Capítulo 7 · Conocimiento en tiempo real
Hay un problema que casi cualquier ejecutivo serio de una empresa mediana o grande reconoce de inmediato cuando se le describe: la lentitud insufrible del acceso al conocimiento sobre su propio negocio. El ejecutivo tiene una intuición sobre algo que está pasando — los márgenes parecen estar cayendo, el churn parece estar subiendo, una región parece estar comportándose distinto de las otras —, formula la pregunta a su área de BI, y la respuesta llega entre dos y ocho semanas después. Para entonces, la decisión que motivó la pregunta ya pasó. La organización quedó operando con la intuición sin verificar.
Este capítulo trata sobre el primer caso de uso que demuestra, con métricas claras, el valor de cruzar la Línea Nadella. Es el caso donde la diferencia entre el Mundo Agéntico y el Mundo Agentivo deja de ser abstracción y se vuelve experimentable: una pregunta que tomaba semanas en producir respuesta, en el Mundo Agentivo toma segundos. La transformación no es cuantitativa solamente — es cualitativa: cuando preguntar es gratis, las organizaciones descubren que pueden preguntar cosas que antes no se hacían, y descubren que las preguntas no formuladas contenían los insights más valiosos.
Una arquitectura formal queda incompleta sin un caso canónico que la demuestre. Para la Arquitectura Agentiva, ese caso es el acceso a información analítica — el problema más cotidiano y mejor entendido de la operación empresarial moderna. Tres razones hacen al caso fundacional para el libro.
La primera razón es que es universal. Toda organización que opera con datos enfrenta el problema de convertir datos en decisiones. La BI conversacional aplica a finanzas, operaciones, ventas, marketing, recursos humanos — sin distinción. No importa el sector, no importa el tamaño, no importa la geografía: el problema existe en todas partes y tiene forma similar.
La segunda razón es que tiene métrica clara. El valor se mide en tiempo: cuánto tarda una pregunta de negocio en convertirse en respuesta accionable. La diferencia entre semanas y segundos no requiere argumento — es directamente perceptible. Cuando un ejecutivo experimenta por primera vez una pregunta nueva respondida en segundos en lugar de semanas, la diferencia se vuelve preferencia adquirida sin necesidad de venta.
La tercera razón es que construye sobre arquitectura existente. La metodología Kimball — el estándar canónico de data warehousing desde 1996 — sigue siendo válida. Lo que cambia es el propósito del modelo: pasa de ser contenedor de reportes a ser activo estratégico sobre el cual los agentes razonan. Esta propiedad — que no exige descartar la inversión existente sino capitalizarla — es lo que hace al caso adoptable. Una organización con data warehouse maduro no necesita reescribir su infraestructura; necesita agregar la capa agentiva por encima.
El valor agentivo no se demuestra reemplazando lo que ya funciona. Se demuestra haciendo que lo que ya funciona produzca resultados a velocidades que antes eran imposibles.
El problema histórico
El acceso a conocimiento analítico ha sido históricamente lento porque cada pregunta nueva requiere un proyecto. La secuencia es conocida y dolorosa, y captura exactamente el problema que la BI conversacional resuelve.
El ejecutivo formula la pregunta a su área de BI. La pregunta puede ser tan simple como “¿por qué cayeron los márgenes en el segmento corporativo el mes pasado?” o tan compleja como “¿qué clientes tienen patrones de uso similar a los que cancelaron en los últimos seis meses?”. En ambos casos, la pregunta tiene que ser interpretada por humanos del área de BI, traducida a especificación técnica, asignada a un desarrollador, construida como reporte o dashboard, validada con el ejecutivo, ajustada según feedback, y finalmente entregada.
La secuencia tiene cuatro fases típicas: coordinación (días para programar reuniones y alinear expectativas), levantamiento (días para entender la pregunta y especificar los datos requeridos), desarrollo (semanas para construir el reporte), validación (días para revisar y ajustar). El proceso completo toma típicamente entre cuatro y doce semanas. Y aún así, lo que se entrega es un reporte específico que responde la pregunta original — no es capacidad reutilizable para preguntas relacionadas que el ejecutivo se hará después.
El cuello de botella real es el que el diagnóstico del Capítulo 2 nombró: humanos en el medio, cada uno agregando latencia y margen de malinterpretación. El ejecutivo formula la pregunta de manera ambigua porque está pensándola en voz alta; el analista interpreta la ambigüedad de un modo; el desarrollador implementa otra interpretación. Cuando el reporte llega, el ejecutivo descubre que no es exactamente lo que necesitaba, y el ciclo recomienza.
El costo de poner el modelo tradicional en operación tampoco es trivial. Construir la cadena Data Lake → Synapse → Power BI, o cualquier equivalente moderno, requiere típicamente entre cien mil y quinientos mil dólares de setup inicial, entre diez mil y cincuenta mil dólares mensuales de operación, y un tiempo a primer dashboard útil de entre tres y seis meses. Y toda esa inversión entrega capacidad de responder solo aquellas preguntas que alguien previó al diseñar el sistema. Para la pregunta no anticipada — la intuición nueva del lunes — vale el diagnóstico del Capítulo 2: fuera del menú, a la cola o al olvido.
La industria de BI consolidada reconoce abiertamente que el modelo llegó a su techo — el Capítulo 2 citó las voces (Tellius, Superwise, Cube, Tableau, BCG) y no las repetiremos. La sustancia del reconocimiento importa más que sus citas: quince años de rediseños cosméticos — dashboards más bonitos, self-service para usuarios no-técnicos, NLP sobre datos pre-modelados — prometieron democratizar el acceso al conocimiento y entregaron mejoras incrementales, porque el problema nunca fue cosmético sino estructural. El cuello de botella era el humano en el medio, y ningún rediseño podía eliminarlo sin reemplazarlo con algo equivalentemente capaz.
La solución agentiva

Con la Arquitectura Agentiva implementada sobre los datos de la organización, el ejecutivo conversa directamente con un agente que tiene acceso a esos datos. La secuencia que en el modelo tradicional tomaba cuatro a doce semanas se colapsa en una operación de segundos. La pregunta llega al agente, el agente la procesa, ejecuta dinámicamente la consulta sobre los datos, devuelve la respuesta. Si el ejecutivo quiere refinar — “y ahora muéstrame solo el segmento corporativo” —, el agente refina en la siguiente respuesta. Si quiere profundizar — “¿qué cambió específicamente en septiembre?” —, el agente profundiza. La conversación reemplaza al proyecto.
La diferencia es estructural. Los pasos intermedios — coordinación, levantamiento, desarrollo, validación — desaparecen porque el agente los ejecuta dinámicamente en cada pregunta. El humano que tenía que ser intermediario sale del medio. Y como el agente puede responder cualquier pregunta, no solo las pre-construidas, el ejecutivo no necesita “pedir un nuevo reporte” cada vez que tiene una intuición nueva. La capacidad analítica está disponible para cualquier pregunta sobre los datos disponibles.
El cambio cuantitativo es radical. La métrica de tiempo a respuesta pasa de cuatro a doce semanas en el modelo tradicional, a cinco a sesenta segundos en el modelo agentivo. La diferencia es de tres órdenes de magnitud — no es mejora, es transformación.
Cuando el costo de una pregunta colapsa de semanas a segundos, cambia la naturaleza de la relación entre la organización y su información. Los tres efectos que el Capítulo 2 ya describió se materializan en el caso del conocimiento en tiempo real. La capacidad analítica se vuelve elástica — se adapta a la necesidad actual, no a lo que alguien pre-definió hace meses. La iteración reemplaza a la especificación — el ejecutivo explora, refina, profundiza en una conversación continua con la información, en lugar de definir requerimientos por adelantado y esperar el resultado. Y las preguntas que nunca se hacían, ahora se hacen — cuando preguntar es gratis, la curiosidad analítica deja de estar limitada por el presupuesto de BI.
El cambio más importante no es la velocidad. Es la libertad cognitiva del ejecutivo, que deja de tener que elegir qué preguntar.
El tiempo real como temporalidad continua
Conviene precisar qué es exactamente el “tiempo real” de este caso —
el estado al otro lado del Salto Cuántico que el Capítulo 2 acuñó. No es
un canal de entrega ni un atributo de la pregunta: es la
temporalidad del Botlet que sostiene la manifestación
informativa. Aplicado a la BI, un reporte (snapshot
punto-en-tiempo) es el Botlet con temporalidad discreta, y un
dashboard vivo es el mismo Producto de Información
(PI) con temporalidad continua, sostenido sobre un runtime
persistente de Capa 3. El “tiempo real” del caso BI no se elige marcando
un modo de entrega: se elige dándole al Botlet temporalidad continua. La
especificación de temporalidad — los dos regímenes y el único runtime
que los unifica — vive en el Capítulo 5 §2.
El PI que esta aplicación canónica entrega puede,
además, componerse de múltiples vistas nombradas con navegación
por contexto (drill-through). Su descripción normada —
multi-vista, la propiedad data-anchored / no-bypass — vive en el
Capítulo 5 §2; aquí basta señalar que esa composición es ortogonal a la
temporalidad: aplica igual a un snapshot que a un dashboard vivo.
Hay que ser preciso sobre qué cambia y qué no. El modelo Kimball no desaparece. El agente lo ejecuta dinámicamente — no lo reemplaza. La metodología, los conceptos (hechos, dimensiones, conformed dimensions, slowly changing dimensions), las prácticas profesionales del data warehousing siguen siendo el sustrato. Los data warehouses no desaparecen. Siguen siendo donde los datos están almacenados, modelados y gobernados. Lo que cambia es quién los consume: deja de ser solo el dashboard humano; pasa a ser también el agente. Los analistas y CIOs de datos no desaparecen. Su trabajo se desplaza: pasan de construir dashboards específicos a diseñar la capa semántica sobre la cual los agentes razonan correctamente. Es trabajo más estratégico, menos operativo.
La arquitectura subyacente — Kimball Barnizada

La metodología Kimball, formulada por Ralph Kimball en The Data Warehouse Toolkit (1996), sigue siendo el estándar vendor-neutral para modelado dimensional. Su validez no caduca — su propósito evoluciona. A esta evolución la llamamos Kimball Barnizada: preserva la estructura conceptual de Kimball — Source, ETL, Presentation, BI Apps, más Metadata transversal — y le agrega un acabado contemporáneo que refleja el cambio de propósito del modelo de datos.
Los componentes canónicos de Kimball clásico son cinco. Source son los sistemas operacionales: ERPs, CRMs, sistemas transaccionales que generan los datos en su forma cruda. ETL es el proceso de extract-transform-load: limpieza, conformidad, transformación de los datos desde su forma operacional a su forma analítica. Presentation son los data marts: hechos y dimensiones, conformed dimensions que permiten consistencia inter-marts. BI Apps son los dashboards, reportes, herramientas de exploración interactiva — la superficie con la cual el humano consulta los datos. Metadata atraviesa todo: gobernanza, calidad, lineage.
La arquitectura clásica funciona para la era pre-agentiva. Sirve para que humanos consulten datos vía dashboards. No sirve, por sí sola, para que agentes consulten datos para razonar autónomamente. La razón no es que el modelo Kimball esté mal — es que está incompleto para el caso agentivo. Le falta la capa que traduce el modelo en algo que el agente entiende.
Sobre la estructura clásica de Kimball se monta una capa contemporánea que sirve a los agentes. La primera componente es la capa semántica explícita: un knowledge graph o capa semántica equivalente que codifica el significado de las dimensiones, las relaciones, las reglas de negocio. La capa semántica es lo que el agente consulta antes de generar consultas SQL — sin ella, el agente alucina. La segunda componente es el Trust Score por dato: métrica de confiabilidad de cada dato basada en linaje, calidad, governance y observabilidad. Componente del modelo de datos como activo estratégico. La tercera componente es la AI Certification: proceso automatizado de verificación de madurez y readiness de los modelos analíticos para ser consumidos por agentes. Aborda requisitos de NIST AI RMF, ISO/IEC 42001, EU AI Act. La cuarta componente es la observabilidad de queries agentivos: monitoreo de las consultas que los agentes ejecutan: cuáles, con qué frecuencia, con qué éxito. Permite identificar gaps en la capa semántica.
La estructura completa de Kimball Barnizada es la que sintetiza la figura anterior.
El cambio más importante de la arquitectura: el modelo de datos pasa de ser contenedor de reportes a ser activo estratégico. Esto significa que la calidad del dato deja de medirse por su limpieza y pasa a medirse por su accionabilidad por agentes — un dato bien limpiado pero sin contexto semántico es inservible para un agente, mientras que un dato algo sucio pero rico en contexto puede ser utilísimo. Significa que la gobernanza pasa de ad hoc a certificada. Significa que el modelado se dirige por las preguntas que los agentes harán, no por los reportes esperados.
La medición de AtScale que el Capítulo 2 citó — más del ochenta por ciento de fallo sin capa semántica; precisión cercana al cien por cien con ella — es el sustento cuantitativo de esta primera componente. Y los términos que la industria acuñó para la capa — el Agentic Semantic Layer de ThoughtSpot, el Enterprise Knowledge Graph de Salesforce, el Agentic BI de Databricks — son ángulos del mismo diagnóstico: el agente necesita mucho más que datos; necesita significado asociado a los datos.
Mapeo a los hyperscalers
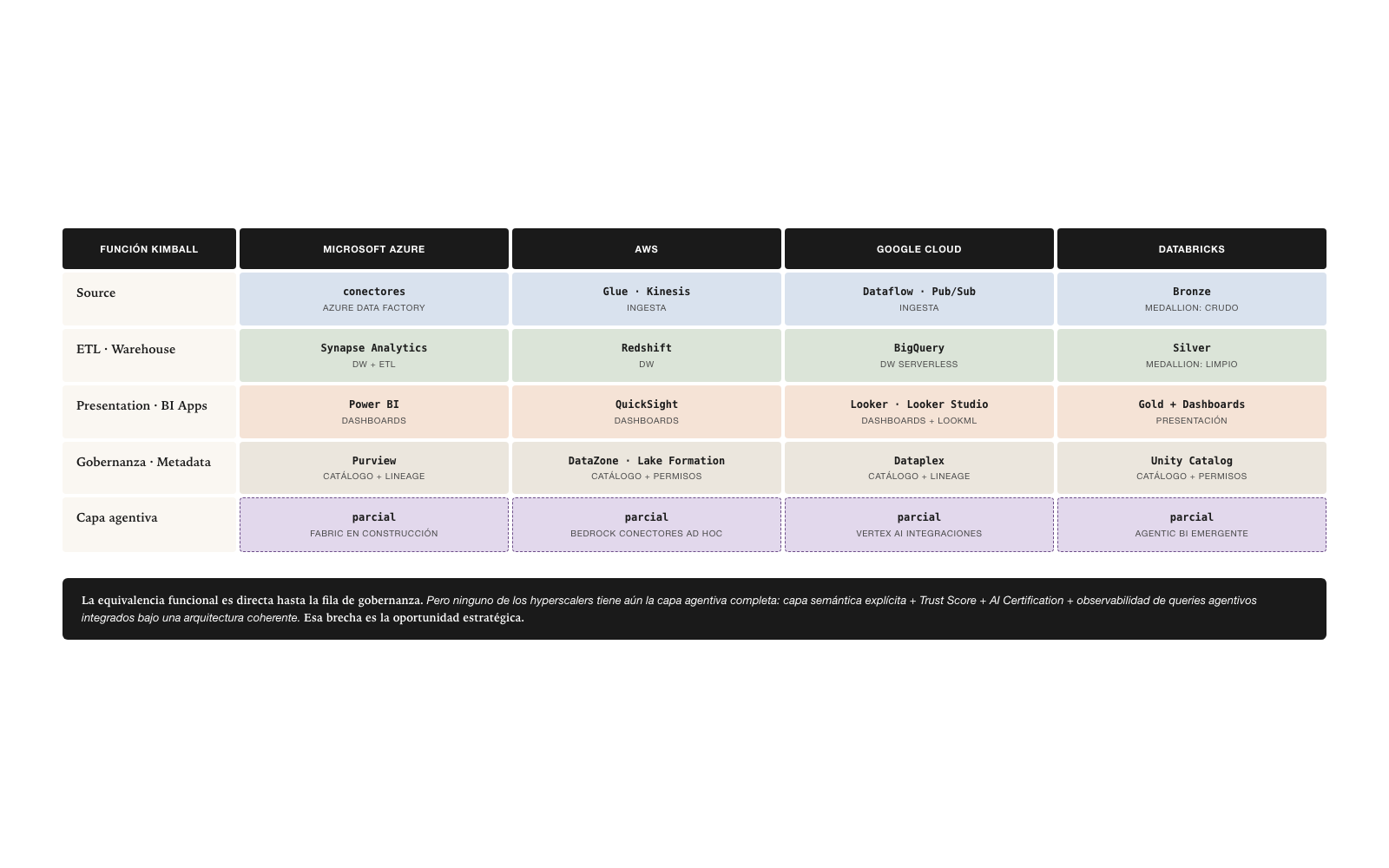
Cada hyperscaler implementa Kimball base bajo su propia terminología, lo que confunde a quien intenta navegar el mercado por primera vez. La equivalencia funcional, sin embargo, es directa.
Microsoft Azure implementa Kimball con Synapse Analytics como ETL y warehouse, Power BI como BI App, Purview como gobernanza, y Fabric como capa unificadora. AWS implementa con Redshift como warehouse, QuickSight como BI App, DataZone como gobernanza, Lake Formation como capa de datos. Google Cloud implementa con BigQuery como warehouse, Looker como BI App, Dataplex como gobernanza. Databricks implementa con Lakehouse usando Medallion Architecture (Bronze/Silver/Gold) como ETL y warehouse, y Unity Catalog como gobernanza.
La Medallion Architecture de Databricks merece nota especial: es implementación moderna de Kimball sobre lakehouse. Bronze corresponde a Source — datos crudos. Silver corresponde a ETL transformado — datos limpios y conformes. Gold corresponde a Presentation — datos listos para consumo. La nomenclatura es nueva pero el concepto es Kimball clásico aplicado a lakehouse.
Ningún hyperscaler tiene aún implementación completa de la capa agentiva del Kimball Barnizada. La capa semántica explícita, el Trust Score por dato, la AI Certification, la observabilidad de queries agentivos — son piezas que cada hyperscaler está agregando gradualmente, pero ninguno tiene oferta integrada completa. Quest/erwin es uno de los pocos vendors que productiza el modelo extendido completo bajo el concepto “Model to Marketplace” — pero como producto especializado, no como parte del stack de un hyperscaler.
Esta brecha es oportunidad estratégica: el actor que entregue Kimball Barnizada completo, integrado bajo una sola arquitectura coherente, captura el espacio que actualmente ningún actor cubre completamente.
El consenso de la industria
Diez actores convergen — desde ángulos distintos — en la misma visión de BI conversacional sobre arquitectura Kimball: Tableau, Cube, Tellius, ThoughtSpot, Salesforce, AtScale, Databricks, Informatica, eWeek y Gartner, cuyas formulaciones ya recorrieron este capítulo y el Capítulo 2. La lista deja claro que no es propuesta aislada de un actor — es consenso emergente del campo.
El patrón común es claro. La industria convencional reconoce que la BI tradicional debe extenderse con capacidad agentiva. La diferencia entre los actores está en cuán explícitamente se integra la arquitectura. Los actores que tratan la BI agentiva como feature suelto producen soluciones limitadas; los actores que la tratan como rediseño arquitectónico de la capa de datos producen soluciones que pueden sostenerse en producción.
¿Cómo se implementa el caso canónico?
Para una organización que tiene arquitectura Kimball razonable y desea agregar capacidad agentiva, la ruta de implementación sigue un patrón recurrente.
La etapa uno es construir o adquirir una capa semántica explícita que codifique el significado de las dimensiones, hechos, jerarquías y reglas de negocio. Sin esta capa, los agentes alucinan o producen consultas incorrectas. La organización tiene varias opciones de producto: AtScale como producto especializado, dbt Semantic Layer como capa que se integra al modelado dbt, Cube como producto con énfasis en performance, LookML como capa semántica de Looker para casos donde Looker ya es BI tool. La elección depende del stack existente y de las preferencias arquitectónicas. Lo crítico no es qué producto se elige — es construir la capa con disciplina.
La etapa dos es construir o configurar un agente con acceso a la capa semántica. El agente no genera SQL directamente — genera consultas semánticas que la capa semántica traduce a SQL correcto. Esto es lo que distingue a una BI conversacional robusta de una “demo de chatbot sobre data warehouse”. El agente que genera SQL directamente alucina con frecuencia; el agente que opera sobre capa semántica con contratos claros mantiene precisión alta.
La etapa tres es aplicar Trust Infrastructure sobre el agente. Los cinco pilares — Gobernanza, Auditoría, Validación, Resiliencia, Transparencia — sobre el agente conversacional. Gobernanza define qué datos puede consultar, quién puede preguntar qué. Auditoría registra cada consulta y cada respuesta. Validación detecta especialmente alucinaciones financieras o de KPIs — categoría de error particularmente grave en BI conversacional. Resiliencia ante fallos de la capa semántica. Transparencia de qué tools invocó el agente para producir cada respuesta.
La etapa cuatro es onboarding gradual. Empezar con un dominio de datos limitado — finanzas, ventas, o uno específico — donde la calidad del modelo es alta y los usuarios son sofisticados. Expandir a más dominios solo después de validar que el agente entrega valor sin alucinar. La paciencia es clave — saturar todos los datos de la organización al agente desde el inicio garantiza que los primeros usuarios pierdan confianza por respuestas incorrectas. El proyecto tiene que ganar credibilidad antes de expandirse.
La etapa cinco es evolución a empresa en tiempo real. Una vez que el agente responde preguntas correctamente sobre datos históricos, evolucionar hacia que actúe sobre los datos: alertas proactivas cuando detecta anomalías, ejecución de procesos correctivos automáticos dentro de límites gobernados, escalación al humano para decisiones sobre umbral. Es la transición de empresa en línea a empresa en tiempo real descrita en el Capítulo 2. Esta etapa es donde el sistema agentivo pasa de ser mejor BI a ser operación autónoma.
¿Por qué este caso vale como aplicación canónica?
Las tres razones que abrieron este capítulo — universal, con métrica clara, construido sobre arquitectura existente — explican por qué el caso es fundacional. El cierre pide un ángulo distinto: lo que este caso hace por los demás.
El acceso a información en tiempo real es condición habilitante del resto de la transformación agentiva. Sin él, los agentes que actúan en otros dominios — operaciones, ventas, atención al cliente — carecen de fundamento informativo. Por eso este caso aparece típicamente como el primero en la trayectoria de adopción de la Arquitectura Agentiva por parte de organizaciones serias. Las organizaciones que intentan saltarse el caso del conocimiento en tiempo real para ir directamente a casos de operación autónoma típicamente fracasan — sin la base de información en tiempo real, los agentes operacionales operan a ciegas.
Y como construye sobre lo que ya existe, es también el caso de menor barrera: una organización puede ganar su primera experiencia agentiva — la pregunta respondida en segundos que convierte el escepticismo en demanda — sin comprometer presupuesto de transformación masiva. Esa primera experiencia es la que abre la puerta de los dominios siguientes.
Quien resuelve el conocimiento en tiempo real, gana el derecho de plantear los demás casos. Quien no, opera en piloto perpetuo.