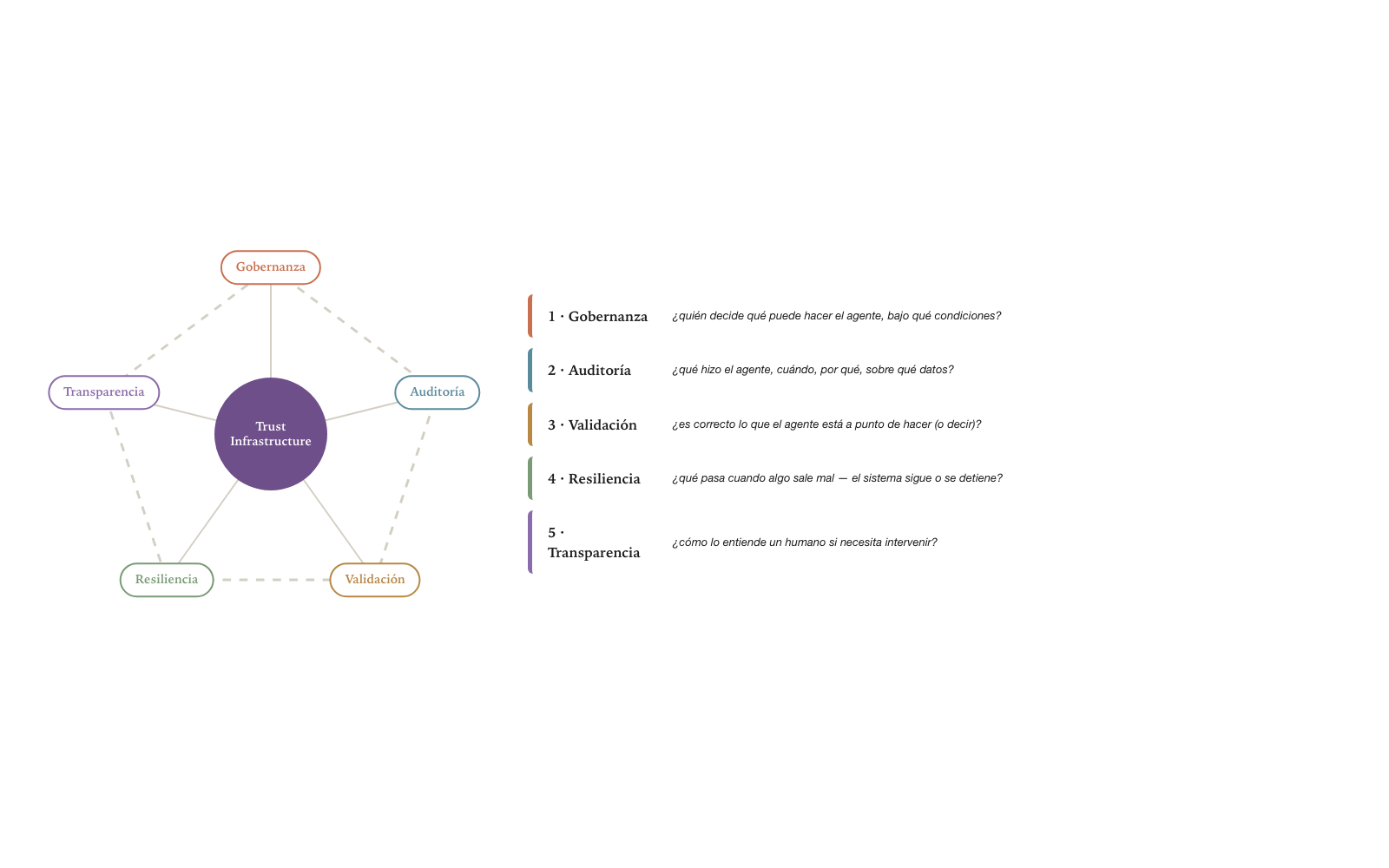
Cinco pilares constituyen Trust Infrastructure. Cada uno responde una pregunta operativa específica que la organización necesita poder responder cuando alguien — un auditor, un regulador, un cliente — la cuestione.
| Pilar | Pregunta que responde |
|---|---|
| Gobernanza | ¿Quién decide qué puede hacer el agente, bajo qué condiciones? |
| Auditoría | ¿Qué hizo el agente, cuándo, por qué, sobre qué datos? |
| Validación | ¿Es correcto lo que el agente está a punto de hacer (o decir)? |
| Resiliencia | ¿Qué pasa cuando algo sale mal — el sistema se detiene o sigue? |
| Transparencia | ¿Cómo lo entiende un humano si necesita intervenir? |
Cada pilar se ejerce en una o más capas y se materializa con mecanismos concretos. Las próximas cinco subsecciones desarrollan cada pilar con detalle. Después mostramos el mapa transversal — qué pilar opera principalmente en qué capa — y cerramos con la lectura regulatoria del campo.
Pilar 1 — Gobernanza
El pilar de Gobernanza define el conjunto de mecanismos mediante los cuales la organización establece qué puede hacer el agente, bajo qué condiciones y con qué nivel de supervisión. Es el pilar más visible para quien viene del mundo del IT tradicional, porque tiene el equivalente más directo en mecanismos conocidos — IAM, SSO, RBAC. Pero la Gobernanza agentiva es estructuralmente distinta de la gobernanza tradicional, y confundir las dos es fuente recurrente de proyectos fallidos.
La Gobernanza tradicional pregunta “¿quién puede ver qué datos?”. El sujeto del control es un humano con identidad estable; el objeto es un recurso discreto. La pregunta es estática: los permisos rara vez cambian, y cuando cambian es por evento humano explícito (alguien fue contratado, alguien fue promovido, alguien dejó la empresa). La Gobernanza agentiva pregunta “¿qué puede hacer un agente, bajo qué condiciones?”. El sujeto es un agente que actúa autónomamente; el objeto es una secuencia de acciones que el agente puede ejecutar con grados variables de impacto. La pregunta es dinámica: las condiciones cambian con el contexto, el momento, el estado del sistema. Las herramientas de Gobernanza tradicional — IAM, SSO, RBAC — son insuficientes para este modelo. Funcionan bien para sujetos humanos con identidad estable; no funcionan para agentes que actúan continuamente con grados variables de autonomía.
Los mecanismos canónicos de la Gobernanza agentiva son cuatro. Las políticas configurables son reglas declarativas — no código embebido — que definen qué tools puede invocar el agente, sobre qué datos, en qué horarios, con qué umbrales de impacto. La separación entre política (declarativa) y código (imperativo) es importante: las políticas deben poder cambiarse sin redeploy del sistema, deben poder versionarse independientemente del código, deben poder ser auditadas sin requerir review del código. Los permisos CRUDLEX — Create, Read, Update, Delete, List, Execute — son modelo granular de permisos sobre tools y datos, aplicable por usuario, agente o contexto. La operacionalización completa de CRUDLEX vive en el Capítulo 8. La aprobación humana para operaciones críticas establece que el agente puede ejecutar operaciones de bajo impacto autónomamente, pero las de alto impacto se detienen y solicitan aprobación. La definición de “alto impacto” es política, no técnica — la organización decide qué umbrales activan aprobación. El registro de IA es inventario formal de qué agentes están activos, qué Capabilities aplican, qué tools tienen autorizados, quién los aprobó. Es lo que un regulador verá cuando audite, y lo que la organización debe mantener actualizado y accesible.
Los datos del campo respecto a Gobernanza son crudos — el Capítulo 2 los documenta. La historia que cuentan es consistente: la mayoría de las organizaciones sabe que el problema existe pero no ha invertido lo suficiente para resolverlo, y los reguladores están en camino de forzar la inversión.
Pilar 2 — Auditoría
El pilar de Auditoría define la capacidad de reconstruir, después del hecho, qué hizo el agente, cuándo, por qué y sobre qué datos — con suficiente fidelidad para análisis forense, cumplimiento regulatorio o disputa contractual. Es el pilar que la organización necesita cuando algo sale mal: si un agente tomó una decisión que produjo un mal resultado, o ejecutó una acción que un cliente cuestiona, o realizó operación que el regulador quiere examinar, la organización necesita poder reconstruir auditablemente lo que pasó.
Los mecanismos canónicos de la Auditoría son cuatro. El append-only log inmutable es el componente central: toda acción del agente queda registrada en un log que no admite modificación retroactiva. Solo se agrega — nunca se edita ni se elimina. El log típicamente está encadenado criptográficamente: cada registro contiene el hash del anterior, formando una cadena verificable donde una alteración retroactiva sería inmediatamente detectable. El trace de cada acción registra identidad del agente, capability invocada, tool ejecutado, parámetros, resultado, timestamp, contexto. Cada acción genera un registro completo que reconstruye el estado del sistema en el momento de la decisión. El lineage de decisiones es la cadena causal de razonamiento que llevó a una acción particular: qué información consultó el agente, qué Capabilities aplicó, qué heurísticas usó, qué cognición evaluó. Sin lineage, una acción aparece como evento aislado; con lineage, aparece como resultado de un proceso de razonamiento reconstruible. El identity tagging por acción asegura que cada acción es atribuible inequívocamente a un agente identificable, no a “el sistema” o a “la IA”. La distinción importa para responsabilidad: cuando algo sale mal, debe poder identificarse qué agente específico fue responsable, y por extensión, quién lo configuró, quién aprobó sus capacidades, qué política cubría su operación.
ISACA — la asociación profesional de auditoría — destaca que la IA agentiva presenta un desafío creciente para funciones de auditoría porque sus procesos de decisión carecen de trazabilidad clara cuando el sistema no fue diseñado con auditoría en mente. La observación es importante porque captura una propiedad estructural: un agente que combina cognición probabilística (LLM) con tools determinísticos toma decisiones cuyo camino es difícil de reconstruir si el log no está diseñado para hacerlo. Un log que solo registra “el agente ejecutó X tool con Y parámetros” no es suficiente — necesita registrar también “porque la cognición evaluó Z razonamiento basándose en W contexto”. La Auditoría agentiva exige diseño explícito desde el inicio. No emerge naturalmente de una arquitectura agentiva — se construye con disciplina desde el inicio.
La auditoría agentiva exige diseño explícito. No emerge naturalmente de una arquitectura agentiva — se construye con disciplina desde el inicio.
Pilar 3 — Validación
El pilar de Validación define la capacidad de verificar que la respuesta o acción del agente sea correcta antes de que afecte al mundo. Es el pilar más reciente en madurar como categoría — la industria de validación de IA es de los últimos tres años — y, simultáneamente, el más crítico para casos de uso donde el costo del error es alto.
La diferencia con la validación tradicional es importante. La validación tradicional verifica formatos: ¿el JSON es válido? ¿la fecha tiene el formato correcto? ¿el monto es número? La validación agentiva verifica semántica: ¿el agente está diciendo la verdad? ¿está actuando dentro de los límites razonables del dominio? ¿está exponiendo datos que no debería? La validación tradicional opera sobre estructura; la validación agentiva opera sobre significado.
Los mecanismos canónicos de Validación son cinco. La detección de alucinaciones verifica que las afirmaciones factuales del agente sean consistentes con las fuentes consultadas. Es área activa de investigación; mecanismos contemporáneos incluyen self-consistency (preguntar lo mismo de varias maneras y comparar respuestas), retrieval-augmented verification (consultar fuentes autoritativas antes de afirmar), y model-as-judge (un segundo modelo evalúa la respuesta del primero). La validación de respuestas estructuradas verifica que las salidas con schema — JSON, XML, tablas — cumplan el contrato esperado antes de emitirlas. Es la validación más directa, equivalente a la validación tradicional pero aplicada sobre salidas que el modelo generó. La prompt injection prevention detecta intentos de manipulación a través de inputs maliciosos disfrazados como datos legítimos. Un usuario que intenta inyectar instrucciones en un campo de comentarios para que el agente las ejecute como si fueran instrucciones legítimas es ataque común que la validación debe detectar. Productos como Lakera y Lasso Security productizan precisamente este mecanismo. La DLP — Data Loss Prevention — detecta automáticamente datos personales (PII), información financiera sensible o material clasificado en lugares donde no deberían aparecer. Si un agente está a punto de incluir un número de seguridad social en una respuesta a un usuario externo, la DLP lo detecta y bloquea. La tokenización reemplaza datos sensibles por tokens antes de que lleguen al modelo. Permite que el agente razone sobre los datos sin exponerlos al proveedor de cognición externo. La organización mantiene el mapeo token-a-dato en almacén con seguridad reforzada — típicamente HSM (Hardware Security Module) o servicio dedicado.
Informatica formula con precisión la transición que la Validación representa: “Because agents act without human approval loops, the data they use must be fully trusted, verified, and monitored.” La frase captura algo importante. En sistemas tradicionales, un humano supervisa cada operación importante antes de ejecutarla — es el último loop de validación, hecho de carne. En sistemas agentivos, ese loop humano no existe en cada operación — solo en operaciones críticas que escalan. La Validación tiene que suplir el loop humano para todas las demás operaciones, asegurando que lo que el agente está a punto de hacer es correcto antes de hacerlo. Sin esa suplencia, el sistema se queda corto: o ejecuta acciones incorrectas, o requiere supervisión humana en cada operación, anulando la productividad del agente.
La validación de la spec de un componente especialista admite un patrón estructural que merece nota: la validación por delegación. El runtime genérico de Capa 3 (el Botler) hace valer la validación de la spec de un Botlet sin entender su dominio — orquesta el punto de validación que el Botlet o su proto-Botlet provee, le entrega el contexto genérico que controla (catálogo de Capabilities, identidad, políticas del AgencyDomain) y audita el veredicto en el append-only log. El juicio de qué hace válida a la spec vive en el especialista; el runtime exige y registra la validación sin ejecutarla con conocimiento de dominio. El desarrollo de este patrón vive en el capítulo de Botlets; aquí solo se enlaza el principio con el pilar de Validación.
Con los Agentlets (Capítulo 5 §7), el pilar de
Validación gana además una sede en la Capa 3: la
inferencia acotada de cada Agentlet cursa por el punto de control
cognition_call del handle del Botler, y ahí aplican los
mecanismos de este pilar — detección de alucinaciones sobre sus
veredictos, validación de salidas estructuradas contra el contrato del
charter, DLP y tokenización sobre lo que entra y sale del modelo. La
corrección estadística que los Agentlets introducen en la capa de la
memoria muscular queda así confinada a Lets declarados y auditables — la
disciplina de delgadez que la Bounded Concerns Architecture enseña,
ejercida dentro del Mundo Agentivo.
Pilar 4 — Resiliencia
El pilar de Resiliencia define la garantía de que el sistema sigue operando — y la organización conserva control — cuando algo sale mal. Es el pilar más cercano a las prácticas de ingeniería de software tradicional — el campo de DevOps y SRE ha desarrollado patrones de resiliencia durante quince años — pero adaptado a las particularidades del sistema agentivo.
Los mecanismos canónicos son cinco. La garantía de fallback es la propiedad fundamental que ya describimos en Capítulo 5 §2 (Botlets) y que el §7 extiende al Agentlet: si un Botlet falla catastróficamente, la cognición ejecuta la tarea manualmente; si un Agentlet no resuelve dentro de su charter, escala a la Cognición plena; si la cognición falla, la operación escala al humano. Esta garantía es lo que distingue al sistema agentivo conforme a esta spec de cualquier “automatización con IA” frágil. El manejo de errores estructurado asegura que los errores son tipificados, accionables, propagados con contexto suficiente para que el siguiente nivel decida. Un error que dice “algo falló” no es manejo estructurado; un error que dice “API X devolvió código Y, parámetro Z, en operación W del agente V” es manejo estructurado. El sandboxing asegura aislamiento de ejecución de las unidades de Capa 3 y del código generado, con límites estrictos sobre qué pueden tocar. Detalle en la sección de Botlets. Los circuit breakers detienen y notifican cuando un agente o Botlet falla repetidamente, antes de seguir consumiendo recursos. Es patrón clásico de resiliencia adaptado al contexto agentivo: si un Botlet ha fallado N veces consecutivas, se detiene su ejecución automática y se escala al humano para revisión. El rate limiting establece límites configurables sobre frecuencia de invocaciones, tanto a la cognición (controlar costo) como a tools externos (proteger sistemas downstream). Sin rate limiting, un agente con un loop mal diseñado puede agotar los recursos del sistema en horas.
El principio de no-detención que la spec garantiza — declarado en Capítulo 5 §2 — es lo que permite a la organización delegar operación a agentes con la confianza de que un fallo aislado no detiene el negocio. La resiliencia es lo que hace esa confianza razonable.
Continuidad de negocio operacional vs garantía de fallback agéntico
La garantía de fallback que el Pilar 4 describe supone cognición disponible: cuando el Botlet falla por cambio de ambiente, la cognición rescata. Este supuesto se cumple en la mayoría de los escenarios — la cognición vive en cloud altamente disponible y los Botlets fallan ocasionalmente por cambios menores que la cognición resuelve sin esfuerzo. Pero en sistemas productivos físicos — locales sin red, hardware caído, energía cortada — la cognición tampoco está disponible, y la continuidad operacional necesita un protocolo adicional que la garantía de fallback agéntico no cubre.
La spec distingue por tanto dos mecanismos complementarios que resuelven escenarios distintos:
Garantía de fallback agéntico — la cognición ejecuta cuando el Botlet falla por cambios de ambiente. Es propiedad de la Arquitectura Agentiva, codificada en la spec del Botlet (§2). Cubre la inmensa mayoría de los fallos: el ambiente cambia, el Botlet detecta el cambio, la cognición rescata. Esta es la propiedad que produce la trayectoria de madurez del Botlet desde junior hasta senior.
Continuidad de negocio operacional — protocolos manuales documentados para cuando el Botlet senior cae por causas exógenas y la cognición tampoco está disponible. Es propiedad operacional, equivalente a la que cualquier negocio tradicional ya tiene cuando se le cae el sistema (corte de energía, hardware caído, red catastrófica, proveedor crítico abajo). No depende de la spec agentiva — depende del protocolo del cliente.
Las dos no se excluyen: se complementan. La primera resuelve el aprendizaje del Botlet y la mayoría de los fallos operativos. La segunda cubre el residuo exógeno catastrófico que ningún sistema previene completamente.
Conexión con la madurez del Botlet
La conexión entre los dos mecanismos y la trayectoria de madurez del Botlet (§2) merece tratamiento explícito porque revela una propiedad estructural del sistema agentivo:
La garantía de fallback agéntico es lo que produce la madurez. Cada vez que el Botlet falla por un cambio de ambiente, la cognición rescata, regenera y devuelve operación — y esa regeneración es justamente lo que produce la incorporación progresiva de variantes hasta alcanzar madurez senior. Sin fallback agéntico, el Botlet quedaría atrapado en su versión inicial, sin manera de aprender. Sin fallback agéntico, el Botlet no madura.
La continuidad operacional, en cambio, no incide en la madurez. Opera sobre Botlets ya maduros que caen por causas exógenas, no por aprendizaje pendiente. Cuando un Botlet senior cae porque el local sufrió corte de energía, no es problema de aprendizaje — es problema operacional que el protocolo de continuidad debe resolver (caja manual, registro en papel, conciliación posterior).
| Mecanismo | ¿Cuándo opera? | ¿Qué resuelve? | ¿Quién lo provee? |
|---|---|---|---|
| Garantía de fallback agéntico | Botlet junior, en aprendizaje, o senior con variante nueva | Cambios de ambiente que el Botlet no anticipó | La spec agentiva (Capa 2 + Capa 3) |
| Continuidad de negocio operacional | Botlet senior caído por causa exógena, sin cognición disponible | Continuidad operativa cuando ningún componente computacional opera | Protocolo del cliente (procedimiento manual documentado) |
¿Por qué importa la distinción?
Sin la distinción, los planes de continuidad operacional se confunden con la promesa agéntica. Un cliente lee “garantía de fallback” en la documentación del producto y asume que cubre cualquier fallo, incluyendo cortes de energía. Cuando ocurre el corte y descubre que el sistema no opera, atribuye el fallo a la arquitectura agentiva — y concluye que “el sistema falla”.
Reconocer las dos propiedades como mecanismos separados pero complementarios reduce ansiedad sobre offline y deja claro qué resuelve la arquitectura y qué resuelve el protocolo operacional del cliente. La conversación con el cliente cambia: ya no se promete que “nunca pasa nada”; se promete que “los fallos por aprendizaje los maneja la arquitectura, los fallos exógenos los maneja el protocolo de continuidad — y ambos están documentados”.
La distinción conceptual entre fallback agéntico y continuidad operacional es la sede de esta sección. Su operacionalización —el protocolo de campo por sitio, los modos de degradación y las marcas de log con que se registra la transición a continuidad— vive en el Capítulo 8, donde se desarrollan las exigencias operativas (MUST en su casi totalidad, incluida la trazabilidad de la transición a modo continuidad).
Pilar 5 — Transparencia
El pilar de Transparencia define la capacidad del humano de entender, en tiempo real, qué está haciendo el agente y por qué — con detalle suficiente para intervenir si es necesario. Es el pilar que conecta los otros cuatro: la Gobernanza define qué puede hacer, la Auditoría registra qué hizo, la Validación verifica qué está por hacer, la Resiliencia asegura que sigue operando — la Transparencia asegura que un humano puede entender todo lo anterior.
Los mecanismos canónicos son cinco. La observabilidad completa entrega tracing end-to-end de cada operación, métricas de latencia, costo, calidad, y eventos estructurados. Es el equivalente agentivo de los sistemas de observabilidad tradicionales (Datadog, New Relic, Splunk) adaptados a las particularidades del sistema agentivo. Las métricas operativas miden tasa de éxito de Botlets, frecuencia de regeneración, latencia de cognición, consumo de tokens, errores por capa. Estas métricas son lo que un equipo de operaciones consulta diariamente para entender la salud del sistema. Los traces consultables por humanos aseguran que la traza de una decisión es legible por un humano técnico, no solo por otra máquina. Esto importa para auditoría reactiva: cuando algo salió mal y un humano necesita reconstruir qué pasó, debe poder leer los traces directamente, no depender de un sistema de análisis automatizado intermedio. Las alertas proactivas notifican cuando el agente detecta que está cerca de un límite, fallando con frecuencia inusual, o tomando decisiones de alto impacto. La proactividad importa: el sistema no espera a que el humano consulte para informar problemas; informa antes de que se vuelvan críticos. Los dashboards de gobernanza dan vista al responsable humano: qué agentes están operativos, qué hacen, con qué éxito, sobre qué recursos. Es interfaz de control para la persona que gobierna el sistema.
La observabilidad de IA es categoría madura del mercado. Productos como Langfuse, LangSmith, Helicone, Arize AI, Braintrust, Weights & Biases cubren distintas capas. La transparencia agentiva no exige construir estos productos desde cero — exige integrarlos coherentemente con los demás pilares de Trust Infrastructure. La organización adopta los productos que mejor se ajusten a su stack y los integra con el resto de la infraestructura.
Contrato declarativo de calidad
Los pilares de Resiliencia y Auditoría se ejercen mejor cuando lo que la organización debe auditar y sostener está declarado, no enterrado en código. El contrato declarativo de calidad es el mecanismo que lo habilita: cualquier Botlet conforme MAY declarar sus atributos de calidad como propiedades estructuradas, no como código embebido. Trust Infrastructure los lee de manera uniforme — sin acoplarse a la implementación de cada Botlet.
Los atributos canónicos del contrato son cinco. La
Frescura declara la antigüedad máxima admisible de los
datos que el Botlet consume. El SLA declara la latencia
esperada extremo a extremo, expresada como percentiles
(p50, p99). La Política de
degradación declara el comportamiento ante fallo —
refuse (rechaza y no entrega), warn_and_show
(advierte y muestra de todas formas), show_last_valid
(entrega el último resultado válido conocido),
agentic_fallback (escala a la cognición). La
Audiencia declara la política
RLS/CRUDLEX aplicable a quién puede consumir
la manifestación. La Política de refresh declara cómo
se renueva — on-demand, scheduled o
push.
Declarados así, estos atributos se vuelven mecanismos transversales
que sirven a dos pilares a la vez. Para la Resiliencia,
la Política de degradación y la Política de refresh son configuración
auditable y no lógica frágil dispersa por la implementación: el runtime
sabe qué hacer ante fallo y cuándo renovar sin leer el cuerpo del
Botlet, y la Frescura y el SLA dan umbrales explícitos contra los cuales
medir si un resultado sigue siendo confiable. Para la
Auditoría, los cinco atributos permiten que Trust
Infrastructure los audite uniformemente, los curse por políticas
globales del AgencyDomain (una política puede endurecer la
Frescura mínima o vetar warn_and_show para una clase de
operación) y los reporte como métricas estándar
comparables entre Botlets. La organización no inventa un formato por
Botlet; declara contra un vocabulario común que el append-only log y los
dashboards de gobernanza ya entienden.
Mapa transversal — ¿qué pilar opera en qué capa?
Los cinco pilares se ejercen en distintas capas de la Arquitectura Agentiva, como sintetiza la figura anterior.
Tres lecturas del mapa son útiles. La primera: la Capa 4 concentra la mayor carga. Gobernanza, Auditoría y Validación final operan principalmente en Capa 4. Es coherente con su naturaleza: la Capa 4 es donde la cognición se convierte en acción real, y por tanto donde se ejerce el control. Las decisiones de qué se puede hacer, qué se está por hacer, y qué se hizo, todas pasan por Capa 4. La segunda: la Resiliencia vive en la Capa 3. La continuidad operativa se sostiene en la autonomía persistente del agente, su Botler, sus Botlets con fallback. Cuando el sistema agentivo “sigue funcionando” a pesar de que algún componente falló, esa continuidad la asegura la Capa 3. La tercera: la Transparencia es propiedad transversal. No vive en una capa específica — atraviesa todas. Esto exige diseño explícito de instrumentación en cada capa, no agregada al final como capa adicional. Cada capa emite eventos, cada capa tiene métricas, cada capa contribuye al log de auditoría.
Trust Infrastructure y los reguladores
La infraestructura de confianza no es decisión solo arquitectónica. Es decisión de conformidad regulatoria ante un marco creciente de regulación específica para IA agentiva. Los principales frameworks que el campo enfrenta a inicios de 2026 son:
El EU AI Act de la Unión Europea, vigente con aplicación gradual entre 2024 y 2026. El NIST AI Risk Management Framework de Estados Unidos, vigente como framework voluntario pero adoptado por industrias reguladas. La ISO/IEC 42001, publicada en 2023 con certificación voluntaria pero creciente adopción enterprise. El MGF — Model AI Governance Framework for Generative AI de Singapore IMDA, publicado en enero de 2026 y notable por ser el primer framework estatal específicamente para IA agentiva (el nombre conserva la IA generativa; el cuerpo gobierna agentes). Los lineamientos del World Economic Forum sobre onboarding y gobernanza de agentes. Las guías de la NACD — National Association of Corporate Directors — para boards corporativos.
Patrón común: todos estos frameworks exigen — en términos formalmente distintos pero funcionalmente equivalentes — los cinco pilares descritos en esta sección. No es coincidencia. La lista de pilares emerge del análisis funcional del problema, no de imitación a un regulador particular. Cualquier regulador serio que analice los riesgos del sistema agentivo llega a una lista similar: gobernanza, auditoría, validación, resiliencia, transparencia. La ecuación es estructural.
La consecuencia operativa para la organización es que invertir en Trust Infrastructure no es solo decisión arquitectónica — es inversión regulatoria. Una organización que adopta los cinco pilares correctamente se posiciona para satisfacer los cuatro frameworks principales simultáneamente — EU AI Act, NIST AI RMF, ISO/IEC 42001, IMDA MGF —, porque convergen en exigencias funcionales similares. Una organización que los descuida queda expuesta a los cuatro a la vez, sin defensa estructural.
Conformidad
Una implementación de Trust Infrastructure conforme a esta especificación debe satisfacer:
| Requisito | Nivel |
|---|---|
| Los cinco pilares ejercidos en alguna capa | MUST |
| Append-only log inmutable de toda acción | MUST |
| Permisos CRUDLEX granulares por usuario / agente / contexto | MUST |
| Garantía de fallback ante fallo | MUST |
| Trazabilidad consultable por humanos | MUST |
| Detección de alucinaciones | SHOULD |
| Prompt injection prevention | SHOULD |
| DLP / tokenización de datos sensibles | SHOULD |
| Aprobación humana configurable para operaciones críticas | MUST |
| Conformidad con al menos un framework regulatorio reconocido | SHOULD |
| Distinción explícita entre fallback agéntico y continuidad operacional | MUST |
| Protocolo de continuidad operacional documentado para sistemas con presencia física | MUST |
Frontera de evolución
Tres áreas activas de evolución de Trust Infrastructure merecen mención al cierre.
La auditoría auditable es la primera. Protocolos verificables criptográficamente que permitan a un auditor externo verificar el log sin acceso al sistema. Está en intersección con tecnologías de cómputo confidencial y zero-knowledge proofs. Cuando madure, permitirá auditoría externa sin exponer datos operativos al auditor.
El trust scoring de agentes es la segunda. Métricas compuestas de confiabilidad que evolucionan con el comportamiento del agente, similar al puntaje de crédito. Permitiría a la organización adoptar agentes con confianza modulada según su trust score: agentes con alto score reciben más autonomía; agentes con bajo score requieren más supervisión.
La federación de Trust Infrastructure es la tercera. Cuando dos AgencyDomains colaboran (federación, ver sección 1 de este capítulo), cómo sus respectivas Trust Infrastructures se reconocen y se componen. ¿La política del AgencyDomain A se aplica también a las invocaciones del AgencyDomain B? ¿Cómo se reconcilian políticas contradictorias? Es problema sin solución general en la versión 1.0 de la spec.
Asistente vs Agente Autónomo

La industria habla de “agentes de IA” como si fueran una sola cosa. No lo son. Bajo ese término genérico conviven dos modos operativos distintos, con propósitos distintos, modelos económicos distintos, modelos de gobernanza distintos. Confundir los dos es probablemente la fuente más recurrente de proyectos agentivos que fracasan al pasar de piloto a producción.
Los dos modos son el Asistente y el Agente Autónomo. Esta sección desarrolla la distinción con el detalle que merece, porque las consecuencias prácticas de mantenerla — o de ignorarla — son enormes.
La distinción
El Asistente vive en Capa 2 (Cognición). Es reactivo: responde cuando se le solicita, espera input, no mantiene Botlets propios, no tiene vida persistente entre sesiones. El usuario habla con el Asistente, el Asistente responde, la conversación termina. Cuando el usuario regresa más tarde, el Asistente reanuda como si fuera la primera vez — sin memoria del intercambio anterior salvo cuando se la inyecta explícitamente como contexto. Ejemplos paradigmáticos del Asistente son Claude, ChatGPT, Copilot conversacional. Son productos masivos y útiles, pero estructuralmente, son Asistentes — esperan que alguien les hable.
El Agente Autónomo vive en Capa 3 (Autonomía). Es proactivo: actúa por iniciativa propia, persigue objetivos, mantiene Botlets, los regenera cuando el ambiente cambia, vive en background continuo. El usuario no le habla — el Agente Autónomo opera. Cuando el usuario consulta al Agente Autónomo, no es porque la conversación apenas empieza, sino porque el Agente lleva horas o días operando y el usuario quiere saber el estado. Ejemplos paradigmáticos del Agente Autónomo son los bots que monitorean anomalías en una red, los procesos que ejecutan reconciliaciones nocturnas, los agentes que vigilan SLAs y escalan cuando se aproximan a violación. Son menos visibles que los Asistentes — no aparecen en aplicaciones consumer — pero estructuralmente son donde la mayor parte del valor económico del sistema agentivo se genera.
El Asistente espera. El Agente persigue.
La frase canónica resume bien la diferencia operativa. El Asistente es trabajador de turno: aparece cuando se le llama, responde, se va. El Agente Autónomo es trabajador permanente: vive en el sistema, monitorea continuamente, ejecuta cuando corresponde, escala cuando es necesario.
La distinción no es jerárquica. Un Agente Autónomo no es un Asistente mejorado. Son roles distintos con propósitos distintos. Un sistema agentivo maduro contiene ambos modos y los compone. La organización que solo opera Asistentes se queda corta porque sus agentes no pueden operar en background; la organización que solo opera Agentes Autónomos se queda corta porque no puede atender solicitudes humanas conversacionales. Sistemas serios necesitan los dos.
El término paraguas Agente cubre un tercer miembro además de estos dos modos: el Agentlet — el agente empaquetado, de charter acotado, que vive como unidad de catálogo en la Capa 3 junto al Botlet. No es un tercer modo del mismo eje — los modos describen cómo opera el agente pleno; el Agentlet es una pieza que el agente pleno engendra y mantiene. Su formalización, y la frontera que lo separa del Agente Autónomo, viven en el §7 de este capítulo.
¿Por qué la distinción importa?
Tres razones operativas concretas justifican la atención que esta sección dedica a la distinción.
La primera razón es que se diseñan distinto. El Asistente se diseña para conversación. La latencia debe ser perceptible al humano — segundos típicamente —, la interfaz es textual o por voz, el modo es turno-respuesta. Cuando el humano cierra la conversación, el Asistente termina. El Agente Autónomo se diseña para vida persistente. La latencia es operativa — minutos u horas si conviene —, sin interfaz directa al humano salvo cuando escala, monitoreo continuo de eventos del ambiente. Cuando el humano se desconecta, el Agente sigue.
Una arquitectura que mezcla ambos modos sin distinción produce sistemas confusos: Asistentes con Botlets que el humano no entiende, o Agentes Autónomos que requieren atención constante del humano para operar. Un Asistente que en medio de la conversación lanza un Botlet en background sin notificar al usuario rompe la expectativa del usuario. Un Agente Autónomo que no puede ejecutar nada hasta que el humano abra la aplicación pierde el sentido de su autonomía. La distinción explícita en la arquitectura previene estas confusiones.
La segunda razón es que se cobran distinto. El Asistente típicamente vive bajo modelo de suscripción del usuario — el humano paga su Claude Pro, su ChatGPT Plus, su Copilot. La cognición se invoca durante las conversaciones. Para el sistema agentivo, esto significa que cada Asistente operando con suscripción del usuario tiene cuota disponible que el sistema no paga directamente. El Agente Autónomo típicamente vive bajo modelo de tokens centralizados del AgencyDomain — la organización paga el consumo agregado de los agentes que operan en su nombre. Para el sistema agentivo, esto significa costos predecibles pero materiales: cada decisión, cada validación, cada acción del Agente Autónomo consume tokens que la organización debe pagar.
Esta diferencia económica determina cuándo conviene cada modo. Si el caso de uso permite que el humano esté en el lazo, el Asistente bajo Suscripción del usuario es típicamente más barato — el costo lo absorbe el plan del usuario. Si el caso de uso requiere autonomía continua sin presencia humana, el Agente Autónomo bajo Tokens es la única opción viable, pero con costo predecible que la organización debe presupuestar. Confundir los modos lleva a errores económicos: Agentes Autónomos accidentalmente operando en modo Suscripción que agotan la cuota del usuario en horas, o Asistentes accidentalmente operando en modo Tokens que facturan al sistema lo que debería ir contra la suscripción del usuario.
La tercera razón es que se gobiernan distinto. El Asistente opera bajo control inmediato del humano. La validación es conversacional: el humano lee la respuesta antes de actuar, evalúa si es correcta, decide qué hacer con ella. La gobernanza es liviana — bastan permisos básicos. Si el Asistente comete un error, el humano lo nota inmediatamente y lo corrige. El Agente Autónomo opera sin control inmediato del humano. La validación debe ser sistémica: la organización confía en que el agente actúe correctamente cuando nadie está mirando. La gobernanza es robusta — exige los cinco pilares de Trust Infrastructure operacionalizados con disciplina. Si el Agente Autónomo comete un error, el humano lo descubre cuando ve el log o cuando la consecuencia se materializa, no en el momento.
Vender un Agente Autónomo con la gobernanza de un Asistente es vender un riesgo enmascarado de producto.
Esta es la razón estructural por la cual los productos que prometen “agentes autónomos” pero gobernanza de Asistente fracasan en producción enterprise. La organización compra esperando autonomía; recibe productos que necesitan supervisión humana constante. La frustración resultante es lo que alimenta la ola de cancelaciones que el Capítulo 2 documenta.
Anatomía operativa
Desplegamos el flujo operativo de cada modo para hacer la distinción concreta.
El Asistente
El flujo del Asistente es lineal y conversacional. El humano formula una solicitud. La cognición — Capa 2 — la recibe. La cognición aplica las Capabilities relevantes para entender el dominio de la solicitud. Si necesita información adicional, invoca tools. Compone la respuesta. La devuelve al humano. El humano sigue conversando o cierra la sesión. Cuando el humano se va, el Asistente no persiste — salvo que el sistema implemente memoria explícita (que es feature, no comportamiento default).
Lo característico del Asistente es que no opera cuando el humano no está presente. La cognición está disponible bajo demanda; cuando no hay demanda, no hay actividad. Esto es eficiente para casos de uso conversacionales pero es limitación severa para casos donde el trabajo necesita ejecutarse en momentos predecibles o ante eventos externos.
El Agente Autónomo
El flujo del Agente Autónomo es continuo y proactivo. El agente vive en background. Detecta estímulos del ambiente — cambios en datos, alertas, eventos. Cuando un estímulo activa una respuesta, aplica los Botlets relevantes. Si el Botlet ejecuta exitosamente, la operación termina. Si el Botlet falla o el caso es nuevo, el agente invoca cognición para resolver. Ejecuta la acción correspondiente — invoca un tool de Capa 4. Registra todo en el append-only log. Si la operación cruza umbrales de impacto definidos por política, escala al humano. Vuelve a esperar el siguiente estímulo.
Lo característico del Agente Autónomo es que vive persistente. Su vida es independiente de cualquier sesión humana. El agente opera mientras la organización opera, no solo cuando alguien le habla. Esto exige infraestructura de respaldo — persistencia de estado, monitoreo continuo, gobernanza activa — pero produce capacidad operativa que el Asistente no puede entregar.
¿Cómo cooperan en un sistema maduro?
Un sistema agentivo maduro contiene ambos modos y los compone. La composición típica funciona así: el Agente Autónomo opera continuamente en background ejecutando objetivos; el Asistente atiende solicitudes humanas que típicamente consultan el estado del Agente Autónomo o solicitan ajustes a su operación.
Cuando un CFO pregunta a su Asistente “¿cuál es el estado de cashflow esta semana?”, el Asistente no recalcula nada — consulta el estado que el Agente Autónomo financiero ha estado manteniendo continuamente. La conversación es rápida porque el trabajo pesado ya se hizo en background. El Asistente sirve como interfaz humana al estado que el Agente mantiene.
Cuando el mismo CFO ajusta los umbrales de cashflow — “de ahora en adelante, escalame cuando el saldo proyectado caiga bajo X” —, el Asistente comunica el ajuste al Agente Autónomo, que lo incorpora en su lógica continua. La interacción humana es momentánea; el efecto opera persistentemente.
Esta composición no es opcional para sistemas serios. Una organización que solo opera Asistentes tiene sistema agentivo limitado: los humanos deben pedir activamente cada cosa. Una organización que solo opera Agentes Autónomos tiene sistema agentivo intransigente: los humanos no pueden conversar con el sistema, solo recibir alertas o consultar logs. Sistemas maduros necesitan los dos modos cooperando.
Anti-patrones recurrentes
Tres anti-patrones recurrentes producen los fracasos que la industria documenta.
Anti-patrón A: vender Asistente como Agente Autónomo
Un producto que requiere que el humano lo invoque cada vez es Asistente, aunque su marketing diga “agente autónomo”. El criterio operativo es directo: si cuando el humano se desconecta el sistema deja de hacer trabajo, no es Agente Autónomo. Es Asistente. La consecuencia de este anti-patrón es que el cliente compra esperando autonomía y recibe asistencia con vocabulario inflado. La frustración subsiguiente es predecible: el cliente compara lo prometido con lo recibido, descubre la brecha, cancela.
Anti-patrón B: construir Agente Autónomo con arquitectura de Asistente
Un sistema que pretende ser autónomo pero opera invocando cognición en cada acción. Funciona en piloto. Falla en producción por costo y por velocidad. La economía detrás de este anti-patrón — por qué los Botlets son la respuesta arquitectónica que evita el colapso al escalar — se desarrolla en Capítulo 5 §2 (Botlets). Aquí basta retener el síntoma: si el sistema deja de funcionar económicamente cuando el volumen pasa de piloto a producción, está incurriendo en este anti-patrón.
Anti-patrón C: gobernar Agente Autónomo con políticas de Asistente
Asumir que basta con permisos básicos sobre datos cuando el agente opera autónomamente. Es error grave. El Agente Autónomo opera sin supervisión humana inmediata; necesita la gobernanza robusta descrita arriba —los cinco pilares de Trust Infrastructure—, no solo controles de acceso. La consecuencia: el agente actúa fuera de límites razonables sin que nadie lo note hasta el incidente. Es la causa típica de los comportamientos riesgosos que el Capítulo 2 documenta como mayoritarios en el campo.
La diferencia entre gobernanza de Asistente y gobernanza de Agente Autónomo es categórica. Para el Asistente, el humano que lee la respuesta antes de actuar cierra el lazo de validación; basta con que el sistema no permita acciones obviamente prohibidas. Para el Agente Autónomo, el humano no está en el lazo — la validación, la auditoría, los límites de impacto, la trazabilidad, todo debe ser sistémico (el pilar de Validación que suple ese lazo humano se desarrolla en el Capítulo 5 §4). Aplicar gobernanza de Asistente a un Agente Autónomo es construir sistema sin red de seguridad bajo el trapecio.
La evolución cooperativa
A medida que el sistema agentivo madura, la proporción de trabajo ejecutado por Agentes Autónomos crece respecto al ejecutado por Asistentes. Esta progresión es propiedad observable del campo, y refleja la transición de la organización a través de la Línea Nadella.
En las etapas tempranas, típicamente noventa por ciento del trabajo agentivo opera en modo Asistente: el humano sigue al timón, el Asistente lo ayuda con cada tarea, el Agente Autónomo es marginal. En las etapas de adopción, la proporción cambia a setenta por ciento Asistente y treinta por ciento Agente Autónomo: las primeras funciones — típicamente operacionales repetitivas — pasan a operación autónoma. En las etapas de madurez, la proporción se equilibra alrededor del cincuenta por ciento de cada modo: el Agente Autónomo opera funciones completas mientras el Asistente atiende consultas humanas. En las etapas avanzadas, la proporción se invierte — el Agente Autónomo ejecuta el setenta por ciento del trabajo y el humano interviene principalmente para definir reglas, supervisar, manejar excepciones.
La Línea Nadella separa al mundo donde dominan los Asistentes del mundo donde dominan los Agentes Autónomos.
Esta progresión es lo que el Capítulo 2 describió como la transición de la empresa en línea a la empresa en tiempo real. Una organización que vive con noventa por ciento de Asistentes es empresa en línea — humanos asistidos por IA que esperan ser invocados. Una organización que vive con setenta por ciento de Agentes Autónomos es empresa en tiempo real — sistemas que operan autónomamente con humanos gobernando el conjunto.
¿Cómo identificar el modo correcto?
Para una tarea dada, ¿conviene Asistente o Agente Autónomo? Cuatro criterios ayudan a decidir.
El primer criterio: ¿el humano debe ver cada decisión?. Si la respuesta es sí — porque la decisión requiere juicio humano, porque la responsabilidad regulatoria exige supervisión, porque el costo del error es muy alto —, conviene Asistente. Si la respuesta es no — porque la decisión es repetitiva con criterios claros, porque el volumen es demasiado alto para supervisión humana, porque la velocidad lo exige —, conviene Agente Autónomo.
El segundo criterio: ¿la tarea es disparada por el humano o por el ambiente?. Si la dispara el humano — el humano formula la pregunta, el humano solicita la operación —, conviene Asistente. Si la dispara el ambiente — un evento externo, un cambio en datos, una alerta de monitoreo —, conviene Agente Autónomo.
El tercer criterio: ¿la tarea es esporádica o continua?. Si es esporádica o variable — sucede pocas veces al día, en momentos impredecibles —, conviene Asistente. Si es continua o repetitiva — sucede muchas veces, con regularidad —, conviene Agente Autónomo.
El cuarto criterio: ¿importa la latencia conversacional?. Si el humano espera respuesta — la conversación tiene dinámica de turno-respuesta —, conviene Asistente. Si la operación se ejecuta en background sin presión de latencia inmediata, conviene Agente Autónomo.
La regla práctica que sintetiza los cuatro criterios: si los cuatro apuntan a Asistente, usar Asistente. Si los cuatro apuntan a Agente Autónomo, usar Agente Autónomo. Si la mezcla es ambigua, diseñar ambos modos cooperando: un Asistente que consulta el estado mantenido por un Agente Autónomo en background. Esta composición es la que sistemas maduros operan.
Conformidad
Una implementación que ofrece ambos modos conforme a esta especificación debe satisfacer:
| Requisito | Nivel |
|---|---|
| Distinguir explícitamente Asistente de Agente Autónomo en API y documentación | MUST |
| Asistente vive en Capa 2; no requiere Capa 3 | MUST |
| Agente Autónomo vive en Capa 3; persiste estado entre sesiones | MUST |
| Agente Autónomo ejerce los cinco pilares de Trust Infrastructure | MUST |
| Componibilidad: Asistente puede consultar estado del Agente Autónomo | SHOULD |
| Distinción de modelo de cobro entre los dos modos | SHOULD |
| Prevención de los tres anti-patrones | MUST |
Facetas
Las primitivas que las cinco secciones anteriores describieron — AgencyDomain, Botlet, Capability, Trust Infrastructure, Asistente vs Agente Autónomo — viven principalmente en las Capas 2, 3 y 4 de la Arquitectura Agentiva. La Capa 1 (Interacción) había quedado sin una primitiva propia: solo descrita como regímenes de generación (Capítulo 4 §1) y como composición de Botlets de presentación (shell, vista, operación). Faltaba nombrar la pieza atómica con que esas superficies se construyen.
Esta sección formaliza la Faceta como sexta primitiva canónica — la unidad mínima de la Capa 1, instrumento que el agente invoca durante conversación o ensambla en Botlets de presentación.
El Botlet es memoria muscular del agente. La Faceta es instrumento que el agente toma mientras piensa.
Definición
Una Faceta es un componente atómico reusable de la Capa 1 (Interacción) que ofrece al usuario una forma específica de interacción no conversacional: una pizarra de dibujo a mano alzada, un catálogo-selector, una matriz de colores, un calendario, un mapa clickeable, un slider, un ordenamiento drag-and-drop, un selector de archivos, una vista de canvas configurable. Una de las muchas caras que la interacción con el usuario puede tomar en un momento dado.
La Faceta es instrumento, no proceso. Vive y opera en la Capa 1. Es invocada por la cognición durante interacciones activas o ensamblada por Botlets de Capa 1 (shells y vistas) como pieza de su composición interna.

Faceta vs Botlet — la distinción canónica
La Faceta y el Botlet son dos primitivas de software del agente. Se confunden fácil porque ambas son piezas con identidad propia que el agente usa para hacer cosas. La distinción canónica:
| Eje | Faceta | Botlet |
|---|---|---|
| Capa | Capa 1 (Interacción) | Capa 3 (Autonomía) |
| Naturaleza | Instrumento de interacción | Memoria muscular del agente |
| ¿Cuándo opera? | Durante conversación activa | En background, sin cognición presente |
| Activación | Cognición la invoca explícitamente | Pattern Recognition o llamado externo |
| Garantía de fallback | NO — si falla, agente vuelve a texto | SÍ — la cognición ejecuta manualmente |
| Ciclo de vida | Efímera (vive lo que dura la tarea) | Persistente entre sesiones |
| Regeneración | No tiene ciclo de regeneración | Ciclo 95/4/1 con regeneración |
| Fases de madurez | No aplica | Junior · en aprendizaje · senior |
| Reutilización | Catálogo plano de instrumentos | Catálogo por capacidad y dominio |
La diferencia ontológica importa: el Botlet automatiza; la Faceta interactúa. Un Botlet ejecuta saber consolidado sin participación humana inmediata. Una Faceta abre un canal de comunicación visual-manipulativa con un humano que está activo en la conversación.
Dos usos canónicos
Uso 1 · Invocación directa por la cognición
El agente, durante una conversación, decide que la información que necesita del usuario se obtiene más rápido a través de una Faceta que continuando el diálogo verbal. Compone una superficie efímera con una o varias Facetas, la presenta al usuario, recibe la información, y la conversación continúa. La superficie efímera no es un Botlet y no persiste — vive lo que dura la tarea inmediata.
Este uso realiza directamente el régimen GUI generada on-the-fly del Capítulo 4 §1. La Faceta es la pieza que materializa ese régimen.
Uso 2 · Composición en Botlets de presentación
Los Botlets de shell y vista (Capítulo 4 §1, Composición de la Capa 1) ensamblan Facetas como piezas internas de su construcción. La vista de “detalle de pedido” usa la Faceta de “matriz de productos” + la Faceta de “calendario” + la Faceta de “selector de cliente”. El Botlet de vista define la orquestación, el layout, el flujo de datos entre piezas; las Facetas son los instrumentos individuales que el Botlet pone en la pantalla.
Este uso permite que las superficies persistentes (régimen 3 del Capítulo 4 §1) se construyan reutilizando catálogo de Facetas, sin que cada Botlet de vista tenga que reinventar cada componente atómico.
Interacción declarada acotada
Una pieza de información ya materializada — un snapshot autocontenido que el agente forjó en su tiempo de Ingeniería — puede portar interacción sobre sus propios datos sin dejar de ser una pieza reproducible. Pero no toda interacción es del mismo tipo. La interacción declarada acotada es la categoría que separa lo que una pieza puede ofrecer de lo que pertenece a otra primitiva.
La distinción se traza entre dos interactividades:
- La exploración libre lanza queries nuevas y
arbitrarias al origen (drill o pivot ad-hoc), opera sobre un espacio
abierto, pierde reproducibilidad, excede
G1(las generaciones del Botlet, Capítulo 5 §2) y vive fuera del proto-Botlet de información — en otro Botlet o en la cognición misma. Una pieza de información MUST NOT absorberla. - La interacción declarada acotada opera sobre el
snapshot ya materializado, dentro de un espacio declarado (dimensiones y
valores acotados de antemano), mantiene la reproducibilidad, es
G1—configuración, no código— y vive en la pieza misma, realizada vía Faceta.
| ¿Qué las distingue? | Exploración libre | Interacción declarada acotada |
|---|---|---|
| Query nueva al origen | sí, arbitraria (drill/pivot ad-hoc) | no — opera sobre el snapshot ya materializado |
| Espacio de interacción | abierto | declarado (dimensiones y valores acotados) |
| Reproducibilidad | se pierde | se mantiene (misma config + datos → mismo artefacto + mismo set de controles) |
| Generación | excede G1 |
G1 (es configuración, no código) |
| ¿Dónde vive? | otro Botlet / cognición (Capa 2 + Capa 1) | en la pieza misma, vía Faceta |
Faceta embebida
El mecanismo que realiza la interacción declarada acotada ya es
canónico: es la composición de Facetas (Uso 2), aplicada hacia adentro
de una pieza materializada. Es la pieza la que compone
la Faceta — no la Faceta la que compone otras —; la Faceta sigue siendo
atómica. Una Faceta embebida es una Faceta acotada a
una dimensión declarada de los propios datos de la pieza — un filtro, un
segmentador, un selector de apariencia. Al activarla, los elementos
data-bound de la pieza —KPIs y medidas como agregaciones
declaradas (sum, ratio, y similares) sobre el
dataset embebido, distribuciones, semáforos— se recomputan
client-side sobre el subconjunto filtrado: la agregación se
declara una vez y se reevalúa al cambiar el subconjunto. La cognición no
explora; la Faceta filtra el snapshot.
El caso testigo es un dashboard de asistencia con filtro por área: el usuario elige una o varias áreas y la pieza recalcula sus KPIs y su semáforo sobre el subconjunto.
Esto reconoce un tercer uso de la Faceta — extensión del Uso 2 hacia la pieza materializada —: la distinción Faceta vs Botlet admite este tercer uso sin alterar la naturaleza de la Faceta, que sigue siendo efímera y sin garantía de fallback. Lo nuevo es que la pieza puede componerla para interacción acotada, además de la invocación por la cognición durante conversación.
Comportamiento agentivo asociado
La existencia de la Faceta como primitiva canónica habilita un comportamiento agentivo específico: el agente, durante una conversación, estima en tiempo real si la información que necesita se obtiene mejor verbalmente o visualmente. Cuando estima que la vía visual gana, ofrece una Faceta apropiada.
El cálculo es cognitivo del agente, no feature pre-programada del producto. La Faceta como primitiva habilita la decisión; la heurística la ejerce.
Heurísticas canónicas para invocación
| Naturaleza de la información | Modalidad recomendada |
|---|---|
| Baja dimensionalidad + bien estructurada (un sí/no, una fecha, un número) | Conversación |
| Alta dimensionalidad (múltiples campos relacionados) | Faceta de formulario o composición |
| Difícil de verbalizar (color, posición, forma, gesto) | Faceta especializada (matriz de colores, mapa, dibujo) |
| El usuario ya la tiene en forma espacial o visual (un layout, un mapa, un dibujo en papel) | Faceta que reciba esa forma directamente |
| Comparación entre opciones múltiples | Faceta de catálogo-selector con vista comparativa |
| Configuración con muchas dimensiones independientes | Faceta de panel con sliders y toggles |
| Trabajo creativo abierto (no respuesta a pregunta cerrada) | Faceta de canvas o lienzo |
Anti-heurísticas (cuándo NO ofrecer Faceta)
- Cuando la pregunta es genuinamente cerrada y verbal — ofrecer Faceta agrega fricción, no la reduce.
- Cuando el usuario está en un canal sin capacidad gráfica (voz pura, IVR, SMS) — la Faceta no es invocable.
- Cuando el costo de cargar la Faceta supera el beneficio de la interacción visual (interacciones de un solo paso, datos triviales).
- Cuando la conversación está en flujo y la Faceta interrumpe inadecuadamente.
El agente que aprende a calibrar estas decisiones — cuándo ofrecer, cuándo no — opera en una Capa 1 plena. El que solo conversa se queda en la mitad del rango interactivo posible.
Cuando una Faceta se compone dentro de una pieza materializada (interacción declarada acotada), la decisión deja de ser conversacional y pasa a ser parte de la configuración de la pieza: el agente declara el espacio de controles en tiempo de Ingeniería, preservando la reproducibilidad —propiedad MUST del artefacto de información— ya establecida arriba.
Anatomía de la Faceta
La especificación canónica de una Faceta incluye seis componentes:
- Identidad — nombre canónico (ej:
pizarra-dibujo,matriz-colores,calendario-rango) más versión. - Modalidad de interacción — qué tipo de input acepta (touch, mouse, teclado, gesto), qué tipo de output produce.
- Schema de entrada — los datos que el invocador (cognición o Botlet de vista) le pasa al instanciarla.
- Schema de salida — los datos que devuelve cuando el usuario completa su interacción.
- Estado interno — qué mantiene mientras está activa (selecciones intermedias, edits parciales, undo stack).
- Compatibilidad de canal — qué canales de Capa 1 la soportan (web, móvil, kiosk, no soportada en voz).
Las Facetas se publican en un catálogo plano: no hay jerarquía de Facetas porque cada una es atómica. Lo que hay es un set creciente de instrumentos disponibles, indexados por modalidad y por dominio de aplicación.
Catálogo emergente
La industria converge gradualmente hacia un set canónico de Facetas reusables — el equivalente del catálogo de componentes de UI de las eras pre-agentivas (Material, Bootstrap, Ant Design), pero con la diferencia ontológica de que estos componentes son invocables por la cognición y no se sirven solo para construir aplicaciones humanamente programadas.
Algunas Facetas canónicas emergentes:
pizarra-dibujo— superficie de dibujo a mano alzada.catalogo-selector— vista de items con selección.matriz-colores— selector de paleta o color individual.calendario-rango— selector de fecha o rango de fechas.mapa-clickeable— mapa con puntos seleccionables.slider-multi— uno o varios sliders relacionados.dragdrop-orden— reordenamiento de items.formulario-dinamico— formulario con campos generados al vuelo.lienzo-creativo— canvas abierto para producción de artefactos.selector-archivo— invocación al sistema de archivos del cliente.
La spec no cierra el catálogo: nuevas Facetas se acuñan a medida que la industria identifica modalidades canónicas que justifican primitiva propia.
Conformidad
Una implementación de Facetas conforme a esta especificación debe satisfacer:
| Requisito | Nivel |
|---|---|
| Identidad y versión declaradas | MUST |
| Schema de entrada y salida explícito | MUST |
| Compatibilidad de canal declarada | MUST |
| Atomicidad — no compone otras Facetas internamente | MUST |
| Distinción explícita Faceta vs Botlet en documentación | MUST |
| Invocabilidad directa por la cognición durante conversación | MUST |
| Composabilidad dentro de Botlets de shell y vista | MUST |
| Compuesta en una pieza materializada como interacción declarada acotada (espacio de controles declarado, sin queries nuevas) | MAY |
| Preservación de la reproducibilidad de la pieza cuando se compone como Faceta embebida (recómputo client-side, sin invocar Capabilities) | MUST |
| Catálogo público de Facetas disponibles para el AgencyDomain | SHOULD |
| Heurísticas de invocación documentadas para la cognición | SHOULD |
Frontera de evolución
Tres áreas activas de evolución de la Faceta como primitiva merecen mención.
La estandarización de catálogo es la primera. La industria todavía no ha consolidado un set canónico universal de Facetas. Cada plataforma agentiva define el suyo, con intersecciones parciales. La emergencia de un catálogo común con identidades estables permitiría agentes operar sobre cualquier AgencyDomain conforme.
La federación de Facetas es la segunda. Cuando dos AgencyDomains colaboran (federación, Capítulo 5 §1), las Facetas que uno expone deben poder invocarse desde el otro. La spec no define todavía un protocolo formal para invocación federada de Facetas — es trabajo abierto.
La negociación de canal es la tercera. Una Faceta declara qué canales soporta. La cognición debe negociar — si el usuario está en voz, no puede ofrecer la Faceta; debe degradar a conversación. Sin esta negociación explícita, las superficies fallan en canales no esperados. La spec exige declaración pero no formaliza aún el protocolo de degradación.
Agentlets
En la entrada de una sala de urgencias hay una enfermera de triaje. Su tarea es la misma todo el día: recibir al paciente, evaluarlo, clasificarlo — rojo, amarillo, verde — y derivarlo. La tarea es repetitiva en su forma; ninguna repetición es igual a la anterior. Cada paciente llega con síntomas distintos, historias distintas, señales que no están en ningún manual exactamente como se presentan. La enfermera no puede resolver su trabajo con memoria muscular — cada clasificación exige juicio fresco —, pero tampoco necesita al jefe de medicina interna para cada paciente: su juicio opera dentro de un protocolo acotado, y cuando el caso excede el protocolo, escala. La enfermera de triaje no es un reflejo ni es la deliberación plena del hospital. Es una tercera cosa: juicio de rutina, empaquetado en un rol.
Los sistemas agentivos están llenos de trabajo con esa forma. Clasificar los correos que llegan a una casilla operativa. Hacer triaje de las alertas de monitoreo. Resumir cada documento nuevo que entra a un expediente. Extraer las entidades de una factura que nunca se había visto. Juzgar si un mensaje amerita interrupción inmediata o espera al reporte de la mañana. Son tareas recurrentes en su forma pero frescas en cada instancia: el patrón es estable, la ejecución exige interpretación. No maduran hacia el determinismo — no por falta de regeneraciones, sino por naturaleza.
El canon, hasta aquí, les daba dos casas y ninguna era la correcta. La primera casa es el Botlet: pero el Botlet es código no-LLM por definición, y forzar una tarea interpretativa a código determinístico produce exactamente la fragilidad que la arquitectura existe para evitar. La segunda casa es la Cognición plena de la Capa 2: funciona, pero al costo de la vía más cara del sistema — deliberativa, conversacional, dimensionada para lo genuinamente nuevo — aplicada a un patrón que se repite cien veces al día. Entre la memoria muscular y la deliberación plena faltaba el peldaño del medio.
Esta sección formaliza el Agentlet como octava primitiva canónica — la unidad hermana del Botlet cuyo cuerpo de ejecución invoca inferencia acotada. El Agentlet es la casa del juicio de rutina: patrón empaquetado por fuera, juicio acotado por dentro.
El Botlet es memoria muscular. El Agentlet es juicio de rutina empaquetado. La Cognición se reserva para lo genuinamente nuevo.
Definición
Un Agentlet es una unidad empaquetada de la Capa 3 (Autonomía), hermana del Botlet, cuyo cuerpo de ejecución invoca inferencia acotada: un modelo dimensionado a la tarea, aplicado dentro de un charter que el spec declara. Como el Botlet, es instancia configurada de una pieza pre-forjada — el proto-Agentlet —, es hospedado por el Botler y es engendrado y mantenido por el agente. A diferencia del Botlet, cada una de sus ejecuciones ejerce juicio: interpreta la instancia concreta que tiene delante en lugar de ejecutar código determinístico.
La frase que fija la doctrina de hermandad: un Agentlet es un
Botlet con juicio adentro — ni más ni menos. Vive exactamente
como su hermano. Hereda por estructura, no por excepción, todo el
aparato de los Lets — las unidades empaquetadas de la Capa 3 —: el
patrón proto-/instancia, los catálogos y sus efectos de red, la
separación código fuente vs spec, la manifestación y la
temporalidad
(discreta/continua), el contrato declarativo
de calidad, la cadena de derivación, el append-only log y los verbos del
API de operación (specialize ·
invoke/schedule ·
read/subscribe ·
status/activate/deactivate/retire).
Lo que cambia es un solo atributo — el cuerpo invoca inferencia — y de
ese atributo se siguen, en cascada, las diferencias que el resto de la
sección desarrolla.
Cuatro propiedades definen al Agentlet conforme. La primera es que su charter está declarado en el spec: qué tarea resuelve, sobre qué entradas, con qué salidas, dentro de qué límites. El Agentlet no elige qué hacer — su inferencia se gasta en cómo hacer lo suyo, nunca en decidir qué es lo suyo. La segunda es que su inferencia es acotada: el spec declara el modelo (dimensionado a la tarea, no el modelo frontera de la Cognición), las Capabilities que puede consultar y el presupuesto por ejecución. La tercera es que toda su inferencia pasa por el Botler: el handle controlado que el Botler le entrega incluye el punto de control de cognición, de modo que cada llamada al modelo queda medida, presupuestada, validada y auditada — el bypass es estructuralmente imposible, no solo prohibido. La cuarta es que tiene garantía de fallback hacia la Cognición plena: cuando su inferencia acotada no resuelve el caso — el charter no alcanza, la confianza del veredicto queda bajo umbral, la entrada no se parece a nada previsto —, el Agentlet escala y la Cognición de Capa 2 rescata. El proceso nunca se detiene.
La regla de contrabando
La frontera entre el Botlet y el Agentlet es un atributo binario, y la spec la protege en ambas direcciones:
- Si hay inferencia en el cuerpo, es Agentlet. Un Botlet con una llamada a modelo escondida en su código es no-conforme — contrabandea costo y no-determinismo hacia una unidad cuyas garantías (costo marginal cero, madurez que converge, offline senior) dependen de no tenerlos.
- Si no hay inferencia en el cuerpo, es Botlet. Un Agentlet cuyo charter resultó resoluble con código determinístico es un Botlet mal clasificado — y mal presupuestado: paga tokens por un trabajo que la memoria muscular haría gratis. La cognición, al detectarlo, lo cristaliza: genera el Botlet que lo reemplaza.
La segunda dirección de la regla describe además una trayectoria natural: hay tareas que ingresan al sistema como Agentlets — porque al inicio cada instancia parecía exigir juicio — y que, con la operación acumulada, revelan un núcleo cristalizable. La cognición extrae ese núcleo a un Botlet y deja al Agentlet solo el residuo genuinamente interpretativo, o lo retira por completo. El sistema maduro migra trabajo hacia abajo en la escalera del costo: de la Cognición a los Agentlets, de los Agentlets a los Botlets.
Agentlet vs Botlet — la distinción canónica
| Eje | Botlet | Agentlet |
|---|---|---|
| Cuerpo de ejecución | Código no-LLM; cero inferencia | Invoca inferencia acotada, vía el handle del Botler |
| Metáfora | Memoria muscular | Juicio de rutina empaquetado |
| Tarea natural | Recurrente y cristalizable en código | Recurrente en forma, interpretativa en cada instancia |
| Determinismo | Converge con la madurez | No converge — la corrección es estadística por naturaleza |
| Costo marginal | ~0 (cómputo tradicional) | Tokens por ejecución, presupuestados en el spec |
| Madurez | Junior → senior; senior = fallos solo exógenos | Semántica propia: spec estabilizado, tasa de escalamiento decreciente |
| Offline | Senior operable offline confiablemente | Solo con modelo edge-resident, declarado en el spec |
| Fallback | La cognición ejecuta manualmente | Escala a la Cognición plena |
Lo que la tabla no contiene es tan importante como lo que contiene: proto-/instancia, catálogos, spec, manifestación, temporalidad, contrato de calidad, cadena de derivación, log, verbos de operación, hospedaje por el Botler, génesis por el agente — todo eso es idéntico, porque se predica del género y no de la especie. La spec llama al género por su nombre propio: los Lets — el Botler hospeda Lets; el Botlet y el Agentlet son sus dos especies. El nombre deriva de la morfología de la propia familia y es, como Botler, vocabulario normado del canon — no una novena primitiva. La relación canónica del runtime se enuncia en su forma general — 1 Proceso = 1 Botler + N Lets — y cada contexto la instancia a la especie que corresponda.
Agentlet vs Agente — agenda vs charter
El nombre de la primitiva reclama membresía en la familia del Agente, y la spec se la concede: el término paraguas Agente cubre, desde esta versión del canon, tres miembros — el Asistente (Capa 2, reactivo), el Agente Autónomo (Capa 3, proactivo, habitante) y el Agentlet (Capa 3, empaquetado). La concesión es honesta — la criatura razona de verdad, con un modelo de verdad — pero exige trazar la frontera con el Agente Autónomo con el mismo rigor con que el canon trazó Faceta vs Botlet, porque los dos viven en la misma capa y los dos usan inferencia.
La frontera cabe en una línea: el Agente tiene agenda; el Agentlet tiene charter. El Agente Autónomo persigue objetivos — decide qué hacer, cuándo, con qué medios, y engendra las unidades que necesita. El Agentlet ejecuta la tarea que su spec declara — su juicio opera dentro del charter, jamás sobre el charter.
| Eje | Agente Autónomo | Agentlet |
|---|---|---|
| Naturaleza | Habitante del AgencyDomain | Pieza de catálogo — instancia de un proto |
| Nace por | Provisioning (ciclo de vida de seis fases, identidad de primer orden) | specialize sobre un proto-Agentlet |
| Agenda | Persigue objetivos; decide qué hacer y cuándo | Charter fijo declarado en el spec |
| Cognición | Plena: bindings propios, árbol completo de Capabilities, multi-LLM | Acotada: modelo dimensionado, Capabilities que el spec declara |
| Engendra | Genera y regenera Botlets y Agentlets | No engendra nada; es mantenido |
| Fallback | Es el fallback — encima de él solo está el humano | Escala a la Cognición vía el Botler |
| Gobernanza | Ejerce los cinco pilares de Trust Infrastructure (MUST) | Gobernado por los puntos de control del handle del Botler |
El test de frontera protege la categoría de desangrarse hacia arriba. Tres preguntas; cualquier respuesta del lado de la autonomía significa que la pieza es un Agente, no un Agentlet:
- ¿Elige sus propias metas, o las recibe declaradas en el spec?
- ¿Puede alterar su propio proceso o engendrar otros Lets?
- ¿Su identidad es de habitante (provisioning) o de instancia
(
specialize)?
Un Agentlet con charter gordo, un loop interno y criterio propio sobre qué perseguir no es un Agentlet avanzado: es un Agente Autónomo disfrazado, operando sin la gobernanza que su naturaleza exige — la versión agentiva del anti-patrón C del §5.
El Botler como tutor — mismo runtime, un punto de control más
El Agentlet no trae runtime propio. Lo hospeda el mismo
Botler que hospeda a los Botlets, y esta decisión es de
principio, no de conveniencia. El Botler es genérico por definición:
gestiona ciclo de vida, aislamiento y ejecución de cualquier unidad sin
entender su dominio — y llamar a un modelo no es dominio; es un servicio
de runtime. La extensión sigue el patrón que el Botler ya practica:
junto a capability_call y log, el handle
controlado que el Botler entrega en cada invocación expone un tercer
punto de control — cognition_call —, la
única vía por la cual el cuerpo del Agentlet alcanza un modelo.
La consecuencia de gobierno es el argumento entero: como toda la inferencia del Agentlet pasa por el handle, Trust Infrastructure la ve completa. Cada llamada al modelo queda medida (tokens, latencia), presupuestada (contra el límite que el spec declara), validada (los mecanismos del Pilar 3 — detección de alucinaciones, DLP, tokenización — aplican en el punto de control) y auditada (en el mismo append-only log, con la misma identidad, bajo el mismo gobierno que el resto del AgencyDomain). Un runtime paralelo para Agentlets tendría que duplicar toda esa maquinaria — segundo sandbox, segundo esquema de handle, segunda cadena de escalamiento, segunda presencia en la Capa 3 distribuida — para terminar entregando las mismas garantías. La arquitectura plana del Botler ya las entrega.
La preocupación legítima que podría empujar hacia un runtime separado — el perfil de recursos: latencia de modelo, costo por token, eventual aceleración por hardware — es asunto de despliegue, y el canon ya tiene la puerta abierta: los subtipos de Botler se distinguen por topología y rol de despliegue, nunca por dominio. Un pool de ejecución segregado para Lets de inferencia pesada es exactamente una distinción de rol de despliegue: un Botler conceptual, N procesos si la operación lo pide.
Conviene dejar explícitas las dos relaciones que sostienen a los Lets, porque operan en pisos distintos y las dos cubren a las dos especies por igual:
| Relación | ¿Quién la ejerce? | Sobre Botlets | Sobre Agentlets |
|---|---|---|---|
| Hospedaje / ejecución — runtime sin agencia: ciclo de vida, aislamiento, handle controlado, log | El Botler | Sí | Sí (mismo handle, más cognition_call) |
| Génesis / mantenimiento — decidir que exista, especializarlo, regenerarlo, responder por él | El agente (la cognición) | Sí | Sí |
El agente es el padre de ambas especies; el Botler es el mayordomo de ambas. Ningún Let tiene casa aparte.
Madurez del Agentlet — estabilización, no convergencia
La trayectoria junior → senior del Botlet converge porque cada regeneración cristaliza variantes en código: el senior es determinístico y por eso sus únicos fallos son exógenos. El Agentlet no recorre esa trayectoria — su corrección es estadística por naturaleza y ninguna cantidad de operación la vuelve determinística. Pretender que un Agentlet “madura a senior” en el sentido del Botlet es un error de categoría con consecuencias operativas: nunca se le puede prometer la confiabilidad offline del Botlet senior sobre la misma base.
La spec define para el Agentlet una semántica de madurez propia, observable en el mismo append-only log que ya rastrea a los Botlets:
- Estabilización del spec — el charter, el prompt
operativo y la configuración dejan de cambiar entre revisiones; las
ediciones del
specializese espacian. - Tasa de escalamiento decreciente — la fracción de
ejecuciones que el Agentlet resuelve dentro de su charter sin escalar a
la Cognición plena crece y se estabiliza. Es el análogo funcional del
95/4/1: la proporción entre juicio acotado que basta y juicio pleno que rescata. - Calidad sostenida bajo el contrato declarativo — sus atributos de calidad declarados (frescura, SLA, degradación) se cumplen dentro de umbral por período sostenido.
El offline del Agentlet exige declaración explícita, no herencia del hermano. Un Botlet senior opera offline porque no necesita ningún modelo; un Agentlet solo opera offline si su modelo reside en el edge. El spec de todo Agentlet conforme MUST declarar la localidad de su cognición acotada — cloud-resident, edge-resident o híbrida, con el mismo vocabulario que la spec ya usa para los Conectores — y su comportamiento sin red. Sin esa declaración, la consecuencia «modo offline trivial» de la topología paralela se rompe en silencio: el sitio que contaba con su vía Autonomía descubre, con la red caída, que la mitad de sus unidades necesitaba un modelo al otro lado del cable.
proto-Agentlet — la pieza pre-forjada del juicio
Como su hermano, el Agentlet rara vez nace de la nada: nace de un proto-Agentlet — la pieza pre-forjada que el agente configura en su tiempo de Ingeniería para instanciar un Agentlet específico al caso. El proto-Agentlet contiene el cuerpo (el andamiaje de la tarea interpretativa: la estructura del charter, el esqueleto del prompt operativo, los contratos de entrada y salida, los umbrales de escalamiento); el Agentlet es la instancia configurada. Las dos clases del proto-Botlet aplican sin cambio: un proto-Agentlet templado resuelve una función interpretativa y se configura por parametrización acotada (un clasificador de correo operativo, un extractor de campos de factura); un proto-Agentlet platafórmico es un motor de juicio genérico cuya especialización vive en configuración composicional y cubre N funciones de su dominio.
La cadena de derivación se extiende sin fricción: los casos de uso documentados requieren Lets — cero, uno o varios, de cualquiera de las dos especies —, y cada Let es instancia de algún proto del catálogo. Todo Agentlet conforme MUST poder trazarse en esa cadena, y el append-only log MUST registrar el proto-Agentlet de origen de cada instancia. Los catálogos comunes — público abierto en AgencyDomains.org, códices propietarios, contratos privados, acuerdos soberanos — acumulan proto-Agentlets con los mismos efectos de red que acumulan proto-Botlets: el implementador n+1 recibe charters, prompts operativos y umbrales refinados por los implementadores 1 a n.
Las generaciones
(G1/G2/G3) aplican con una
lectura natural: en G1 el agente configura el
proto-Agentlet — rellena el charter, ajusta el prompt operativo dentro
del andamiaje, fija umbrales — sin escribir su cuerpo. El filo
G1/G2 es el mismo del Botlet: configuración
que una Capability bien definida evalúa es G1; extensión de
la lógica interna del proto es G2.
La economía de los tres peldaños
Con el Agentlet, la escalera económica del sistema agentivo queda completa. El Capítulo 4 presentó dos vías — Cognición costosa, Autonomía barata —; la vista fina distingue tres peldaños de costo por ejecución:
| Peldaño | Unidad | Inferencia | Costo marginal |
|---|---|---|---|
| 1 | Botlet | Cero | ~0 — cómputo tradicional |
| 2 | Agentlet | Acotada: modelo dimensionado, presupuesto declarado | Bajo y presupuestable por Let |
| 3 | Cognición | Plena: deliberativa, modelo frontera, árbol completo | Alto — se reserva para lo nuevo |
El peldaño intermedio es el que faltaba. Sin él, toda tarea interpretativa recurrente pagaba precio de peldaño 3 — o se forzaba, frágil, al peldaño 1. Con él, la organización asigna cada patrón a su costo natural, y el sistema maduro migra trabajo escalera abajo: la Cognición cede rutinas interpretativas a Agentlets; los Agentlets ceden núcleos cristalizables a Botlets.
La entrada del Agentlet matiza, no rompe, la promesa económica de la vía Autonomía. La vía sigue siendo la barata — pero deja de ser uniformemente gratuita: contiene Lets de costo marginal ~0 y Lets de costo acotado, y el mix se declara por Let, no se promedia. Bajo planes de Suscripción fija, el argumento del Capítulo 5 §2 se refina en el mismo sentido: los Botlets siguen siendo el mecanismo que hace posible la autonomía sostenida sin agotar la cuota, y los Agentlets consumen cuota — acotada, presupuestada, visible en el log — por lo que su proporción en el mix es una decisión económica explícita de la organización, exactamente como lo es la decisión de qué patrones consolidar en Botlets.
Hay una segunda consecuencia transversal: el pilar de
Validación gana presencia en la Capa 3. Hasta esta versión del
canon, la Validación se ejercía en la Capa 2 (parcial) y en la Capa 4
(principal), porque la Capa 3 solo contenía código determinístico. Con
los Agentlets entra corrección estadística a la zona de la memoria
muscular — exactamente la volatilidad que la Bounded Concerns
Architecture (Capítulo 3) enseña a confinar —, y los mecanismos del
Pilar 3 (detección de alucinaciones, validación de salidas
estructuradas, DLP, tokenización) aplican en el punto de control
cognition_call del Botler, sobre cada ejecución de cada
Agentlet. La delgadez del dominio se preserva: el juicio estadístico
queda confinado a Lets declarados, gobernados y auditables, nunca
disperso por el runtime.
¿Cuándo usar Agentlet — y cuándo no?
La decisión entre las tres casas — Botlet, Agentlet, Cognición — se resuelve con dos preguntas en cascada:
Primera: ¿la tarea es recurrente? Si no — si es única, exploratoria, o su patrón todavía no se estabiliza —, pertenece a la Cognición. La regla práctica de las diez invocaciones del §2 aplica a las dos especies de unidad por igual.
Segunda: ¿cada instancia exige juicio? Si no — si la lógica es cristalizable en código determinístico —, Botlet, siempre: es el peldaño más barato y el único que madura hacia el offline confiable. Si sí — si el patrón es estable pero cada ejecución interpreta una instancia nueva —, Agentlet.
Tres señales confirman que una tarea es territorio de Agentlet: la entrada es lenguaje natural o contenido no estructurado (correos, documentos, transcripciones, descripciones libres); la salida exige clasificar, resumir, extraer o juzgar más que calcular o transportar; y los intentos de resolverla con reglas producen listas de excepciones que crecen sin converger. Y dos anti-señales devuelven la tarea a sus vecinos: si el “juicio” resultó ser una tabla de decisión estable, es un Botlet que todavía no se cristaliza; si el charter no logra declararse — la tarea exige decidir qué hacer, no solo cómo —, es trabajo de Agente, con la gobernanza de Agente.
Conformidad
Una implementación de Agentlet conforme a esta especificación debe satisfacer:
| Requisito | Nivel |
|---|---|
| Charter declarado en el spec: tarea, entradas, salidas, límites | MUST |
| Inferencia acotada declarada: modelo, Capabilities accesibles, presupuesto por ejecución | MUST |
Toda inferencia cursada por el punto de control
cognition_call del handle del Botler |
MUST |
| Garantía de fallback: escalamiento a la Cognición plena ante caso fuera de charter o confianza bajo umbral | MUST |
| Cero inferencia fuera del handle (la regla de contrabando, dirección Botlet→Agentlet) | MUST |
| Hospedaje por el Botler genérico — sin runtime paralelo por especie | MUST |
| Trazabilidad: cada ejecución y cada llamada de inferencia en el append-only log | MUST |
| Trazable en la cadena casos-de-uso → Lets → protos; proto-Agentlet de origen registrado | MUST |
| Declaración de localidad de la cognición acotada (cloud / edge / híbrida) y comportamiento offline | MUST |
| Validación del Pilar 3 aplicada en el punto de control de cognición | MUST |
| Distinción explícita Agentlet vs Agente Autónomo en API y documentación (el test de frontera) | MUST |
| Métricas de madurez propias: estabilización del spec y tasa de escalamiento | SHOULD |
| Cristalización: detección de núcleos deterministas y extracción hacia Botlets | SHOULD |
| Pool de ejecución segregado por perfil de recursos (rol de despliegue) | MAY |
Frontera de evolución
Tres áreas activas de evolución del Agentlet merecen mención al cierre.
Los modelos edge para juicio acotado son la primera. La viabilidad del Agentlet offline depende de modelos pequeños ejecutando en el sitio físico con calidad suficiente para charters acotados. El estado del arte avanza rápido; la spec ya provee el vocabulario de declaración (localidad de la cognición acotada) para que las implementaciones adopten modelos edge sin cambio de contrato.
La calibración de confianza es la segunda. El escalamiento del Agentlet a la Cognición plena depende de que el propio Agentlet estime cuándo su veredicto no alcanza el umbral — un problema de calibración estadística abierto. Mientras madura, las implementaciones conservadoras compensan con umbrales bajos: escalar de más cuesta tokens; escalar de menos cuesta confianza.
La cristalización asistida es la tercera. La detección automática de núcleos deterministas dentro de charters de Agentlet — la trayectoria Agentlet → Botlet de la regla de contrabando — es hoy juicio de la cognición en su tiempo de Preparación. Su formalización como mecanismo de Pattern Recognition inverso (detectar lo que dejó de necesitar juicio) es trabajo abierto.
Con el Agentlet cierra el elenco de construcciones formales de este capítulo — ocho primitivas canónicas: AgencyDomain, Botlet, proto-Botlet, Agentlet, Capability, Trust Infrastructure, la distinción Asistente vs Agente Autónomo y la Faceta. Quien haya seguido los Capítulos 4 y 5 tiene en mano el vocabulario constructivo completo con el que la categoría agentiva puede ser razonada y construida — desde el espacio computacional que lo contiene todo hasta la escalera de tres peldaños por la que el trabajo encuentra su costo natural.
El Capítulo 6 desplaza la mirada del sistema individual al mercado. Permite a quien construye o invierte responder con disciplina la pregunta de dónde compite cada actor — propio o ajeno — y por qué un mismo eslabón de la cadena puede ser zona muy disputada o territorio aún abierto.